之前很长的一段时间内,一直在做阿里云人工智能产品 ET,
做为了一名前端工程师,参与了当中的一些工程工作,分享出来,希望对大家有所帮助。
前端工程在人工智能的团队到底能做什么,体现怎么的价值?对此,可以先下图的一个总结,然后我会逐条分析

从我们的实践看,要完成一个完整的人工智能项目,三种东西是不可或缺的:算法,数据和工程。
而前端在这三个方向种,最容易参与进去,同时也最容易做出彩的地方就是在工程方面,我们把这块内容叫做大前端。
具体的大致可以分为五块内容:人机交互,数据可视化,产品Web, 计算,模型训练和算法执行。
对于前三点偏重交互的领域,毋庸置疑用前端做起来驾轻就熟,
而后面偏重计算的领域,前端是否合适做,或者说前端该怎么去做是有可以探讨的。

一.人机机互:
这个应该前端这几年重点发力,而且取得不错进展的地方。
特别是随着HTML5技术和移动互联网的普及,浏览器对PC和手机硬件的控制越来越好。
在AI的项目中,很多时候需要获取麦克风和摄像头的权限,好实现“听”,“说”, “看”的功能。
具体大家可以参考H5中的MediaDevices.getUserMedia 文档,里面对这块有详细的介绍。
其他,对于图片的处理,之前网上已经不少的用Canvas例子,我就不做过多的介绍。
这里重点对语音处理的内容,这块由于需要很多专业方面的知识,之前处理前端处理起来还是挺痛苦的,
不过现在Web Audio API 很好的解决了这个问题。
它提供了在Web上控制音频的一个非常有效通用的系统,允许开发者来自选音频源,对音频添加特效,使音频可视化,添加空间效果 等等。
更有甚者,Chrome中已经自动集成了语音识别的基础SDK

二. 数据可视化
数据可视化 可以是前几年特别火的一个方向,特别是大数据风起云涌的时候
而这些年明显的趋势就是人工智能,就是AI,在这里其实也有很多可视化的工作
比如我们在 ET 项目中就需要做很多声音的可视化

以及现在外面在做的一些人脸可视化的内容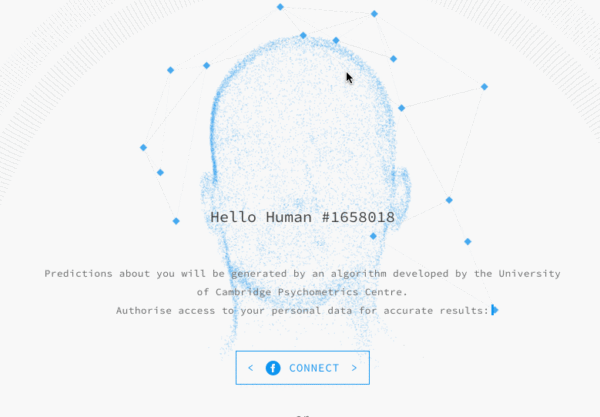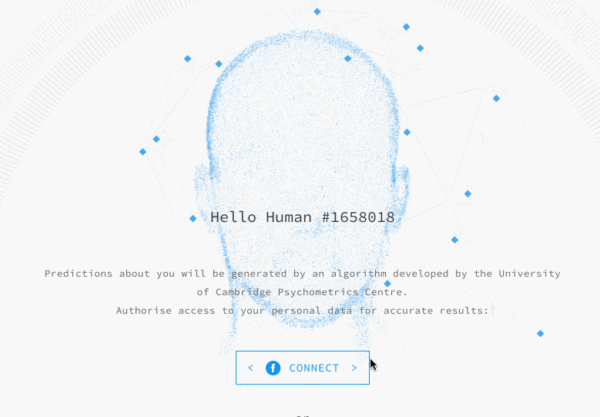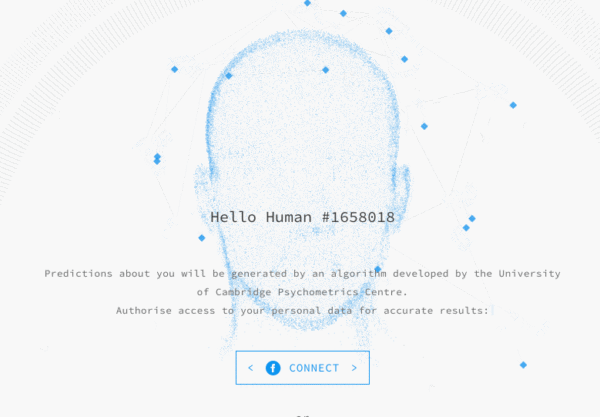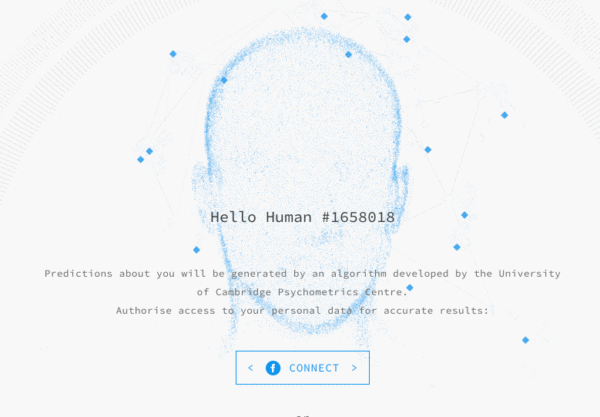
地址:PREDICTIVE_WORLD, the program that predicts your future/
三. 产品Web
任何人工智能的技术最终一定需要转化成实际的产品或者项目,这样的话,往往少不了Portal和控制台。
这些工作,前端的工作也是在所难免。
四. 算法执行
算法执行顾名思义,其实就是执行算法逻辑,比如人脸识别,语音识别 …
前几年有些大家对前端的认知还挺溜在纯浏览器端,但随着 V8 引擎在2008 年发布, Node.js 在2009 年 发布,前端的领地就扩展到服务器端,桌面应用。
这些算法执行的原先需要后端同学开发的,现在也可以由前端同学才做。
我们很多AI的项目,很多时候往往就是算法的同学提供给我们一些动态链接库或者C的代码,我们通过Nodejs驱动这些服务提供 http接口,浏览器通过ajax来调用这些接口。
更有甚者,现在PC性能体能,V8对JS执行的优化,特别WebGL 在各个浏览器端的普及
很多算法执行不一定并不一定需要在后端执行,浏览器也可以胜任。
比如:
Tranck.js :就是纯浏览器的图像算法库,通过javascript计算来执行算法逻辑
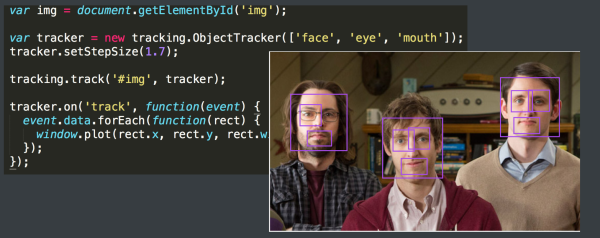
regl-cnn: 浏览器端的数字识别类库,与track.js 不同的是,它利用浏览器的WebGL 才操作GPU, 实现了CNN

五. 模型训练
虽然现在阶段也出现了像 ConvNetJS 这种在浏览器端做深度学习算法训练的工具,
但整理来讲,前端在这块还是非常欠缺的,缺少非常成功的实践。
究其原因,还是因为跨了领域,而且基础的专业类库往往都不是javascript写的,造成更大的隔阂
但就像谷歌的TensorFlow机器学习框架底层大部分使用 C++实现,但选择了 Python 作为应用层的编程语言。
Javascript 在各个端,特别是web端的优势,也是一门非常优秀的应用开发预发。
可喜的是看到挺多同学在往这个方向走,我们拭目以待
ConvNetJS:Deep Learning in your browser