基本定义
把一棵树分成很多条链,然后利用数据结构(线段树、树状数组等)来维护这些链。
作用
树链剖分用于树路径信息维护。
剖分方式
-
随便剖分
-
随机剖分
-
轻重链剖分(本文)
轻重链剖分的基本概念
重结点:子树结点数目最多的结点;
轻节点:父亲节点中除了重结点以外的结点;
重边:父亲结点和重结点连成的边;
轻边:父亲节点和轻节点连成的边;
重链:由多条重边连接而成的路径;
轻链:由多条轻边连接而成的路径;
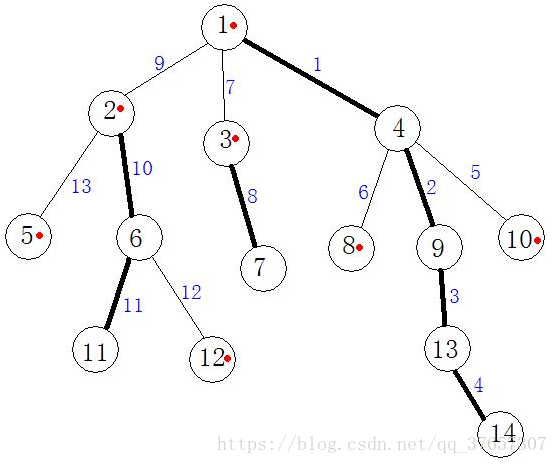
如图:加粗的边为重边,红点为每条重链的顶端节点(后称top)。
基本性质
性质1:轻边(U,V),size(V)<=size(U)/2。
如果size(V)>size(U)/2的话,那么V是U的size值最大的儿子节点,则(U,V)为重边。
性质2:从根到某一点的路径上,不超过O(logN)条轻边,不超过O(logN)条重路径。
根到某一点的路径上,轻边最多的情况,就是所有的边都是轻边,那么不可能超过O(logN)条的,一个点到根节点的路径上,是一条重路径与一条轻边交替出现,所以重路径的条数最多和轻边条数一样,也就是不超过O(logN)条。
重链剖分的实现
重链剖分的过程为2次DFS
需要用到的数组:
siz[u]//用来保存以u为根的子树结点个数
top[u]//用来保存当前结点u所在链的顶端节点
son[u]//用来保存当前结点u的重儿子编号
dep[u]//用来保存当前结点x的深度
fa[u]//用来保存当前结点x的父亲编号
id[u]//用来保存树中每个结点剖分后的新编号,即DFS序编号
rnk[pos]//用来保存线段树中位置为pos的结点在原树上的编号
//tid[]和rnk[]互为反函数第一次dfs:找重边
inline void dfs1(int u,int fa,int d)
{
dep[u]=d,son[u]=0,siz[u]=1,fat[u]=fa;
for(int i=0;i<g[u].size();i++)
{
int v=g[u][i];
if(v!=fa)
{
dfs1(v,u,d+1);
siz[u]+=siz[v];
if(siz[son[u]]<siz[v])//找siz最大的子节点
son[u]=v;
}
}
}第二次dfs:连重边成重链
inline void dfs2(int u,int tp)
{
top[u]=tp;//当前重链的起始位置
id[u]=++tot;//分配新编号
if(son[u])//重儿子继续连在当前重链上
dfs2(son[u],top[u]);
for(int i=0;i<g[u].size();i++)
{
int v=g[u][i];
if(v!=fat[u]&&v!=son[u])
dfs2(v,v);//轻儿子自己作为新的重链端点
}
}
维护重链
剖分完之后,每条重链就相当于一段区间,用数据结构去维护。
把所有的重链首尾相接,放到同一个数据结构上,然后维护这一个整体即可。
至于选择什么样的数据结构去维护,要根据题目的需要。
因为重链是线性序列,所以用一棵线段树维护最常见。
修改操作
树上单点修改操作
根据id[u]得到原树上的结点u在线段树上的位置,直接在线段树中修改。
树上沿路径修改操作
整体修改点 u和点v的路径上的权值 。
A.如果U和V在同一条重链上
直接用数据结构修改id[u]至id[v]间的值。
B.如果U和V不在同一条重链上
一边进行修改,一边将u和v往同一条重链上靠,然后就变成了A的情况。
a.若fa[top[u]]与v在同一条重链上。

修改点u与top[u]间的各权值,然后u跳至fa[top[u],就变成了I的情况。
b.若u向上经过若干条重链和轻边与v在同一条重链上。

不断地修改当前u和top[u]间的各权值,再将u跳至fa[top[u]],直到u与v在同一条重链。
c.若u和v都是向上经过若干条重链和轻边,到达同一条重链
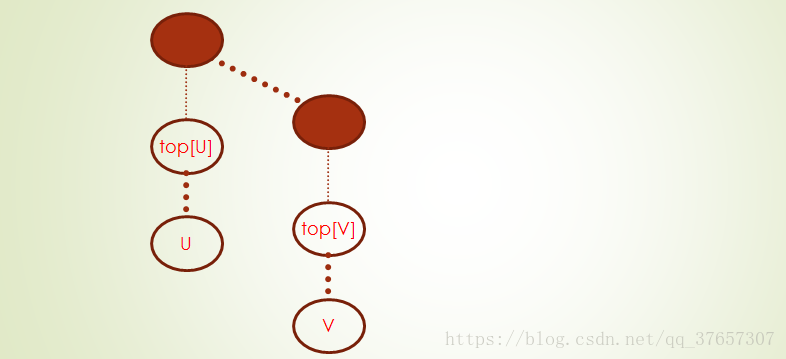
每次在点u和点v中,选择dep[top[x]]较大的点x,修改x与top[x]间的各权值,再跳至fa[top[x]],直到点u和点v在同一条重链。
总结
情况a、b是情况c的比较特殊的2种。
A也只是B的特殊情况。
所以,这一操作只要用一个过程。
代码:
inline void M(int v,int u,int v1)
{
int t1=top[v],t2=top[u];
while(t1!=t2)
{
if(dep[t1]<dep[t2])//每次处理深度大的
swap(t1,t2),swap(v,u);
modify(1,id[t1],id[v],v1);//线段树操作
v=fat[t1],t1=top[v];//往上传
}
if(dep[v]>dep[u])
swap(v,u);
modify(1,id[v],id[u],v1);
}
查询操作
和修改操作一模一样(区别在线段树里)
inline void Q(int v,int u,int v1)
{
int t1=top[v],t2=top[u];
while(t1!=t2)
{
if(dep[t1]<dep[t2])
swap(t1,t2),swap(v,u);
query(1,id[t1],id[v],v1);
v=fat[t1],t1=top[v];
}
if(dep[v]>dep[u])
swap(v,u);
query(1,id[v],id[u],v1);
}
例题
纯模板,没什么好说的,主要看个格式
代码:
#include<cstdio>
#include<algorithm>
#include<climits>
#include<vector>
using namespace std;
#define N 1000005
int dep[N],siz[N],son[N],fat[N],id[N],top[N];
int tot,n,m,c[N];
struct node
{
int l,r,sum,mx;
}t[N*4];
vector<int>g[N];
inline void dfs1(int u,int fa,int d)
{
dep[u]=d,son[u]=0,siz[u]=1,fat[u]=fa;
for(int i=0;i<g[u].size();i++)
{
int v=g[u][i];
if(v!=fa)
{
dfs1(v,u,d+1);
siz[u]+=siz[v];
if(siz[son[u]]<siz[v])
son[u]=v;
}
}
}
inline void dfs2(int u,int tp)
{
top[u]=tp;
id[u]=++tot;
if(son[u])
dfs2(son[u],top[u]);
for(int i=0;i<g[u].size();i++)
{
int v=g[u][i];
if(v!=fat[u]&&v!=son[u])
dfs2(v,v);
}
}
inline void push_up(int i)
{
t[i].sum=t[i<<1].sum+t[i<<1|1].sum;
t[i].mx=max(t[i<<1].mx,t[i<<1|1].mx);
}
inline void build(int l,int r,int i)
{
t[i].l=l,t[i].r=r,t[i].sum=t[i].mx=0;
if(l==r)
return;
int mid=(l+r)>>1;
build(l,mid,i<<1);
build(mid+1,r,i<<1|1);
push_up(i);
}
inline void modify(int i,int x,int v)
{
if(t[i].l==t[i].r)
{
t[i].sum=t[i].mx=v;
return;
}
int mid=(t[i].l+t[i].r)>>1;
if(x<=mid)
modify(i<<1,x,v);
else
modify(i<<1|1,x,v);
push_up(i);
}
inline int q1(int l,int r,int i)
{
if(t[i].l==l&&r==t[i].r)
return t[i].mx;
int mid=(t[i].l+t[i].r)>>1;
if(r<=mid)
return q1(l,r,i<<1);
else if(l>mid)
return q1(l,r,i<<1|1);
else
return max(q1(l,mid,i<<1),q1(mid+1,r,i<<1|1));
}
inline int Q1(int v,int u)
{
int t1=top[v],t2=top[u];
int ans=-INT_MAX;
while(t1!=t2)
{
if(dep[t1]<dep[t2])
swap(t1,t2),swap(v,u);
ans=max(ans,q1(id[t1],id[v],1));
v=fat[t1],t1=top[v];
}
if(dep[v]>dep[u])
swap(v,u);
ans=max(ans,q1(id[v],id[u],1));
return ans;
}
inline int q2(int l,int r,int i)
{
if(t[i].l==l&&r==t[i].r)
return t[i].sum;
int mid=(t[i].l+t[i].r)>>1;
if(r<=mid)
return q2(l,r,i<<1);
else if(l>mid)
return q2(l,r,i<<1|1);
else
return q2(l,mid,i<<1)+q2(mid+1,r,i<<1|1);
}
inline int Q2(int v,int u)
{
int t1=top[v],t2=top[u];
int ans=0;
while(t1!=t2)
{
if(dep[t1]<dep[t2])
swap(t1,t2),swap(v,u);
ans+=q2(id[t1],id[v],1);
v=fat[t1],t1=top[v];
}
if(dep[v]>dep[u])
swap(v,u);
ans+=q2(id[v],id[u],1);
return ans;
}
int main()
{
scanf("%d",&n);
for(int i=1;i<n;i++)
{
int x,y;
scanf("%d%d",&x,&y);
g[x].push_back(y);
g[y].push_back(x);
}
dfs1(1,0,1);
dfs2(1,1);
build(1,tot,1);
for(int i=1;i<=n;i++)
{
int x;
scanf("%d",&x);
modify(1,id[i],x);
}
int Q;
scanf("%d",&Q);
while(Q--)
{
char op[15];
int x,y;
scanf("%s%d%d",op,&x,&y);
if(op[1]=='H')
modify(1,id[x],y);
else if(op[1]=='M')
printf("%d\n",Q1(x,y));
else
printf("%d\n",Q2(x,y));
}
return 0;
}