T1:均分纸牌
考察知识:贪心,模拟
算法难度:XX 实现难度:XX
分析:
此题有很多解法,下面介绍我的算法步骤:(具体请参见代码)
0.定义pos表示已经处理好的部分(从左往右),pos初始值为0
1.从左往右(i=1 to n)扫描,并统计sum=sum+a[i]
2.一旦sum除以i-pos大于平均值,cnt+=(i-pos-1),并修改pos=i,sum=sum-ave*(i-pos)
如果sum不等于0则cnt++
3.重复1.2.直到i>n
为什么这个算法是正确的呢,这需要我们严密证明:
参考证明思路:
0.证明这种算法是最优的(用贪心证明)
1.先证明当达到sum/(i-pos)>aver时将pos+1~i牌数均调为aver最少操作次数为i-pos-1
2.显然如果此时牌没有用完则必须向右移,所以有cnt++
代码:
#include<cstdio>
using namespace std;
int n,a[105],aver=0;
int sum,pos;
int main(){
int cnt=0;
scanf("%d",&n);
for(int i=1;i<=n;i++) scanf("%d",a+i),aver+=a[i];
aver/=n;
for(int i=1;i<=n;i++){
sum+=a[i];
if(sum>=(i-pos)*aver){
cnt+=(i-pos-1);//把pos+1~i的牌处理好需要的最少操作数
sum-=aver*(i-pos);//把处理好的牌删除掉
if(sum) cnt++;//牌没有用完则必定需要向右移
pos=i;
}
}
printf("%d\n",cnt);
return 0;
}T2:字串变换
考察知识:bfs,dfs,搜索的优化,字符串
算法难度:XX 实现难度:XXX
方法一:dfs
对于这道题我首先写了一个dfs暴力程序60->80分,最后一个点要跑近150s,我当时就震惊了,我当然知道要超时,但没有想到超时这么严重
然后我搬出了早已想好的dfs优化,瞬间快了几百倍,1s以内(208ms)就可以出答案了,下面介绍优化后的dfs:
dfs双端搜索:就是从起点终点两边同时搜索,到中途相遇
1.我们先搜索字符串A不断变化五步之内可以达到的所有状态的最小步数,并存入map<string,int>中(如果你非要设身处地,坚持在NOIP不能用STL的年份的NOIP题不用STL,那么你就用字符串hash吧,建议使用双hash减少冲突系数)
2.在反向搜索,搜索字符串B在5步之内可以达到的所有状态的最小步数,如果map中有,ans=min(ans,cur+mp[str])
3.判断并输出答案
细节见代码:
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<string>
#include<map>
using namespace std;
map<string,int>mp;
char A[25],B[25],Aa[250],a[10][25],b[10][25];
int n,ans=100,len[10][2];
void dfs1(int cur,char Aa[]){
string stri=Aa;
if(!mp.count(stri)) mp[stri]=cur;
else mp[stri]=min(mp[stri],cur);
char tmp[250];//注意防中间字符串爆数组
int L=strlen(Aa);
if(cur>5||cur>=ans) return;
//如果直接到达B状态:
if(strcmp(B,Aa)==0) {ans=min(ans,cur);return;}
for(int i=0;i<L;i++)
for(int j=0;j<n;j++) if(i+len[j][0]<=L){
strcpy(tmp,Aa+i);
tmp[len[j][0]]='\0';
if(strcmp(a[j],tmp)==0){//字符串替换,重点
strcpy(tmp,Aa);
strcpy(tmp+i,b[j]);
strcpy(tmp+i+len[j][1],Aa+i+len[j][0]);
dfs1(cur+1,tmp);
}
}
}
void dfs2(int cur,char Aa[]){
string stri=Aa;
//如果正向搜索已经到达该状态:
if(mp.count(stri)){ans=min(ans,mp[stri]+cur);return;}
char tmp[250];
int L=strlen(Aa);
if(cur>5||cur>=ans) return;
for(int i=0;i<L;i++)
for(int j=0;j<n;j++) if(i+len[j][1]<=L){
strcpy(tmp,Aa+i);
tmp[len[j][1]]='\0';
if(strcmp(b[j],tmp)==0){
strcpy(tmp,Aa);
strcpy(tmp+i,a[j]);
strcpy(tmp+i+len[j][0],Aa+i+len[j][1]);
dfs2(cur+1,tmp);
}
}
}
int main(){
scanf("%s%s",A,B);
for(n=0;scanf("%s%s",a[n],b[n])==2;n++);
for(int i=0;i<n;i++) len[i][0]=strlen(a[i]),len[i][1]=strlen(b[i]);
strcpy(Aa,A);//正向搜索
dfs1(0,Aa);
strcpy(Aa,B);//反向搜索
dfs2(0,Aa);
if(ans<=10) printf("%d\n",ans);
else printf("NO ANSWER!\n");
return 0;
}方法二:bfs搜索
对于这道题,bfs搜索应该优于dfs(速度快得多),仅用单向搜索就可以AC,当然你也可以(动态)双向搜索
代码:
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<string>
#include<map>
#include<queue>
using namespace std;
struct node{
char tmp[210];
int cur;
};
map<string,int>mp;
char A[25],B[25],Aa[250],a[10][25],b[10][25];
int n,ans=100,len[10][2];
void bfs(){
string stri;
char tmp[210],Aa[210];//注意防中间字符串爆数组
queue<node>q;
node T,TT;
strcpy(T.tmp,A);
T.cur=0;
q.push(T);
while(!q.empty()){
T=q.front();q.pop();
strcpy(Aa,T.tmp);
stri=Aa;
if(mp.count(stri)) continue;//判重
else mp[stri]=1;
if(strcmp(Aa,B)==0||T.cur>10) {ans=T.cur;return;}
int L=strlen(Aa);
for(int i=0;i<L;i++)
for(int j=0;j<n;j++) if(i+len[j][0]<=L){
strcpy(tmp,Aa+i);
tmp[len[j][0]]='\0';
if(strcmp(a[j],tmp)==0){//字符串替换,重点
strcpy(tmp,Aa);
strcpy(tmp+i,b[j]);
strcpy(tmp+i+len[j][1],Aa+i+len[j][0]);
strcpy(TT.tmp,tmp);
TT.cur=T.cur+1;
q.push(TT);
}
}
}
}
int main(){
scanf("%s%s",A,B);
for(n=0;scanf("%s%s",a[n],b[n])==2;n++);
for(int i=0;i<n;i++) len[i][0]=strlen(a[i]),len[i][1]=strlen(b[i]);
bfs();
if(ans<=10) printf("%d\n",ans);
else printf("NO ANSWER!\n");
return 0;
}T3:自由落体
考察知识:数学(物理)分析
算法难度:XX+ 实现难度:XX+
tips:+相当于0.5个X
用一点高中数学或物理分析就可以了,如图:(部分字母与原题不一致)

接下来就是判断两条线段(把时间区间看成线段)是否相交了
具体细节看代码:
#include<iostream>
#include<cstdio>
#include<cmath>
using namespace std;
const double eps=0.0001;
double h,s,v,l,k;
int n,ans;
int main(){
int cnt=0;
double a,b,c,d;
scanf("%lf%lf%lf%lf%lf%d",&h,&s,&v,&l,&k,&n);
for(int i=0;i<n;i++){
a=(s-i-eps)/v,b=(s-i+l+eps)/v;//处理精度误差
c=sqrt((h-k)/5.0),d=sqrt(h/5.0);
if((c<=a&&a<=d)||(c<=b&&b<=d)||(a<=c&&c<=b)||(a<=d&&d<=b))
cnt++;
}
printf("%d\n",cnt);
return 0;
}上面是我自己的解法,我又看了别人的解法:换参考系,将木块视为静止,则小球可以看作平抛运动
看上去这个解法也挺不错的,请读者思考
T4:矩形覆盖
考察知识:搜索,计算几何,分治
算法难度:XXXX 实现难度:XXXX
其实只要你想到了方法,这道题也不是很难
分析:注意到k<=4我们可以分类讨论
1'.k=1(calc1)
显然最小面积为=(最大横坐标-最小横坐标)*(最大纵坐标-最小纵坐标)
2'.k=2(calc2)
考虑这两个矩形的位置关系:

我们可以把这些点划分为两个不同集合,而两个集合中点可以用图中方法覆盖
我们只需要考虑怎么划分集合然后调用calc1就可以了
3'.k=3(calc3)
考虑三个矩形位置关系:
同理,我们只需要考虑怎么划分点集,然后调用calc1,calc2就可以了
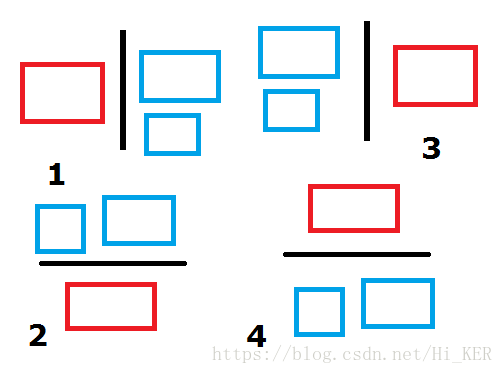
4'.k=4(calc4)
考虑四个矩形位置关系:

同calc3,我们只需要考虑怎么划分点集,然后调用calc1,calc2,calc3就可以了
那么,问题来了,我们怎么划分点集呢?
图中给出的是用一条线来划分,其实不然,我们应该考虑这些点怎么划分满足划分之后覆盖所有点集的矩形不相交
具体实现看代码:
(注意:代码中的memcpy是为了保证calcx在调用了比它低级的calc后仍然能保证点集有序)
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
using namespace std;
struct P{int x,y;}p[55];
//请仔细理解排序方式
bool cmpx(P A,P B){return A.x<B.y||(A.x==B.x&&A.y<B.y);}
bool cmpy(P A,P B){return A.y<B.y||(A.y==B.y&&A.x<B.x);}
int n,k;
int calc1(int L,int R){
if(R-L<1) return 0;
int l=p[L].x,r=p[L].x,u=p[L].y,d=p[L].y;//left,right,up,down
for(int i=L+1;i<=R;i++){
l=min(l,p[i].x),r=max(r,p[i].x);
d=min(d,p[i].y),u=max(u,p[i].y);
}
return (r-l)*(u-d);
}
int calc2(int L,int R){
if(R-L<2) return 0;
int ans=calc1(L,R);
sort(p+L,p+R+1,cmpx);
for(int div=L;div<R;div++)
ans=min(ans,calc1(L,div)+calc1(div+1,R));
sort(p+L,p+R+1,cmpy);
for(int div=L;div<R;div++)
ans=min(ans,calc1(L,div)+calc1(div+1,R));
return ans;
}
int calc3(int L,int R){
P pp[55];
if(R-L<3) return 0;
int ans=calc1(L,R);
sort(p+L,p+R+1,cmpx);
memcpy(pp,p,sizeof(p));
for(int div=L;div<R;div++){
ans=min(ans,calc1(L,div)+calc2(div+1,R));
memcpy(p,pp,sizeof(p));//调用了calc2会导致p[]乱序
ans=min(ans,calc2(L,div)+calc1(div+1,R));
memcpy(p,pp,sizeof(p));
}
sort(p+L,p+R+1,cmpy);
memcpy(pp,p,sizeof(p));
for(int div=L;div<R;div++){
ans=min(ans,calc1(L,div)+calc2(div+1,R));
memcpy(p,pp,sizeof(p));
ans=min(ans,calc2(L,div)+calc1(div+1,R));
memcpy(p,pp,sizeof(p));
}
return ans;
}
int calc4(int L,int R){
if(R-L<4) return 0;
P pp[55];
int ans=calc1(L,R);
sort(p+L,p+R+1,cmpx);
memcpy(pp,p,sizeof(p));
for(int div=L;div<R;div++){
ans=min(ans,calc1(L,div)+calc3(div+1,R));
memcpy(p,pp,sizeof(p));
ans=min(ans,calc3(L,div)+calc1(div+1,R));
memcpy(p,pp,sizeof(p));
ans=min(ans,calc2(L,div)+calc2(div+1,R));
memcpy(p,pp,sizeof(p));
}
sort(p+L,p+R+1,cmpy);
memcpy(pp,p,sizeof(p));
for(int div=L;div<R;div++){
ans=min(ans,calc1(L,div)+calc3(div+1,R));
memcpy(p,pp,sizeof(p));
ans=min(ans,calc3(L,div)+calc1(div+1,R));
memcpy(p,pp,sizeof(p));
ans=min(ans,calc2(L,div)+calc2(div+1,R));
memcpy(p,pp,sizeof(p));
}
return ans;
}
int main(){
scanf("%d%d",&n,&k);
for(int i=1;i<=n;i++) scanf("%d%d",&p[i].x,&p[i].y);
if(k==1) printf("%d\n",calc1(1,n));
else if(k==2) printf("%d\n",calc2(1,n));
else if(k==3) printf("%d\n",calc3(1,n));
else printf("%d\n",calc4(1,n));
return 0;
}从代码中我们可以看到,calc就是不断划分并调用比它低级的calc的过程,而calc1为终点,其实这就是分治的过程
个人总结:
100+60+100+100=360
T2:没有考虑搜索时的字符串会长度会超过20,导致RE