本文是吴恩达《深度学习》第四课《卷积神经网络》第二周课后题第二部分的实现。
0.ResNet简介
目前神经网络变得越来越复杂,从几层到几十层甚至一百多层的网络都有。深层网络的主要的优势是可以表达非常复杂的函数,它可以从不同抽象程度的层里学到特征,比如在比较低层次里学习到边缘特征而在较高层里可以学到复杂的特征。然而使用深层网络并非总是奏效,因为存在一个非常大的障碍——梯度消失:在非常深层的网络中,梯度信号通常会非常快的趋近于0,这使得梯度下降的过程慢得令人发指。具体来说就是在梯度下降的过程中,从最后一层反向传播回第一层的每一步中都要进行权重矩阵乘积运算,这样一来梯度会呈指数级下降到0值。(在极少的情况下还有梯度爆炸的问题,就是梯度在传播的过程中以指数级增长到溢出)
因此在训练的过程中,你会发现如下图所示的问题,随着层数的增加,梯度下降的0的速率增快。
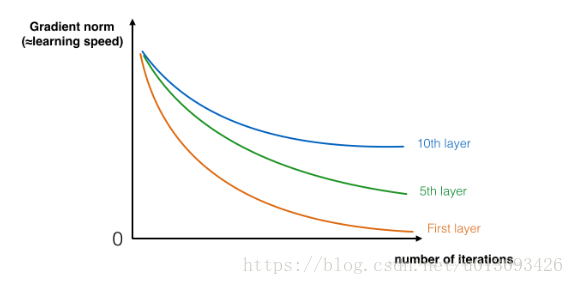
因此,通过不断加深网络虽然可以表达任何复杂的函数,但实际上随着网络层数的增多我们越发的难以训练网络,直到Residual Network的提出,使得训练更深层的网络成为可能。
本文所需的第三方库如下,所需的数据及辅助程序可点击此处下载。
import numpy as np
from keras import layers
from keras.layers import Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D
from keras.models import Model, load_model
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import preprocess_input
import pydot
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
from resnets_utils import *
from keras.initializers import glorot_uniform
import scipy.misc
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
import keras.backend as K
K.set_image_data_format('channels_last')
K.set_learning_phase(1)1.数据分析
本次准备处理的数据集是手势数字集,如下图

X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
X_train = X_train_orig / 255
X_test = X_test_orig / 255
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))number of training examples = 1080
number of test examples = 120
X_train shape: (1080, 64, 64, 3)
Y_train shape: (1080, 6)
X_test shape: (120, 64, 64, 3)
Y_test shape: (120, 6)2.Residual模块
在ResNet中最重要的模块就是“shortcut”或“skip connection”,正是因为这个模块的引入才使得更深层网络成为可能。

左图显示的是网络的主路,右图引入shortcut使得梯度可以直接反向传播到前层。引入skip connection不会影响网络表现,而且有助于效率的提升,因为新增的层可能会学到更多的有效信息,想了解具体细节可以参看吴恩达老师的视频教程。
残差块主要有两种类型,主要区别在于输入/输出是否是相同维度,下面来分别实现。
2.1.Identity块
identity块是ResNet中的标准模块,该模块的特点是输入激活值(a[l])与输出激活值(a[l+2])是相同维度。为了具体说明identity块是怎么实现的,见下图。
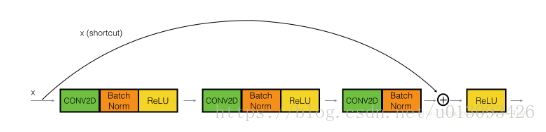
图中,下部回路表示网络传播的主路径,上部表示shortcut其跳过了三层隐藏层向后传播。每层中都有CONV2D和RELU操作,为了加快训练,还增加了Batch Norm层,这虽然使执行过程变得复杂,但是不要担心,这在Keras中只需一行代码。该模块实现起来可分四步来实现,如下:
(1)主路组件一
- CONV2D:F1过滤器shape为(1,1),strides=(1,1),padding=“valid”,name='conv_name_base+ '2a', seed=0;
- Batch Norm: 对channel标准化,name = bn_name_base + '2a'
- RELU
(2)主路组件二
- CONV2D:F1过滤器shape为(f,f),strides=(1,1),padding=“same”,name='conv_name_base+ '2b', seed=0;
- Batch Norm: 对channel标准化,name = bn_name_base + '2b'
- RELU
(3)主路组件三
- CONV2D:F1过滤器shape为(1,1),strides=(1,1),padding=“valid”,name='conv_name_base+ '2c', seed=0;
- Batch Norm: 对channel标准化,name = bn_name_base + '2c'
(4)求和激活
- 将shortcut和主路值相加到一起,然后应用RELU函数激活。
def identity_block(X, f, filters, stage, block):
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
F1, F2, F3 = filters
X_shortcut = X
X = Conv2D(filters = F1, kernel_size = (1,1), strides = (1,1), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed = 0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X)
X = Conv2D(filters = F2, kernel_size = (f,f), strides = (1,1), padding = 'same', name = conv_name_base + '2b', kernel_initializer = glorot_uniform(seed = 0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2b')(X)
X = Activation('relu')(X)
X = Conv2D(filters = F3, kernel_size = (1,1), strides = (1,1), padding = 'valid', name = conv_name_base + '2c', kernel_initializer = glorot_uniform(seed = 0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2c')(X)
X = Add()([X, X_shortcut])
X = Activation('relu')(X)
return Xtf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
A_prev = tf.placeholder("float", [3,4,4,6])
X = np.random.randn(3,4,4,6)
A = identity_block(A_prev, f = 2, filters = [2,4,6], stage = 1, block = 'a')
sess.run(tf.global_variables_initializer())
out = sess.run([A], feed_dict = {A_prev:X, K.learning_phase():0})
print("out = " + str(out[0][1][1][0]))out = [0.19716819 0. 1.3561226 2.1713073 0. 1.3324987 ]2.2.convolutional块
当输入输出的维度不同时,就需要使用convolutional块来解决这个问题,它与identity块最大的不同是在shortcut回路增加了CONV2D操作,其起到的作用就是达叔教程中所讲的Ws,可以将输入X改变成后续相加操作中所需要的维度,如下图所示。
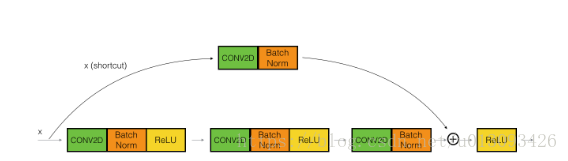
convolutional块实现起来共分5个步骤:
(1)主路组件一
- CONV2D:F1过滤器shape为(1,1),strides=(s,s),padding=“valid”,name='conv_name_base+ '2a';
- Batch Norm: 对channel标准化,name = bn_name_base + '2a'
- RELU
(2)主路组件二
- CONV2D:F1过滤器shape为(f,f),strides=(1,1),padding=“same”,name='conv_name_base+ '2b';
- Batch Norm: 对channel标准化,name = bn_name_base + '2b'
- RELU
(3)主路组件三
- CONV2D:F1过滤器shape为(1,1),strides=(1,1),padding=“valid”,name='conv_name_base+ '2c', seed=0;
- Batch Norm: 对channel标准化,name = bn_name_base + '2c'
(4)shortcut回路
- CONV2D:F3过滤器shape为(1,1),strides=(s,s),padding=“valid”,name='conv_name_base+ '1';
- Batch Norm: 对channel标准化,name = bn_name_base + '1'
(5)求和激活
- 将shortcut和主路值相加到一起,然后应用RELU函数激活。
def convolutional_block(X, f, filters, stage, block, s=2):
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
F1, F2, F3 = filters
X_shortcut = X
X = Conv2D(filters = F1, kernel_size = (1,1), strides = (s,s), name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed = 0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X)
X = Conv2D(filters = F2, kernel_size = (f,f), strides = (1,1), padding = 'same', name = conv_name_base + '2b', kernel_initializer = glorot_uniform(seed = 0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2b')(X)
X = Activation('relu')(X)
X = Conv2D(filters = F3, kernel_size = (1,1), strides = (1,1), name = conv_name_base + '2c', kernel_initializer = glorot_uniform(seed = 0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2c')(X)
X_shortcut = Conv2D(F3, (1,1), strides = (s,s), name = conv_name_base + '1', kernel_initializer = glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis = 3, name=bn_name_base + '1')(X_shortcut)
X = Add()([X, X_shortcut])
X = Activation('relu')(X)
return Xtf.reset_default_graph()
with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float", [3, 4, 4, 6])
X = np.random.randn(3, 4, 4, 6)
A = convolutional_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})
print("out = " + str(out[0][1][1][0]))
out = [0. 1.1676219 0.16150603 0. 0. 0.61365455]3. 构建ResNet模型
现在我们已经有了可以构造非常深层的ResNet的模块了,下面我们来构造一个拥有50层的ResNet网络。其整体架构如下图:
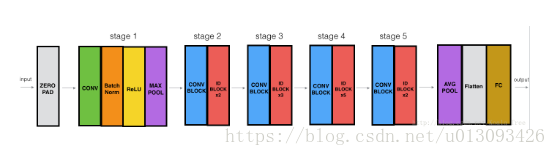
其中ID block x3表示该模块是由3个Identity块堆叠构成,该模型各层参数设置如下:
Zero-Padding: P = (3, 3)
Stage 1:
Conv2D:64个fileter, f = (7,7),strides = (2,2),name=conv1
BatchNorm:对channel标准化
MaxPooling: f = (3, 3), strides = (2, 2)
Stage 2:
Convolution block:filter = 3,size = [64,64,256], f = 3, s = 1, block = a
ID block 2x:filter = 3, size = [64,64,256], f = 3, block = b, c
Stage 3:
Convolution block:filter = 3,size = [128, 128, 512], f = 3, s = 2, block = a
ID block 3x:filter = 3, size = [128, 128, 512], f = 3, block = b, c,d
Stage 4:
Convolution block:filter = 3,size = [256, 256, 1024], f = 3, s = 2, block = a
ID block 5x:filter = 3, size = [256, 256, 1024], f = 3, block = b, c,d,e,f
Stage 5:
Convolution block:filter = 3,size = [512, 512, 2048], f = 3, s = 2, block = a
ID block 2x:filter = 3, size = [512, 512, 2048], f = 3, block = b, c
AveragePooling: f = (2, 2), name = "avg_pool"
Flatten:None
FC: softmax, name = 'fc' + str(classes)
def ResNet50(input_shape = (64, 64, 3), classes = 6):
X_input = Input(input_shape)
X = ZeroPadding2D((3, 3))(X_input)
X = Conv2D(64, (7, 7), strides = (2,2), name = 'conv1', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = 'bn_conv1')(X)
X = Activation('relu')(X)
X = MaxPooling2D((3, 3), strides = (2,2))(X)
X = convolution_block(X, f = 3, filters = [64,64,256], stage = 2, block = 'a', s = 1)
X = identity_block(X, 3, [64,64,256], stage=2, block='b')
X = identity_block(X, 3, [64,64,256], stage=2, block='c')
X = convolution_block(X, f = 3, filters = [128,128,512], stage = 3, block = 'a', s = 2)
X = identity_block(X, 3, [128,128,512], stage=3, block='b')
X = identity_block(X, 3, [128,128,512], stage=3, block='c')
X = identity_block(X, 3, [128,128,512], stage=3, block='d')
X = convolution_block(X, f = 3, filters = [256,256,1024], stage = 4, block = 'a', s = 2)
X = identity_block(X, 3, [256,256,1024], stage=4, block='b')
X = identity_block(X, 3, [256,256,1024], stage=4, block='c')
X = identity_block(X, 3, [256,256,1024], stage=4, block='d')
X = identity_block(X, 3, [256,256,1024], stage=4, block='e')
X = identity_block(X, 3, [256,256,1024], stage=4, block='f')
X = convolution_block(X, f = 3, filters = [512,512,2048], stage = 5, block = 'a', s = 2)
X = identity_block(X, 3, [512,512,2048], stage=5, block='b')
X = identity_block(X, 3, [512,512,2048], stage=5, block='c')
X = AveragePooling2D((2, 2), name='avg_pool')(X)
X = Flatten()(X)
X = Dense(classes, activation = 'softmax', name = 'fc' + str(classes), kernel_initializer = glorot_uniform(seed=0))(X)
model = Model(inputs = X_input, outputs = X, name = 'ResNet50')
return model我们现在已经搭建好了ResNet50网络,在Keras框架中实现训练/测试模型一共分如下步骤:
(1)创建model
model = ResNet50(input_shape = (64, 64, 3), classes = 6)(2)编译model
model.compile(optimizer='adam', loss = 'categorical_crossentropy', metrics=['accuracy'])(3)训练model
model.fit(X_train, Y_train, epochs = 2, batch_size = 32)Epoch 1/2
1080/1080 [==============================] - 392s 363ms/step - loss: 3.2793 - acc: 0.1991
Epoch 2/2
1080/1080 [==============================] - 441s 408ms/step - loss: 2.5464 - acc: 0.2852由于训练用时较长,在此我们只训练了2代,因而取得的loss和acc都比较差,如果将迭代的次数增加到20时,我们会取得很好的训练效果,不过这在CPU上训练需要花费1个多小时。
(4)评估model
preds = model.evaluate(X_test, Y_test)
print('Loss = ' + str(preds[0]))
print('Test Accuracy =' + str(preds[1]))Loss = 1.3768339474995932
Test Accuracy =0.699999996026357现在我们会导入使用GPU训练好的模型参数进行训练,用时约1min
model = load_model('ResNet50.h5')
preds = model.evaluate(X_test, Y_test)
print('Loss = ' + str(preds[0]))
print('Test Accuracy =' + str(preds[1]))20/120 [==============================] - 14s 113ms/step
Loss = 0.2556911051273346
Test Accuracy =0.9166666706403096
可见,训练速度和精度都很高。
4.手势识别
现在我们训练好了模型,可以利用这个模型测试一下自己的手势,看看识别的精度。
img_path = 'images\\myfigure.jpg'
img = image.load_img(img_path, target_size = (64,64))
x = image.img_to_array(img)
x = np.expand_dims(x, axis = 0)
x = preprocess_input(x)
print('Input image shape:', x.shape)
my_image = scipy.misc.imread(img_path)
imshow(my_image)
plt.show()
print('class prediction vector [p(0),p(1),p(2),p(3),p(4),p(5)] =')
print(model.predict(x))Input image shape: (1, 64, 64, 3)
class prediction vector [p(0),p(1),p(2),p(3),p(4),p(5)] =
[[9.9407300e-02 5.5689206e-03 8.9319646e-01 8.8972512e-05 1.0773229e-03
6.6105300e-04]]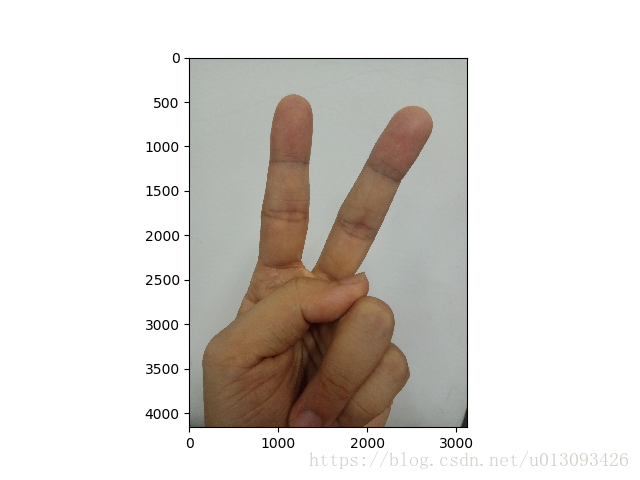
从运行结果中可见预测结果中p(2)=8.9319464e-1,是输出中最大的值,即识别的结果为2,与图片吻合。
我们可以将模型中各层的参数列出来(截取片段),如下表:
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 64, 64, 3) 0
__________________________________________________________________________________________________
zero_padding2d_1 (ZeroPadding2D (None, 70, 70, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
conv1 (Conv2D) (None, 32, 32, 64) 9472 zero_padding2d_1[0][0]
__________________________________________________________________________________________________
bn_conv1 (BatchNormalization) (None, 32, 32, 64) 256 conv1[0][0]
__________________________________________________________________________________________________
activation_4 (Activation) (None, 32, 32, 64) 0 bn_conv1[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 15, 15, 64) 0 activation_4[0][0]
__________________________________________________________________________________________________
res2a_branch2a (Conv2D) (None, 15, 15, 64) 4160 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
bn2a_branch2a (BatchNormalizati (None, 15, 15, 64) 256 res2a_branch2a[0][0]
__________________________________________________________________________________________________
activation_5 (Activation) (None, 15, 15, 64) 0 bn2a_branch2a[0][0]
__________________________________________________________________________________________________
res2a_branch2b (Conv2D) (None, 15, 15, 64) 36928 activation_5[0][0]
__________________________________________________________________________________________________
bn2a_branch2b (BatchNormalizati (None, 15, 15, 64) 256 res2a_branch2b[0][0]
__________________________________________________________________________________________________
activation_6 (Activation) (None, 15, 15, 64) 0 bn2a_branch2b[0][0]
__________________________________________________________________________________________________
res2a_branch2c (Conv2D) (None, 15, 15, 256) 16640 activation_6[0][0]
__________________________________________________________________________________________________
res2a_branch1 (Conv2D) (None, 15, 15, 256) 16640 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
bn2a_branch2c (BatchNormalizati (None, 15, 15, 256) 1024 res2a_branch2c[0][0]
__________________________________________________________________________________________________
bn2a_branch1 (BatchNormalizatio (None, 15, 15, 256) 1024 res2a_branch1[0][0]
__________________________________________________________________________________________________
add_2 (Add) (None, 15, 15, 256) 0 bn2a_branch2c[0][0]
bn2a_branch1[0][0]
__________________________________________________________________________________________________
activation_7 (Activation) (None, 15, 15, 256) 0 add_2[0][0]
__________________________________________________________________________________________________
res2b_branch2a (Conv2D) (None, 15, 15, 64) 16448 activation_7[0][0]
__________________________________________________________________________________________________
bn2b_branch2a (BatchNormalizati (None, 15, 15, 64) 256 res2b_branch2a[0][0]
__________________________________________________________________________________________________
activation_8 (Activation) (None, 15, 15, 64) 0 bn2b_branch2a[0][0]
__________________________________________________________________________________________________
res2b_branch2b (Conv2D) (None, 15, 15, 64) 36928 activation_8[0][0]
__________________________________________________________________________________________________
bn2b_branch2b (BatchNormalizati (None, 15, 15, 64) 256 res2b_branch2b[0][0]
__________________________________________________________________________________________________
activation_9 (Activation) (None, 15, 15, 64) 0 bn2b_branch2b[0][0]
__________________________________________________________________________________________________
res2b_branch2c (Conv2D) (None, 15, 15, 256) 16640 activation_9[0][0]
__________________________________________________________________________________________________
bn2b_branch2c (BatchNormalizati (None, 15, 15, 256) 1024 res2b_branch2c[0][0]
__________________________________________________________________________________________________
add_3 (Add) (None, 15, 15, 256) 0 bn2b_branch2c[0][0]
activation_7[0][0]
__________________________________________________________________________________________________
activation_10 (Activation) (None, 15, 15, 256) 0 add_3[0][0]
__________________________________________________________________________________________________
res2c_branch2a (Conv2D) (None, 15, 15, 64) 16448 activation_10[0][0]
__________________________________________________________________________________________________
bn2c_branch2a (BatchNormalizati (None, 15, 15, 64) 256 res2c_branch2a[0][0]
__________________________________________________________________________________________________
activation_11 (Activation) (None, 15, 15, 64) 0 bn2c_branch2a[0][0]
__________________________________________________________________________________________________
res2c_branch2b (Conv2D) (None, 15, 15, 64) 36928 activation_11[0][0]
__________________________________________________________________________________________________
bn2c_branch2b (BatchNormalizati (None, 15, 15, 64) 256 res2c_branch2b[0][0]
__________________________________________________________________________________________________
activation_12 (Activation) (None, 15, 15, 64) 0 bn2c_branch2b[0][0]
__________________________________________________________________________________________________
res2c_branch2c (Conv2D) (None, 15, 15, 256) 16640 activation_12[0][0]
__________________________________________________________________________________________________
bn2c_branch2c (BatchNormalizati (None, 15, 15, 256) 1024 res2c_branch2c[0][0]
__________________________________________________________________________________________________
add_4 (Add) (None, 15, 15, 256) 0 bn2c_branch2c[0][0]
activation_10[0][0]
__________________________________________________________________________________________________
activation_13 (Activation) (None, 15, 15, 256) 0 add_4[0][0]
__________________________________________________________________________________________________
res3a_branch2a (Conv2D) (None, 8, 8, 128) 32896 activation_13[0][0]
__________________________________________________________________________________________________
bn3a_branch2a (BatchNormalizati (None, 8, 8, 128) 512 res3a_branch2a[0][0]
__________________________________________________________________________________________________
activation_14 (Activation) (None, 8, 8, 128) 0 bn3a_branch2a[0][0]
__________________________________________________________________________________________________
res3a_branch2b (Conv2D) (None, 8, 8, 128) 147584 activation_14[0][0]
__________________________________________________________________________________________________
bn3a_branch2b (BatchNormalizati (None, 8, 8, 128) 512 res3a_branch2b[0][0]
__________________________________________________________________________________________________
activation_15 (Activation) (None, 8, 8, 128) 0 bn3a_branch2b[0][0]
__________________________________________________________________________________________________
res3a_branch2c (Conv2D) (None, 8, 8, 512) 66048 activation_15[0][0]
__________________________________________________________________________________________________
res3a_branch1 (Conv2D) (None, 8, 8, 512) 131584 activation_13[0][0]
__________________________________________________________________________________________________
bn3a_branch2c (BatchNormalizati (None, 8, 8, 512) 2048 res3a_branch2c[0][0]
__________________________________________________________________________________________________
bn3a_branch1 (BatchNormalizatio (None, 8, 8, 512) 2048 res3a_branch1[0][0]
__________________________________________________________________________________________________
.......
.......
Total params: 23,600,006
Trainable params: 23,546,886
Non-trainable params: 53,120我们可以将该表保存为.png
plot_model(model, to_file = 'model.png')
SVG(model_to_dot(model).create(prog = 'dot', format = 'svg'))5.总结
(1)