HDFS由NameNode、DataNode、Second人
一、NN(NameNode)
1.1 NameNode信息
NameNode维护的是HDFS上的文件系统的命名空间:
- 文件名称
- 文件的目录结构
- 文件的属性(权限、创建时间 副本数)
- 一个文件包含哪些块, 数据块在哪些DN节点上(DN列表信息存储在内存中)
二、DN(DataNode)
2.1 DataNode信息
DataNode用来存储数据块和数据块校验的:
- 每隔3秒发送一次心跳
- 每隔10次心跳发送一次blockReport
三、SNN(SecondaryNameNode)
3.1 SecondaryNameNode信息
大体上用来备份NN的数据。
- 每隔1小时备份一次。
- 存储的是命名空间镜像文件 fsimage + 编辑日志editlog
- 合并fsimsge + editlog为新的fsimage,并推送给NN,称为检查点checkpoint
- 生产上不做SNN,用HA
四、副本放置策略
副本放置策略依托于机架感知,机架感知在大型集群中变得尤为重要,这样做是为了容灾。机架感知可以人为干预去做。下面详细介绍放置策略:
- 第一个副本:放置在上传文件的DataNode上,如果外节点提交,随机一台不忙的节点上
- 第二个副本:于第一个副本不同的机架的节点上
- 第三个副本:于第二个副本相同机架不同节点上
- 等等:随机放在节点上
五、HDFS文件读流程
HDFS的读流程的对于客户端来说是透明的。使用者往往只需要一个命令就能读取文件,但是其背后的交互是复杂的。
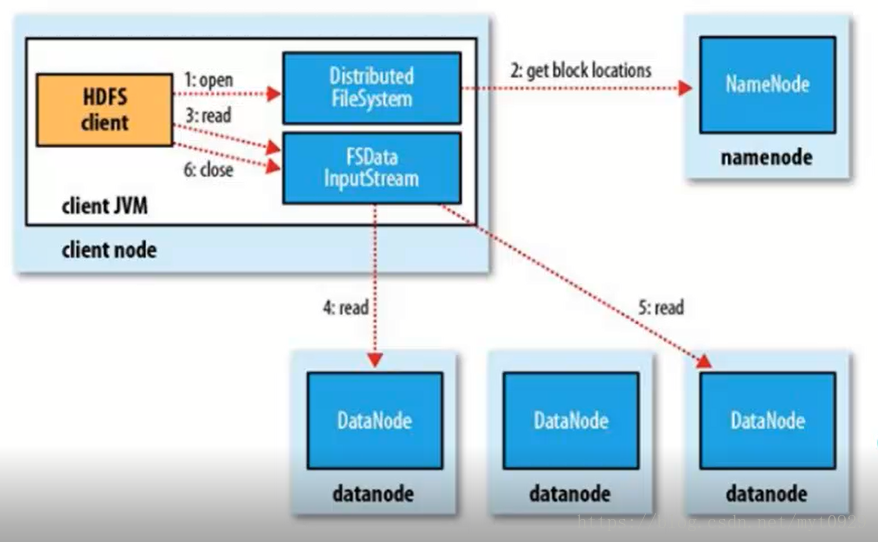
- 在Client自己的jvm中向自己的分布式文件系统open(带上要读取的文件的路劲和名称),去RPC连接NN,这个时候NN会审核连接(包括权限、是否存在)
- 经过通讯,NN返回该文件的部分或者全部的block块列表(实际上是个对象)
- 该对象就是FSDataInputStream,用来读取数据流的,然后Client调用对象read方法读
- FSDataInputStream获得第一个块最近副本所在机架,同时做check,如果损坏,则另一个最近副本机器上读取。
- 同理读取第二个块。
- 在第二点中返回的是部分块信息,这样来,文件还没有读取完毕,则FileSystem会从nameNode上读取下一批块列表。(对于client端来说是透明的)
- 调度读取完毕后关闭读取流
六、HDFS文件写流程
写流程也是对客户端来说是透明的。流程有一个特点就是流水线式操作。
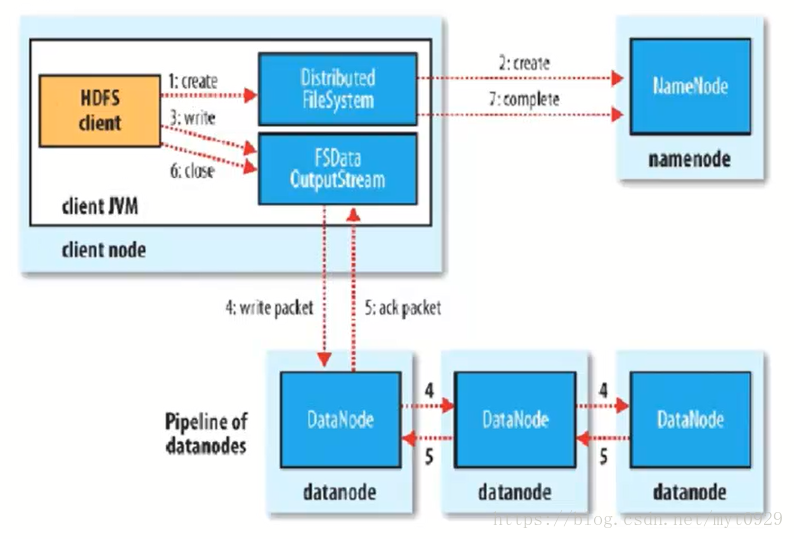
- 在Client自己的jvm中向自己的分布式文件系统create方法(带上要写的文件的路劲),去RPC连接NN,这个时候NN会审核连接(包括权限、是否存在)
- 如果OK,可以批准写入,则NN创建一个新的文件,不关联任何数据块和节点机器,同时返回FSDataoutputStream对象
- Client调用FSDataoutputStream的write去写入数据。
- 依次写入块,第一个块在写时,先写入第一个副本要写入的机器,然后该机器把块副本发给第二要副本要写的机器,然后是第三个机器,写完毕,然后返回第二个机器ACK,然后返回第一个节点ACK。然后返回FSDataoutputStream说明该数据块写完毕。
- 所有的块写完,close关闭数据流。
- 当关闭后,再调用FileSystem.compelete(),告诉NN节点写入成功。