React’s diff algorithm是了解React中的Diff算法必读的文章之一,以下内容是我在阅读过程中边看边翻译的,非科班渣翻请谅解。强烈建议阅读英文原文。
原文地址:
React’s diff algorithm (by Christopher Chedeau)
React是Facebook推出的一个用于构建UI的JavaScript库。React的设计从根本出发来提升性能。在本文中,我将会介绍diff算法和渲染如何在React中发挥作用的,以便使用者们能更好地优化其app。
Diff算法(Diff Algorithm)
在深入了解算法实现的细节之前,我们有必要先大致了解React的工作机制。
var MyComponent = React.createClass({
render: function() {
if (this.props.first) {
return
<div className="first">
<span>A Span</span>
</div>;
} else {
return
<div className="second">
<p>A Paragraph</p>
</div>;
}
}
});如上例所示,开发者描述他所期望的UI。需要注意render的返回值并不是一个真正的DOM节点,而只是轻量级的JavaScript对象,我们称之为虚拟DOM。
React基于虚拟DOM这个表示方法,计算得出将前一页面渲染成后一页面时所需的最小差异动作。以下给出的例子首先挂载<MyComponent first={true} />,然后替换为<MyComponent first={false} />,之后卸载该组件。这个过程中的DOM指令如下:
无节点 -> 挂载first节点
- 创建节点:<div className="first"><span>A Span</span></div>first节点 -> second节点
- 替换属性值:className="first"->className="second"
- 替换节点:<span>A Span</span>-><p>A Paragraph</p>卸载已挂载的second节点
- 移除节点:<div className="second"><p>A Paragraph</p></div>
逐层比较(Level By Level)
计算任意两棵树之间的最小差异数通常是O(n^3)问题。可以预见,这种算法在实际应用中是不可取的。React使用的是一个更简单有效的启发式算法,在O(n)复杂度下找到一个较好的近似解。
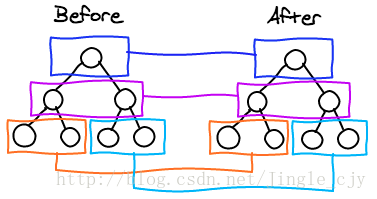
React只是逐层比较两棵树,以此确定两棵二叉树之间的最小差异数。这大大降低了算法复杂度,而且对最终解的准确度并没有很大的损失。因为在Web应用中,不同层之间的组件移动是很少见的,通常只在同一层之间移动。如下图所示:
列表(List)
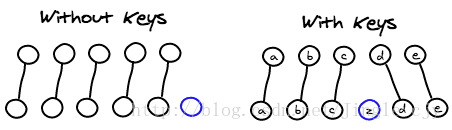
假设我们现在有一个组件,在一次迭代中会渲染出5个组件,接下来在5个组件的中间插入一个新的组件。在信息有限的前提下,进行两个组件列表之间的映射是非常困难的。
默认React会将两个列表中的第一个组件配对,然后配对两个列表第二个组件,以此类推。也可以由开发者为组件提供一个key属性来帮助React解决映射问题。在实际应用中,我们总是很容易在孩子节点中找出唯一的key,如下所示:
组件(Component)
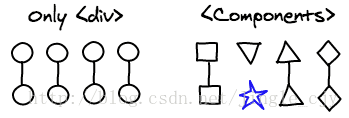
一个React APP通常由许多用户定义的组件组成,这些组件最终组成一棵主要由div组成的树。由于React通常是只比对那些具有相同类的组件,React的diff算法利用了这个辅助信息。
举例如下,如果<Header>组件被<ExampleBlock>替代,React会移除<Header>然后直接创建一个<ExampleBlock>。我们不需要浪费时间去比对两个不可能有任何相似之处的组件。如下所示:
事件代理(Event Delegation)
为DOM节点设置事件监听器是非常缓慢而且消耗内存的。所以React采用了另一种流行的技术,称为“事件代理”。React甚至更进一步,重新实现了一套兼容W3C标准的事件系统,这意味着IE8中的关于事件处理的bug也随之而去,因为在不同浏览器中的事件名称是一致的。
让我解释一下它是如何实现的:首先,文档根节点绑定一个事件监听器;当触发事件时,浏览器会提供触发事件的DOM节点;为了通过DOM层级结构传播事件,React不会迭代虚拟DOM层次结构。
取而代之的是,React利用了每个React组件都有一个唯一的编码层次结构的id这一事实。我们可以通过简单的字符串操作来获取所有父节点的id。比起直接将虚拟DOM节点与事件监听器绑定,将事件监听器存储在hash map中性能更好。下面是一个事件在虚拟DOM间进行分发的例子(同样也是捕获阶段和冒泡阶段):
// dispatchEvent('click', 'a.b.c', event)
clickCaptureListeners['a'](event);
clickCaptureListeners['a.b'](event);
clickCaptureListeners['a.b.c'](event);
clickBubbleListeners['a.b.c'](event);
clickBubbleListeners['a.b'](event);
clickBubbleListeners['a'](event);浏览器为每个事件和每个监听器创建一个新的事件对象,这样的好处是,你可以保存事件对象的引用甚至修改它,然而这样的缺点是需要大量的内存分配操作。React会在应用启动时在内存中分配一个对象池,每当需要一个事件对象时,就会从对象池中选取一个可用的事件对象进行复用。这样大大降低了垃圾回收的复杂度。
渲染(Rendering)
批处理(Batching)
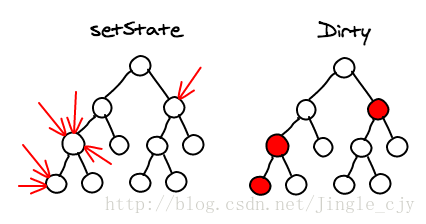
每当用户在组件上触发setState方法时,React都将其标记为dirty。在事件循环结束时,React再对所有的脏组件进行响应,并重新渲染它们。
这种批处理意味着在一次事件循环中,DOM只会被更新一次。这是构建高性能应用的关键,而在原生JS中这是难以实现的。这在React应用程序中默认设置,与生俱来。如下所示:
子树渲染(Sub-tree Rendering)
当调用setState时,组件会为其子元素重构虚拟DOM。如果在根元素上调用setState,那么整个React应用程序都需要重新渲染。所有的组件无论是否发生改变,都会调用其render方法。这看似可怕而低效,实际上,这仅仅操作了保存在内存中的虚拟DOM,而没有触及真实的DOM。
首先,我们讨论的是展示用户界面。因为屏幕代销是有限的,所以每次只能显示数百到数千个元素。JavaScript为整个界面提供了足够快的可管理的业务逻辑。
另一个重要问题是,当编写React代码时,通常不会每次发生变化都在根节点上调用setState方法。你只在那些受到事件触发的组件上调用setState方法,而很少直接在最顶端节点上调用setState方法。这意味着setState方法的调用常常局限在与用户交互的组件上,如下所示:
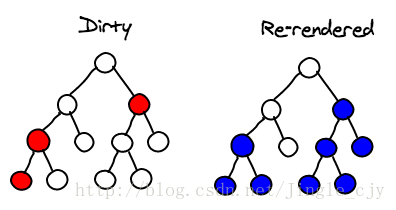
选择性的子树渲染(Selective Sub-tree Rendering)
最后,你也可以通过在组件上实现以下方法来防止其子树的渲染:
boolean shouldComponentUpdate(object nextProps, object nextState)基于组件前后的状态(props/state),你可以告诉React这个组件没有变化,所以也就没有必要重新渲染它。恰当的使用这个功能可以给应用带来巨大的性能提升。
为了能够使用该功能,你必须能够比较JS对象,但是这会带来许多问题,比如应当进行哪种程度的比较(深/浅),如果是深层次的比较,我们应当使用不可变的数据结构或者做深拷贝。
同时还要时刻警惕,这个函数会一直被不停地调用。所以无论组件是否需要重新渲染,你都要确保使用该函数所需要的时间要少于未使用此项功能而直接渲染组件所需的时间。
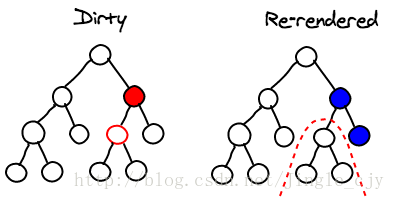
总结(Conclusion)
这个使React变快的技术并不是新技术。我们很早就知道直接操作DOM是昂贵的,应当进行批量读写操作,使用事件委托更快……
但是人们仍然在讨论这些,因为在实践中,很难再原生JavaScript代码中应用。真正使得React变得出色的是这些优化都是默认发生的。你很难把自己陷入困境,让自己的app变慢。
React的性能成本模型也很易于理解:每次setState都会重新渲染整个子树。如果你想要提升性能,应当尽可能少的调用setState,并且使用shouldComponentUpdate来防止重新渲染一个大的子树。