ML Lecture 0-1:Introduction of Machine Learning
机器学习简介(Introduction of ML)

机器学习与人工智慧之间的关系:
人工智慧是想要达成的目标,机器学习(即让机器具有学习的能力)是想要达成目标的手段深度学习与机器学习之间的关系:
深度学习是机器学习的其中一种方法
生物的行为取决于两件事:先天本能与后天学习。对机器而言也是一样,机器的先天本能是由其创造者赋予的,后天学习则是通过一系列的数据训练。机器学习所做的事情可以看做是在寻找一个函数:让机器具有一种能力,使得机器能够根据提供给它的资料,寻找出我们需要的函数。很多我们关心的问题,都可以看成是在寻找一个函数。举例来说:
- 语音识别:我们需要找到一个函数,它的输入是声音讯号,它的输出是语音辨识的文字。这个函数可能非常复杂,假如我们利用语言学的文献写一堆规则,来做语音辨识,大概率是无法成功的,所以需要凭借机器的力量,将这个复杂的函数找出来
- 图像识别:输入一张图片(转换为像素),输出是图片中的物体
- 阿法狗:找一个函数,这个函数的输入是棋盘的盘式(哪些位置有黑子,哪些位置有白子),输出下一步落子在哪

如何找到对应的函数,找出函数的步骤框架是什么?以图像识别为例:我们要找到一个函数,输入一张图片,它告诉我们图片中有什么样的东西。完成这项工作:
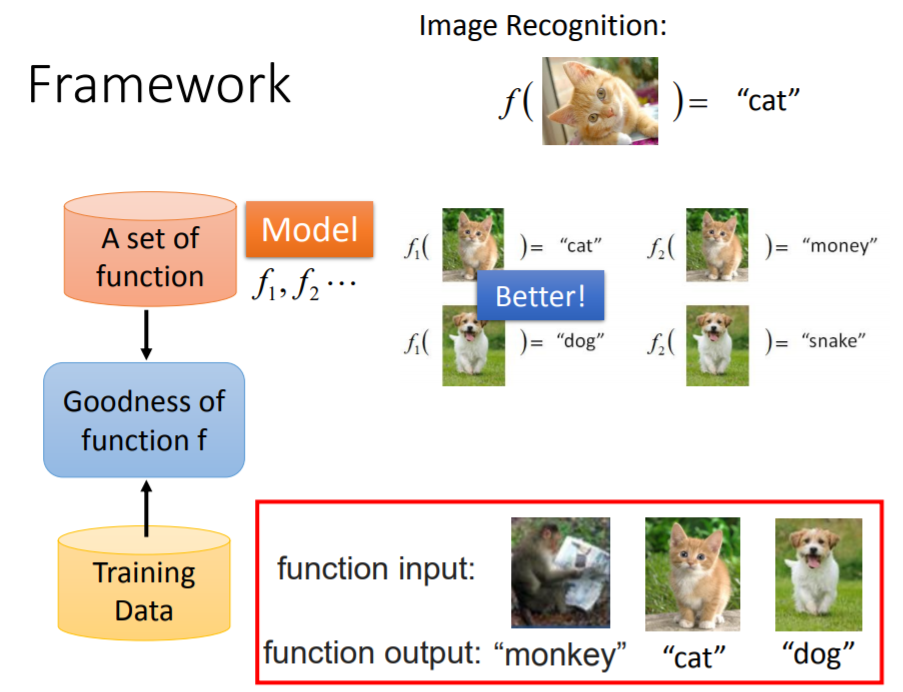
- 第一步是先准备一个函数集,这其中有成千上万个函数: , …。我们称函数集为一个模型
- 第二步是准备训练资料,这些资料可以告诉机器,一个好的函数,它的输入输出该是什么样子,具备什么样的关系(看到猫/狗就应该输出猫/狗)
- 然后机器就可以根据训练资料,判断一个函数是不是好的(Goodness of function)。显然,在图例中 更符合训练集的叙述,更符合训练集提供的知识,所以是比 更优的
基于此类型的训练场景,其实是一种无监督学习(告诉机器关于函数的输入和输出)。
但机器光是能够确定一个函数的好坏还不够,因为在一个模型里面,有成千上万个函数,逐个去判断好坏需要很大的工作量。因此机器还需要一个有效率的演算法,帮助机器从函数集里面挑出最好的函数 。
找到 后,利用它完成以下功能:输入一张在训练集中没有看过的猫图片,希望它输出告诉我们这就是一只猫。
这里涉及到一个很重要的问题:机器在学习的时候并没有见过这只猫,如何才能知道,其学习成果 ,在测试时能否正确辨识出这是一只猫?或者说,机器有没有举一反三的能力?这个问题后续会提及。
我们称蓝色框的左边部分为训练过程(Training);右边称为测试过程(Testing)。
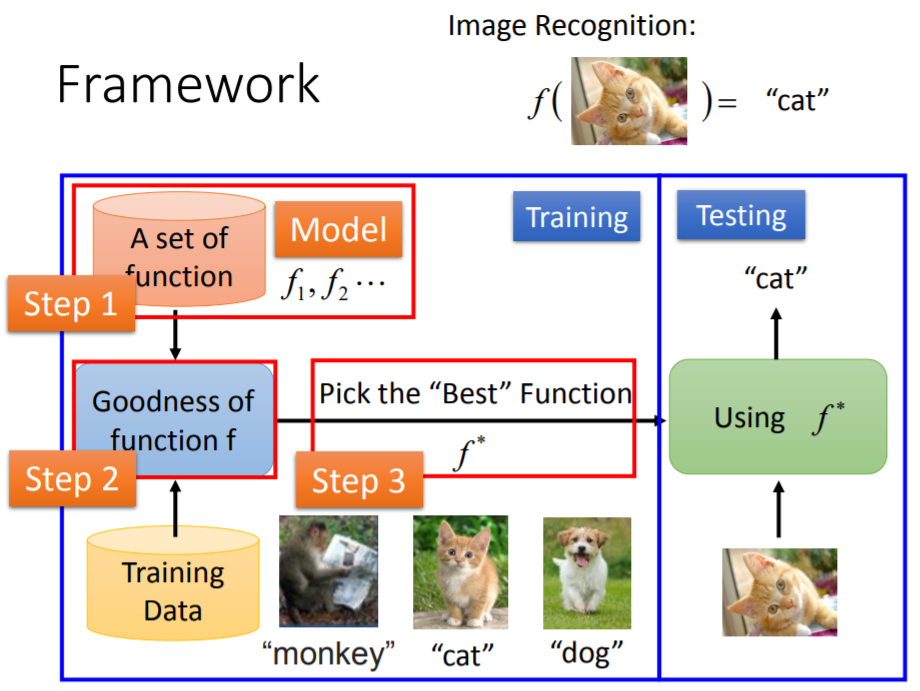
在整个机器学习的框架里面,分成三个步骤:
- 定义一个函数集
- 让机器可以衡量一个函数的好坏
- 让机器有一个自动的方法、好的演算法,帮助其挑出最好的函数

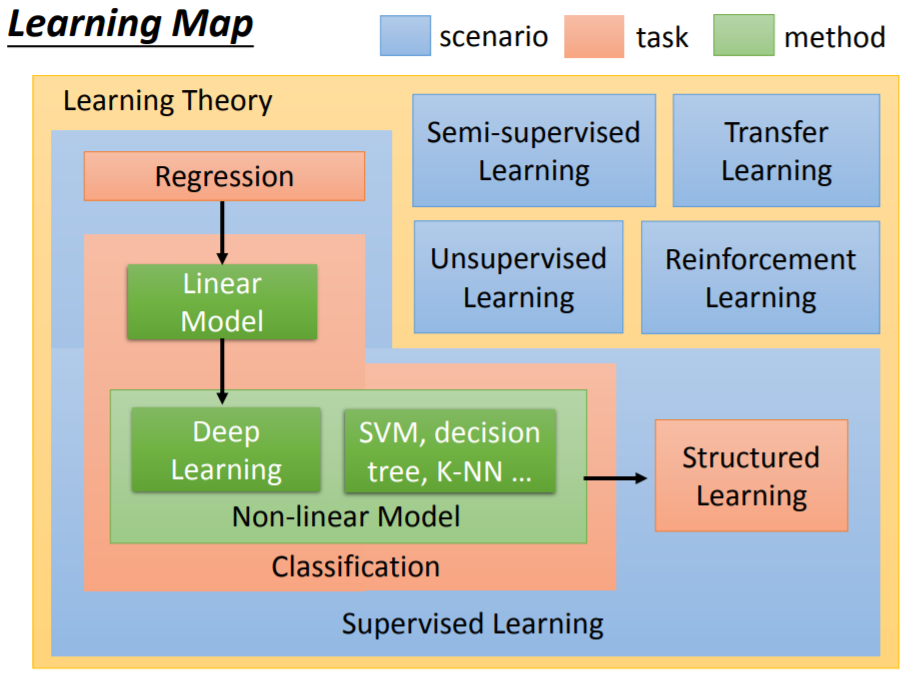
学习图谱(Learning Map)
如下学习图谱,蓝色代表学习情境(Scenario),不同的蓝色方块代表不同的学习情境,包括有监督(Supervised Learning)、半监督(Semi-supervised Learning)、迁移学习(Transfer Learning)、无监督(Unsupervised Learning)、强化学习(Reinforcement Learning)。通常学习情境是我们无法自己控制的,是根据客观情况而定的。例如我们为什么需要进行强化学习,就是因为我们没有数据可以进行有监督学习,所以被迫进行强化学习。事实上,如果一个问题可以收集到数据,能够进行监督学习,就没有必要采用强化学习方法。总而言之,手上有什么数据,就决定了学习情境的性质。
红色代表学习问题(Task),是我们需要解决的问题。对于不同的问题,我们要寻找的函数的输出形式不同,可分为回归(Regression)、分类(Classification)、结构化学习(Structured Learning)。在不同的学习情境(有监督、半监督、迁移学习、无监督、强化学习)下,都有可能遇到回归、分类或结构化学习等问题。
绿色代表具体方法(Method),是在具体问题中用来解决问题的模型,包括线性模型(Linear Model)、非线性模型(Non-linear Model)(深度学习、SVM、决策树、K-NN等)。在不同的学习问题(回归、分类、结构化学习)中,都可以用上述模型解决。
回归(Regression):是机器学习当中一种学习任务的类型。做回归意味着,机器挑选出来的 ,其输出值是一个scalar/real number(数值)。例如预测PM2.5,意味着需要找一个函数,这个函数的输出是未来某一个时间的PM2.5(一个数值),这就属于回归问题。机器无法凭空猜出这一数值,需要我们提供一些额外的资讯(例如今天上午的PM2.5、昨天上午的PM2.5等等)。总之,这个函数吃到肚子里的是过去的PM2.5的资料,吐出来的是未来PM2.5的数值。

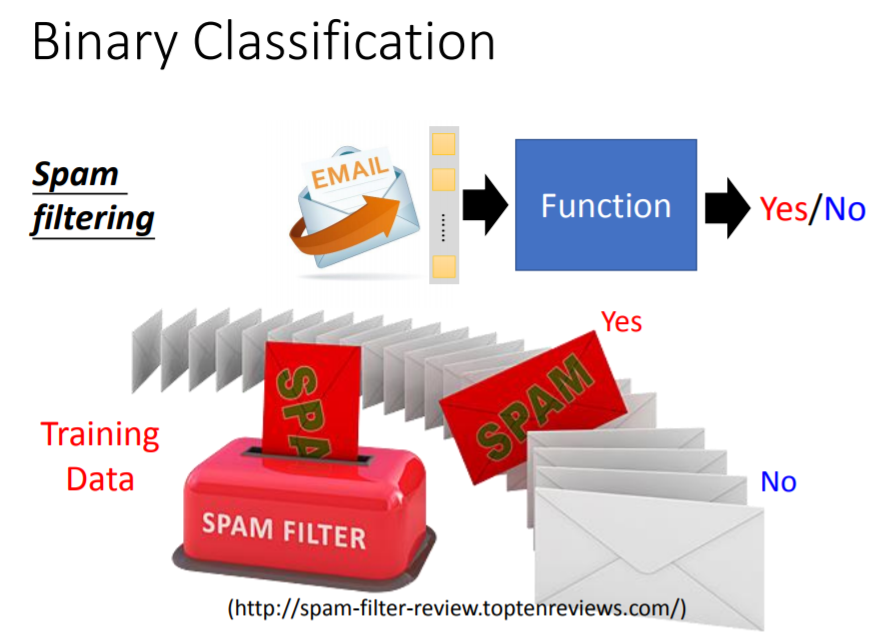
分类(Classification):回归与分类的差别就在于,机器的输出类型不同。前者输出的是数值,后者又可分为两类问题:
- 二分类问题(输出是/否):垃圾邮件过滤
- 多分类问题(机器需要从数个类别中选择正确的类别):新闻文章分类(政治、经济、体育等)


结构化学习(Structured Learning):大多数人都认为机器学习就是回归、分类两种问题,事实上还有许多结构化学习问题是人们还未探究到的。回归问题中机器输出的是数值,分类问题中机器输出的是分类选项,而在结构化学习中,机器的输出具有复杂的结构性。例如:
- 在语音识别中,机器的输入是声音讯号,输出是一个语句。而句子是由很多词汇拼凑而成的,那么它就是一个有结构性的对象
- 在机器翻译中,输入中文希望机器翻译成英文,机器的输出也是一个带有结构属性的句子
- 人脸辨识,输入角色图片,希望机器输出准确的人名

以上是我们需要机器解决的问题,而在解决问题的过程中,第一步是选择一个模型(函数集),不同的模型会得到不同的结果。
最简单的模型是线性模型,但现在我们更注重于非线性模型的研究,其中最耳熟能详的是深度学习。由于深度学习的函数特别复杂,因此可以处理特别复杂的问题,例如:
- 图像识别:这个复杂函数可以描述图片和它的类别之间的关系,找出这个复杂函数的方法就是准备一堆训练资料,供机器学习
- 下围棋:下围棋其实就是一个分类问题,只是这个分类问题需要一个很复杂的函数,给它输入的是棋盘盘式,输出是下一步的落子位置。而我们已知一个棋盘上有 个位置可以落子,因此下围棋就可以视为有 个类别的分类问题。
除了深度学习,还有许多其他非线性的机器学习模型:SVM、决策树、K-NN…。
以上所述都是有监督的学习(Supervised Learning)。有监督学习的问题在于,我们需要大量的训练集,来寻找函数的输入与输出之间存在什么关系。函数的输出通常称为label。机器学习的过程中,如果需要大量的label,那么针对的就是有监督的情境。而训练当中、用来作为输出的数据,往往无法用很自然的方式取得,必须凭借人工力量,想要找到足量的label将十分耗力。
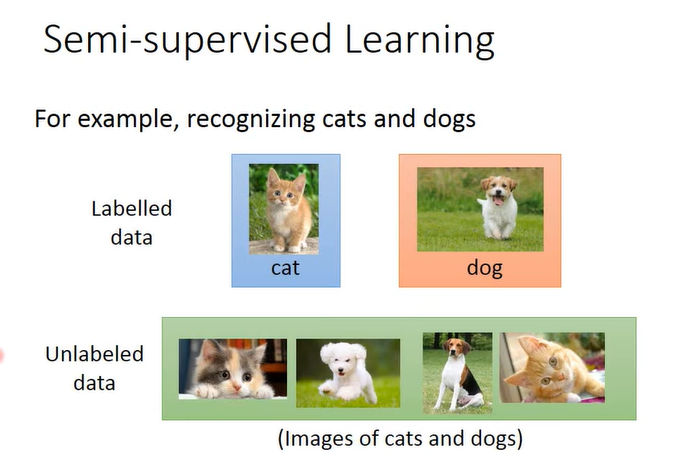
半监督学习(Semi-supervised Learning)则可以减少所需要的label量,例如猫、狗图形识别中,我们只有少量关于猫、狗的label图片,还有大量的猫、狗图片是没有经过label的,无法告诉机器它们是猫还是狗。但在半监督学习中,这些没有label的猫、狗图片也是对学习有帮助的。
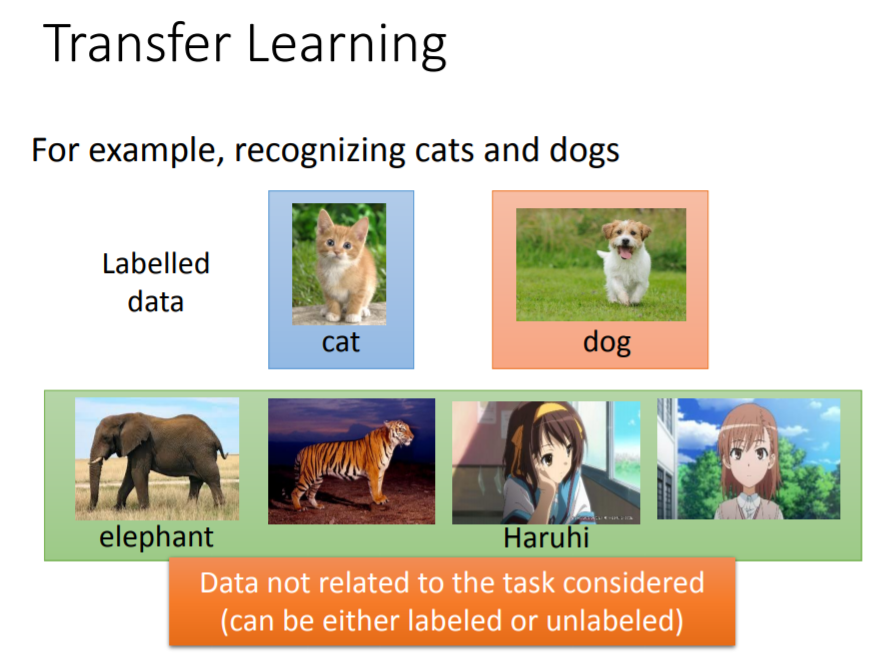
另外一个可以减少数据用量的方向是迁移学习(Transfer Learning)。沿用上例的猫、狗图形识别,我们仍旧只有少量关于猫、狗的label图片。此外,我们还有大量其他图片(可能有label,也可能没有label),这些图片与我们现在要考虑的猫狗分类问题没有什么特定的关系,考察它们到底能带来什么样的帮助,即所谓的迁移学习。
更进阶的问题是无监督学习(Unsupervised Learning)。在没有任何label的情况下,机器到底可以学到什么程度。例如:
给机器查阅大量文章,它是否能学会每一个词汇的意思。这个过程可以看成是:找到一个函数,把一个词汇(Apple)丢进去,期望机器能输出这个词汇的意思,也许机器会用一个向量来表示这个词汇的各种不同含义
给机器查看大量动物,它是否能自己学会创造动物




在无监督问题中,只有大量数据(文章、词汇、图片)的输入,而没有任何的输出。
最后一类是强化学习(Reinforcement Learning)。强化学习的发展由来已久,并不是新的技术,最近比较受重视是由于DeepMind运用这一技术玩Atari游戏,以及阿法狗对强化学习技术的应用。有监督学习与强化学习相比,分别具有如下特点:
- 在有监督学习中,我们会告诉机器正确答案是什么,机器在学习过程中,得到了手把手的训练,属于learning from teacher
- 在强化学习中,我们没有告诉机器正确的答案是什么,机器被告知的只有一个分数,并据此来判断自己做的好与不好,但并不知道哪里做得好/不好,属于learning from criticizing


显然,强化学习如此受到重视,就是因为其更符合人类真正的学习情境。阿法狗就是综合运用了有监督学习和强化学习。