一、HashMap
1.概述
HashMap是一个包含key-value键值对的数据集合。
HashMap继承了Map,Clonable和Serializable接口。
HashMap是线程不安全的集合,只能适用于单线程,key和value都可以为null。
HashMap的示例有两个参数影响性能:“初始容量”和“加载因子”
2.HashMap数据结构
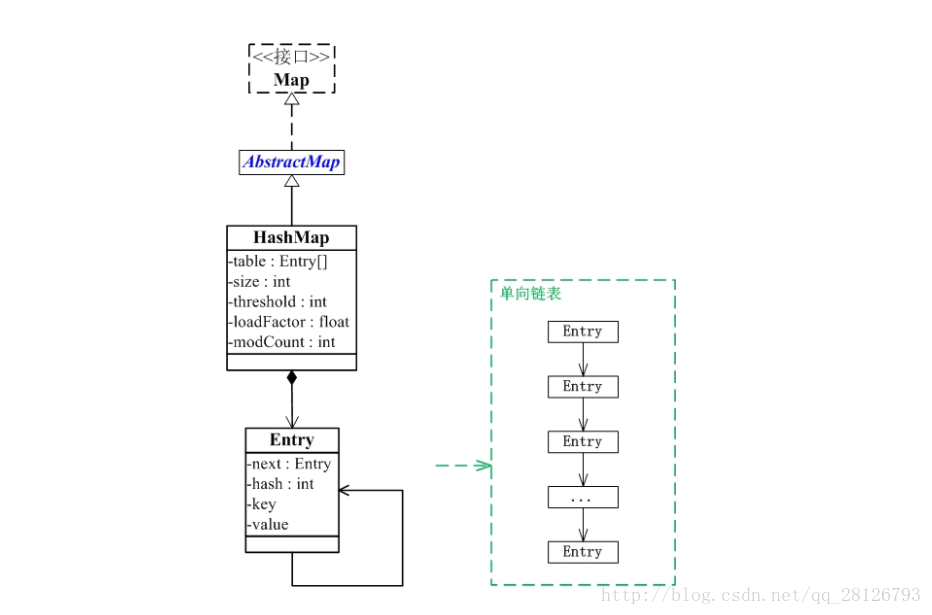
1)HashMap继承AbStractMap类,实现了Map接口。
2)HashMap重要的几个成员变量:
table:是一个Entry[]数组,key-value键值对都是存储在Entry数组中
size:HashMap的大小
3:源码
属性:
DEFAULT_INITIAL_CAPACITY = 16 默认初始容量MAXIMUM_CAPACITY = 1 << 30 最大容量DEFAULT_LOAD_FACTOR = 0.75f 默认加载因子:加载因子定义:散列表的实际数目(n)/散列表的容量(m)加载因子衡量的是一个散列表的控件的使用程度,加载因子越大表示散列表的装填程度越高,反之越小。对于使用链表发的散列表来说,加载因子越大,对于空间的利用更加充分,然而查找的效率会降低,太小的话,会使得数据过于稀疏,对空间造成严重的浪费。
transient Node<K,V>[] table; 存储Entry数组构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0) //判断初始化容量是否小于0
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY) //判断初始化容量是否大于最大容量
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor)) //判断实际加载因子的合法性
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity); //计算HashMap的阈值
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//实际加载因子等于默认的加载因子
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}V put(K key, V value):put操作
public V put(K key, V value) {
//如果key为空的情况
if (key == null)
return putForNullKey(value);
//计算key的hash值
int hash = hash(key);
//计算该hash值在table中的下标
int i = indexFor(hash, table.length);
//对table[i]存放的链表进行遍历
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//判断该条链上是否有hash值相同的(key相同)
//若存在相同,则直接覆盖value,返回旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//修改次数+1
modCount++;
//把当前key,value添加到table[i]的链表中
addEntry(hash, key, value, i);
return null;
} private V putForNullKey(V value) {
//查找链表中是否有null键,key为null时,将value防止在数组第一个位置
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//如果链中查找不到,则把该null键插入
addEntry(0, null, value, 0);//将null的插入到列表的第一位
return null;
} void addEntry(int hash, K key, V value, int bucketIndex) {
//如果size大于极限容量,将要进行重建内部数据结构操作,之后的容量是原来的两倍,并且重新设置hash值和hash值在table中的索引值
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//真正创建Entry节点的操作
createEntry(hash, key, value, bucketIndex);
}如果key不为null值:传入的value会将旧的value值覆盖
1. 传入key和value,判断key是否为null,如果为null,则调用putForNullKey,以null作为key存储到哈希表中;2. 然后计算key的hash值,根据hash值搜索在哈希表table中的索引位置,若当前索引位置不为null,则对该位置的Entry链表进行遍历,如果链中存在该key,则用传入的value覆盖掉旧的value,同时把旧的value返回,结束;
3. 否则调用addEntry,用key-value创建一个新的节点,并把该节点插入到该索引对应的链表的头部
V get(Object key)
public V get(Object key) {
//如果key为null,求null键
if (key == null)
return getForNullKey();
// 用该key求得entry
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
} final Entry<K,V> getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key); //获取hash的值
for (Entry<K,V> e = table[indexFor(hash, table.length)]; //indexFor求得Hash值对应的table的索引位置
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) //存在key,返回对应的Entry
return e;
}
return null;
}