并查集的原理、实现与应用
什么是并查集
如果给出各个元素之间的联系,要求将这些元素分成几个集合,每个集合中的元素直接或间接有联系。在这类问题中主要涉及的是对集合的合并和查找,因此将这种集合称为并查集。
什么是等价类
在并查集中,同一个集合中的元素直接或者间接地有联系,我们就把这些元素称为属于同一个等价类。等价类具有三个基本性质:
(用X~Y表X与Y等价)
自反性:如X~X则X~X;
对称性:如X~Y则Y~X;
传递性:如X~Y且Y~Z则X~Z;
等价类应用
设初始有一集合s={0,1,2,3,4,5,6,7,8,9,10,11}
依次读若干事先定义的等价对
0~4,3~1,6~10,8~9,7~4,6~8,3~5,2~11,11~0
我们想把每次读入一个等价对后,把等价集合合并起来。
则每读入一个等价对后的集合状态是:(用{}表示一个等价集合,初始时每个元素为一个集合)
初始 {0},{1},{2},{3},{4},{5},{6},{7},{8},{9},{10},{11}
0 ~ 4 {0,4},{1},{2},{3},{5},{6},{7},{8},{9},{10},{11}
3 ~ 1 {0,4}, {1,3},{2},{5},{6},{7},{8},{9},{10},{11}
6 ~ 10 {0,4},{1,3},{2},{5},{6,10},{7},{8},{9},{11}
8 ~ 9 {0,4},{1,3},{2},{5},{6,10},{7},{8,9},{11}
7 ~ 4 {0,4,7},{1,3},{2},{5},{6,10},{8,9},{11}
6 ~ 8 {0,4,7},{1,3},{2},{5},{6,8,9,10},{11}
3 ~5 {0,4,7},{1,3,5},{2},{6,8,9,10},{11}
2 ~ 11 {0,4,7},{1,3,5},{2,11},{6,8,9,10}
11 ~ 0 {0,2,4,7,11},{1,3,5},{6,8,9,10}
并查集对等价关系的处理方式
并查集对等价关系的处理思想是开始把每一个对象看作是一个单元素集合,然后依次按顺序(就是读入等价对)将属于同一等价类的元素所在的集合合并。在此过程中将重复地使用一个搜索运算,确定一个元素在哪一个集合中。
当读入一个等价对AB时,先检测这两个等价对是否同属一个集合,如是,则不用合并。不是,则用个合并算法把这两个包含AB的集合合并,使两个集合的任两个元素都是等价的(由传递性)。
并查集的实现方式
通常实现并查集有两种数据结构:链表和森林。森林是较好的并查集实现方式。因此,我们就以树作为数据结构来实现并查集的操作。
并查集的表示方法
可以将森林中的一棵树都看成是某些元素的集合,从而可以用树来表示并查集。
而树的存储方法有很多种,如记录数组法、链表等,表示方法包括父亲表示法、儿子表示法、父亲儿子表示法、等;每个结点存储的信息包括:结点数据、儿子结点位置、父结点位置等。
而用树来表示并查集时,根据并查集的算法特点,树的存储结构采用父亲表示法,即用一个一维数组p表示每个元素的父结点的下标位置。
例如:p[3] = 4 就是说3号结点的父亲是4号结点。如果一个结点的父结点是它自己的话,我们就认为它是一个集合的根结点。
根结点代表了一个集合
并查集中每个元素都存在等价关系,那么用哪个元素来代表整个集合呢?由于树的根代表了一棵树,那么很自然地,根结点就代表了一个并查集。
这样,要判断两个元素是否属于同一个并查集时,算法就非常简单:只要比较两个元素所在的树的根结点是否相等,如果相等则属于同一个并查集;否则必须是不同的并查集。
另外,要合并两个并查集也非常简单:只要将一棵树的根作为另一棵树的儿子即可。
并查集的三种基本操作
并查集是一种可以方便地进行以下三种操作的数据结构:
初始化并查集:MakeSet
查找元素x所在的集合,返回根:Find(x)
合并两个元素在所的集合: Union(x,y)
初始化并查集:MakeSet
初始时,每个元素就是一个集合
void MakeSet(int n) {
for(int i = 1; i <= n; i++)
fa[i] = i; //父结点位置指向自己,表示自己是根
rank[i]=0; //表示树的深度,合并两集合时有用
}
查找元素x所在的集合:Find(x)
根据树的特点,树的根是值和下标相等的元素,因此基本的算法如下:
int FindSet(int x) {
while(fa[x] != x)
x = fa[x];
return x;
}
带路径压缩的Find(x)
在while循环中,把x的所有祖先结点的父结点都直接设为集合的根结点,这样在查找的过程中同时也改变了树的形态,减小了树的深度,这就叫路径压缩。虽然这增加了时间,但以后的find会快。平均效能而言,这是个高效方法。
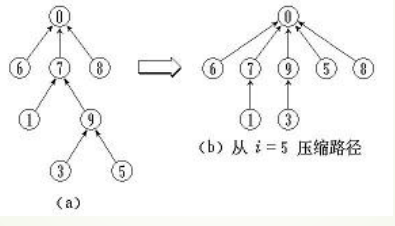
实现:
int FindSet(int x) {
if(fa[x] != x) //当x不是根时
fa[x] = FindSet(fa[x]); //路径压缩
return fa[x];
}
合并两个元素在所的集合: Union(x,y)
合并操作首先找出x,y所属集合的根结点,如果根结点相等,则说明x,y本来就在同一个集合,用不着合并,直接退出。
否则,进行启发式合并。定义rank作为合并的启发函数值,刚建立的新集合rank为0,当两个rank相同的集合合并时,随便选一棵树作为新根,并把它的rank加1;否则rank大的树作为新根。
在有路径压缩的前提下,启发式合并的效率提高并不多。因此可以省略。
非启发式合并:
void UnionSet(int x, int y) {
int u = Find(x), v = Find(y);
if( u == v) return;
fa[u] = v;
}
并查集的时间复杂度
可以证明,经过启发式合并和路径压缩之后的并查集,执行m次查找的复杂度为O(mα(m))
其中α(m)是Ackermann函数的某个反函数,你可以近似的认为它是小于5的。所以并查集的单次查找操作的时间复杂度也几乎是常数级的。
所以,并查集是一种非常高效的数据结构