HDFS简介
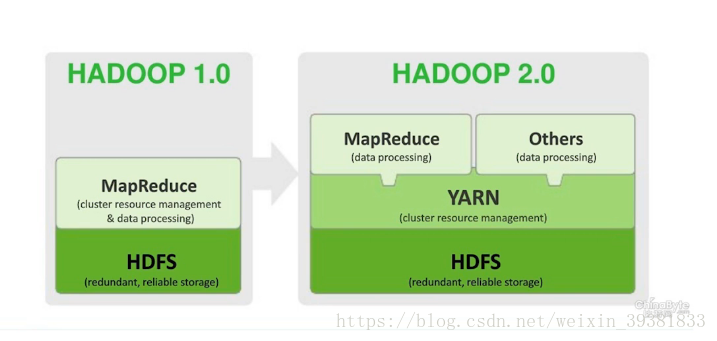
Hadoop的文件系统
设计结构
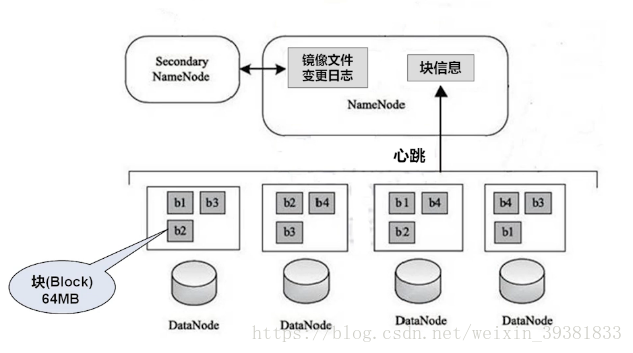
1 Block(块)
HDFS将文件分配成block来存储,每个块默认64MB,块是文件存储处理的逻辑单元,按照block管理
2 NameNode
管理节点,存放元数据
- 文件与数据块的映射表
- 数据块与数据节点的映射表
HDFS体系结构
3 DataNode
HDFS的工作节点
用来存放真正的数据块的
HDFS中数据管理和容错
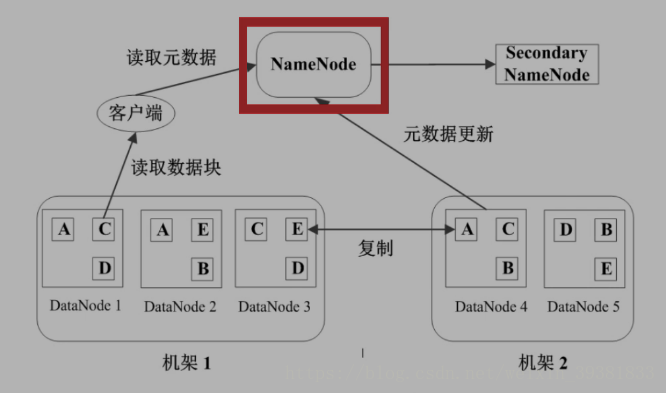
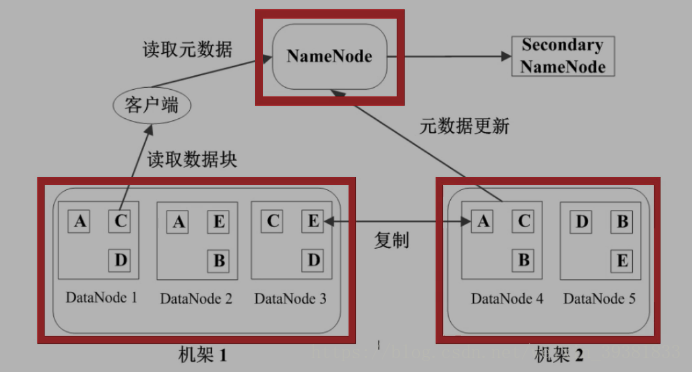
数据块副本
为了保证硬件上的容错,每个数据块3个副本,分布在两个机架内的三个节点(两份在同一个机架 )。一个机架故障不影响。
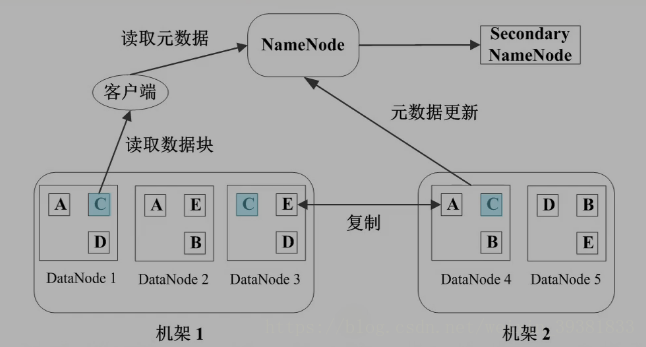
心跳检测
NameNode和DataNode之间有心跳协议,
DataNode定期向NameNode发送心跳信息(网络 关机)
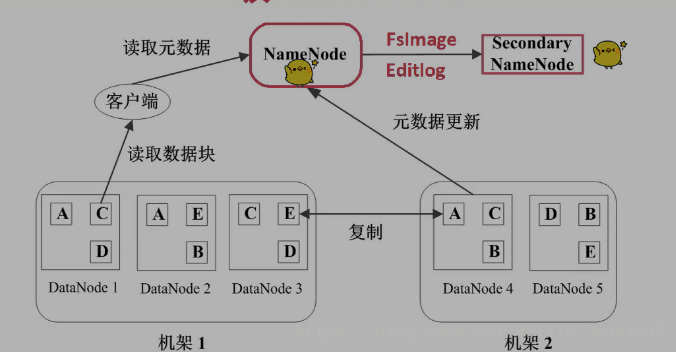
Secondary NameNode
NameNode的备份,定期同步元数据映像文件和修改日志
故障时转正
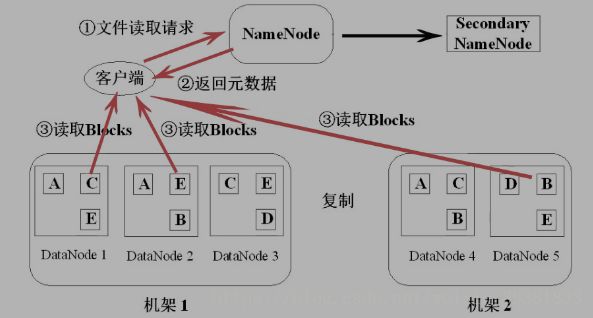
HDFS中文件读取的流程
读取
- 客户端先在NameNode查找DataNode的位置
- 再按照位置在datanode中找到,下载下来
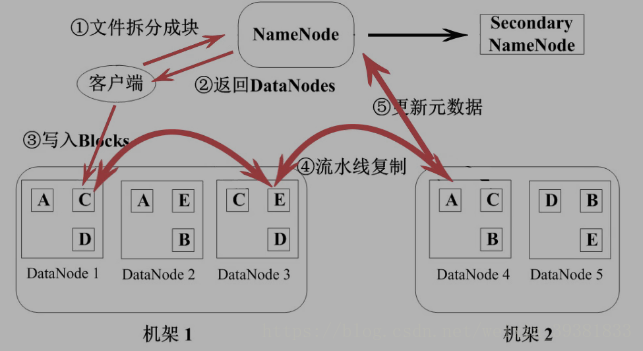
写入
- 文件拆分成块
- 在NameNode中查找,空的DataNode,返回空的地址
- 在空的DataNode中写入
- 流水线复制成三分
更新NameNode
HDFS特点
1 数据冗余 硬件容错
* 2 流式的数据访问*
3 存储大文件 不适合存储大量小文件
4 适合数据批量读写 吞吐量高
不适合交互式应用 高延迟
5适合一次写入多次读取,顺序读写
不支持多用户并发写相同文件HDFS 使用
可视化操作
hadoop namenode -format查看文件夹
hadoop fs -ls/提交
hadoop fs -put hadoop-env.sh 目录从HDFS下载
hadoop fs -get input/hadoop-env.sh hadoop-env2.shhadoop fs -get (HDFS目录) (另命名)看文件系统所有信息
hadoop dfsadmin -report