map
- 将RDD中的元素按照指定的函数规则一 一映射,形成新的RDD。
函数签名
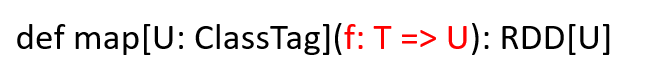
代码示例
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5),2)
val newRDD: RDD[Int] = rdd.map(_*2)
newRDD.collect().foreach(println)
sc.stop()
mapPartitions
- 以分区为单位对RDD中的元素按照指定函数规则进行映射。
函数签名

代码示例
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val newRDD: RDD[Int] = rdd.mapPartitions(datas => {
datas.map(_ * 2)
})
newRDD.foreach(println)
sc.stop()
mapPartitionsWithIndex
函数签名

代码示例
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8), 4)
val newRDD: RDD[Int] = rdd.mapPartitionsWithIndex {
(index, datas) => {
index match {
case 1 => datas.map(_ * 2)
case _ => datas
}
}
}
newRDD.collect().foreach(println)
sc.stop()
三者的区别
- map每次处理一条数据。
- mapPartitions每次处理一个分区的数据,只有当前分区的数据处理完毕后,原RDD分区中的数据才会释放,有可能导致OOM。
- mapPartitionsWithIndex每次处理一个分区的数据,同mapPartitions,但是不同的是,mapPartitionsWithIndex带有原RDD分区编号,当我们想要只处理某一个分区的数据时,可以使用此算子。
使用场景
- mapPartitons适合在空间内存较大的情况下或者频繁连接数据库时使用,以提高处理效率。
- map适用于内存较小的情况。
- mapPartitionsWithIndex同mapPartitions,但是可以更加方便的操作指定分区的数据。