哈夫曼树也是最优二叉树,首先我们来看哈夫曼树的定义:给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
先再解释一下什么是带权路径的长度:设二叉树有n个叶子结点,每个叶子结点带有权值Wn,从根结点到每个叶子结点的长度,则每个叶子结点的带权路径长度之和就是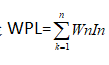
举个例子来说明下哈夫曼树要到底是要解决什么样的问题:比如对成绩进行等级划分

如果成绩低于60分grade就为1,60到69分之间grade=2,70到79之间grade=3,80到89之间grade=4,90分以上grade=5;按照这样的评价标准,每次读入一个学生的成绩后,就对这个成绩进行判断。这样的转换规则,可以用一棵判定树来表示:
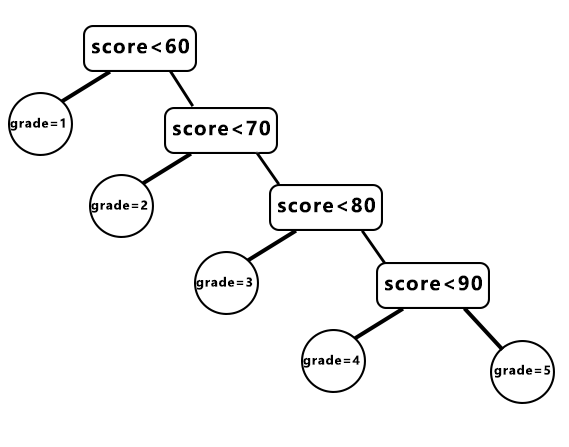
对于这么一棵判定树,如果读入了一个成绩是低于60分了,那么只需做一步判断就可以得到grade=1的结果。如果读入的分数是大于80且小于90,那么就要3步判断。如果分数大于90,那就要4步。
那么假设,一个班里的学生成绩,大部分都集中在80到90之间,而低于60分和高于90分的人比较少,那么大部分的成绩都要进行4步判断才能得出相应等级,所以这样的判定规则,效率可能并不是十分高。例如我们假设按照上面的规则来做成绩判断,然后按照下面的表格来录入成绩:
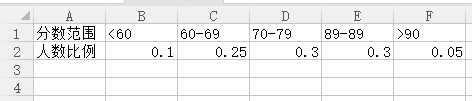
查找效率就为:0.1*1+0.25*2+0.3*3+0.3*4+0.05*4=2.9。
那么既然我们知道70-80和80-90这两个分数段所占的人数比较多,那么我们应该读入一个成绩后,先进行这两个分数段的判断,这样效率会不会更高?


按照这样的思路写出代码,也就是读入一个成绩后,先判断是否在70-79这个区间,然后到80-89,60-69,最后到60以下和90以上的区间。同样我们可以算下这样不同的一棵判定树的查找效率是等于:0.1*3+0.25*3+0.3*2+0.3*2+0.05*2=2.35。
这就说明一个问题,对于不同的搜索树或者叫判定树,查找效率是不同的,所以针对不同的问题不同的概率,我们都应该用效率最高的方法来实现。而哈夫曼树就是用来解决这个问题,找出效率最高的最优二叉树,也就是将带权路径的长度降到最小。
那么如何构建哈夫曼树?哈夫曼提出一种方法:
1、把权值从小到大排列。
2、在排完序的序列中找出两个权值最小的构建一个二叉树,这两个结点的父结点就是两个权值之和。
例如我们举个例子:对于下面一个序列,权值排序前是9 5 2 7 8。排序后是2 5 7 8 9。然后按照哈夫曼的方法,首先在这个排好序的序列中找出两个权值最小的组成一个二叉树,根结点为两个权值之和:
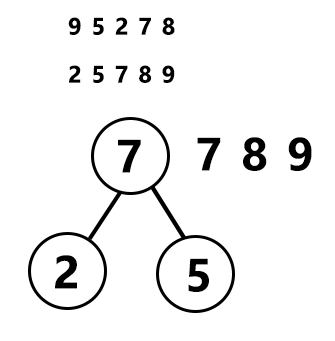
接着再从这个序列中(包括创建好的二叉树的根结点,这里是7 7 8 9)找两个权值最小(7,7)的构建二叉树。

一直循环,接下来到8和9。

最后是14和17。
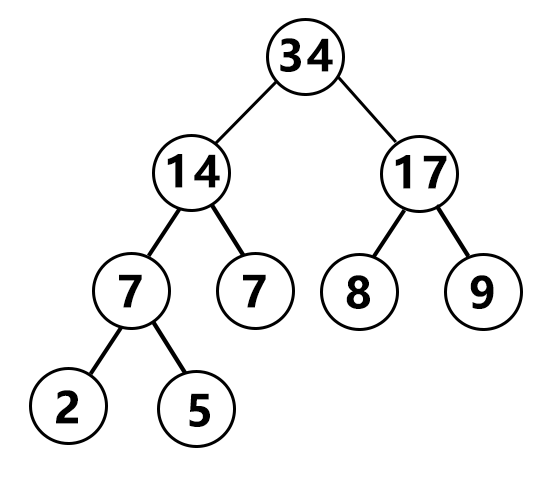
这样一棵哈夫曼树就创建成功了。按照这个思路,我们建立一棵哈夫曼树,就是每次从一个权值排好序的序列中找出两个最小结点来建树,我们可以利用堆,最小堆,每次从最小堆里抛出两个最小结点,然后把它们的权值相加,形成一个新的二叉树。

那么哈夫曼树的应用在哪些地方呢?比如编码,哈夫曼编码。通常我们的编码方式是整数用二进制的形式1和0来组合,计算机里用ASCII码来编码的话一个字符用8位,占7位,最高位是0。那么如果有100个文字,就要用700个字符。但是通常一段文字中,每个字符出现的频率是不一样的,有些常用文字出现的频率要更大一些,有些文字出现的频率低一些。所以为了让编码处理效率更高,我们可以让一些出现频率高的字符用3位或者4位来编码,而一些出现频率很低的字符,可以用6位甚至7位来编码。
假设我们有一段文字,里面有100个字符,由a、b、c、d、e、f、g、七个字符字符构成,这五个字符出现的次数,也就是频率不一样,那么如何对这7个字符进行编码,使得编码的总空间最少?
(1) 第一种方法是用等长的ASCII码编码:总编码空间:100*8=800(位);
(2) 第二种方法用等长3位编码:总编码空间:100*3=300(位);
对于这个问题,我们不需要用第一种方法全是8位来编码。我们一共用到7个字符来编码,所以2³=8,用3位来编码就可以表示出8个不同的对象了。而这里我们只用到了7个字符,所以3位来编码足够了。
更进一步的说,这7个字符a、b、c、d、e、f、g出现的频率也是不一样的,那么我们可以再根据这7个字符的使用频率来编出不等长的编码。
但是我们编码时要注意一个很重要的问题,就是编码不能出现二义性。例如字符的表示方法如下:
a:1
b:0
c:10
d:01
e:11
........
对于这样的编码,看起来可以,可是如果按照这样的编码,对于1101这个字符串,它表示的是怎样的一串字符呢?可以理解成是eba,也可以理解成是aaba,或者ed,aca都可以,这样就出问题了。所以为了避免出现二义性,要求每个字符的编码都不是另一个字符的前缀。也就是编码满足前缀码这样的条件:
前缀码(prefix code):任何字符的编码都不是另外一个字符的前缀。
满足这个条件就可以避免出现编码二义性的问题。例如上面的编码e用11来表示,a用1来表示,e的前缀码1可以理解成是a,这样a就成了e的前缀了。
讲了这么多,哈夫曼树的应用就是用来解决这一问题,哈夫曼编码可以避免出现这种编码的二义性。哈夫曼编码即用二叉树来编码:二叉树的左分支表示编码0,右分支表示编码1,且字符只在叶子结点上。
为什么要字符只在根结点上?因为这样才不会出现二义性。例如我们看这样的二叉树例子:
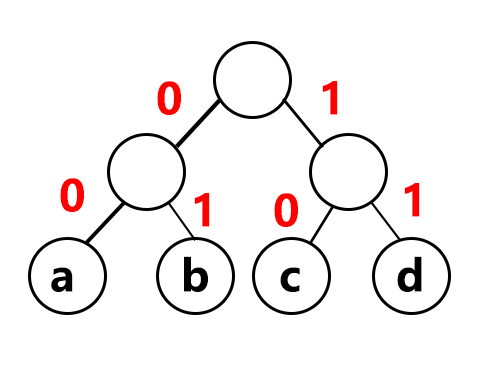
按照这样的编码方式,所有编码字符都在二叉树的叶子结点上,那么对应编码出来的a=00,b=01,c=10,d=11。
如果出现有字符不是在叶子结点上呢?

如图这样就会出现问题,a的编码是0,它可以是b和c的前缀。这样就会出现二义性,如果给出编码00,它是表示字符b,还是aa?所以只要字符出现在叶子结点上,就不会出现二义性的问题。
假设a、b、c、d四个字符的出现频率分别为a=5、b=3、c=1,d=2。用上面的二叉树来编码,我们看下需要的编码空间是:5*2+3*2+1*2+2*2=22。(2是字符的编码长度)这样我们可以看出,需要的编码空间也就是字符的频率*编码长度,用二叉树表示的话就是结点的路径*权值。总编码空间就是相当于所有路径*权值的和,要使得总编码空间最小,也就是带权路径的长度最小,这正是哈夫曼树解决的问题。所以我们就可以用构建哈夫曼树的方法来编码,这就是哈夫曼编码!
具体用一个例子来解释如何用构造哈夫曼树的方法来进行哈夫曼编码:
假设a、b、c、d、e五个字符的出现频率分别为a=5、b=3、c=1,d=2、e=4。频率就是看作字符的权值。
根据哈夫曼树的构造方法:
找出权值最小的两个字符,作为左右子树构造一个新的
二叉树,根结点的权值是这两个权值之和。
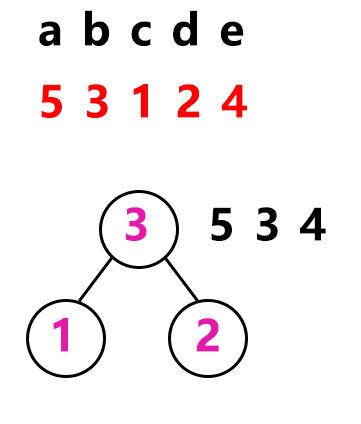
首先我们找出两个权值最小的1和2,构造一个二叉树,根结点的权值为1和2的和等于3。接着继续在序列中找出两个最小的权值继续构建二叉树,也就是从3 5 3 4中,选3和3来构建二叉树

接下来从6 5 4中选5和4:
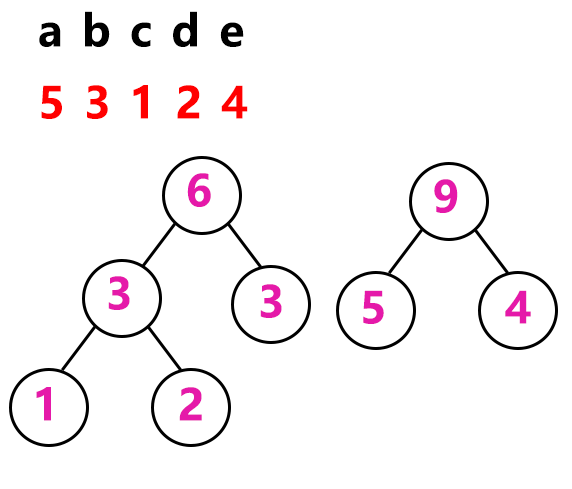
最后6和9结合:
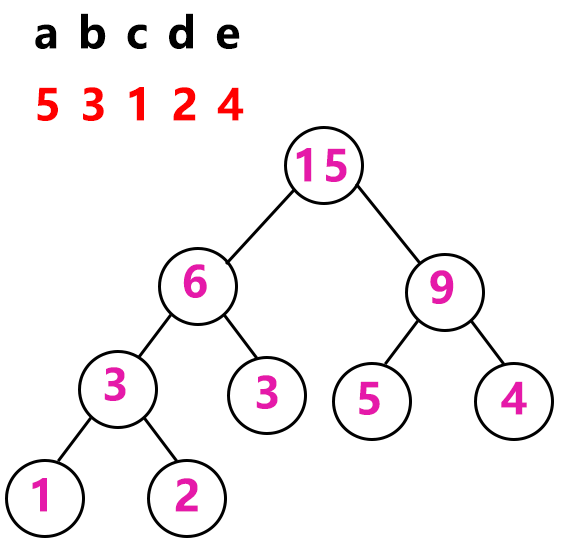
这样哈夫曼树就构建好了。接下来是编码。哈夫曼编码就是把构建好的哈夫曼树按左分支为0,右分支为1来编码这样的形式:

其中叶子结点就是字符,所以最后得到的编码就是:
c:000
d:001
b:01
a:10
e:11
这样得到的编码不会有二义性,且总编码空间是最小的,因为我们用的是构建哈夫曼树的方式,带权路径的长度是最短。