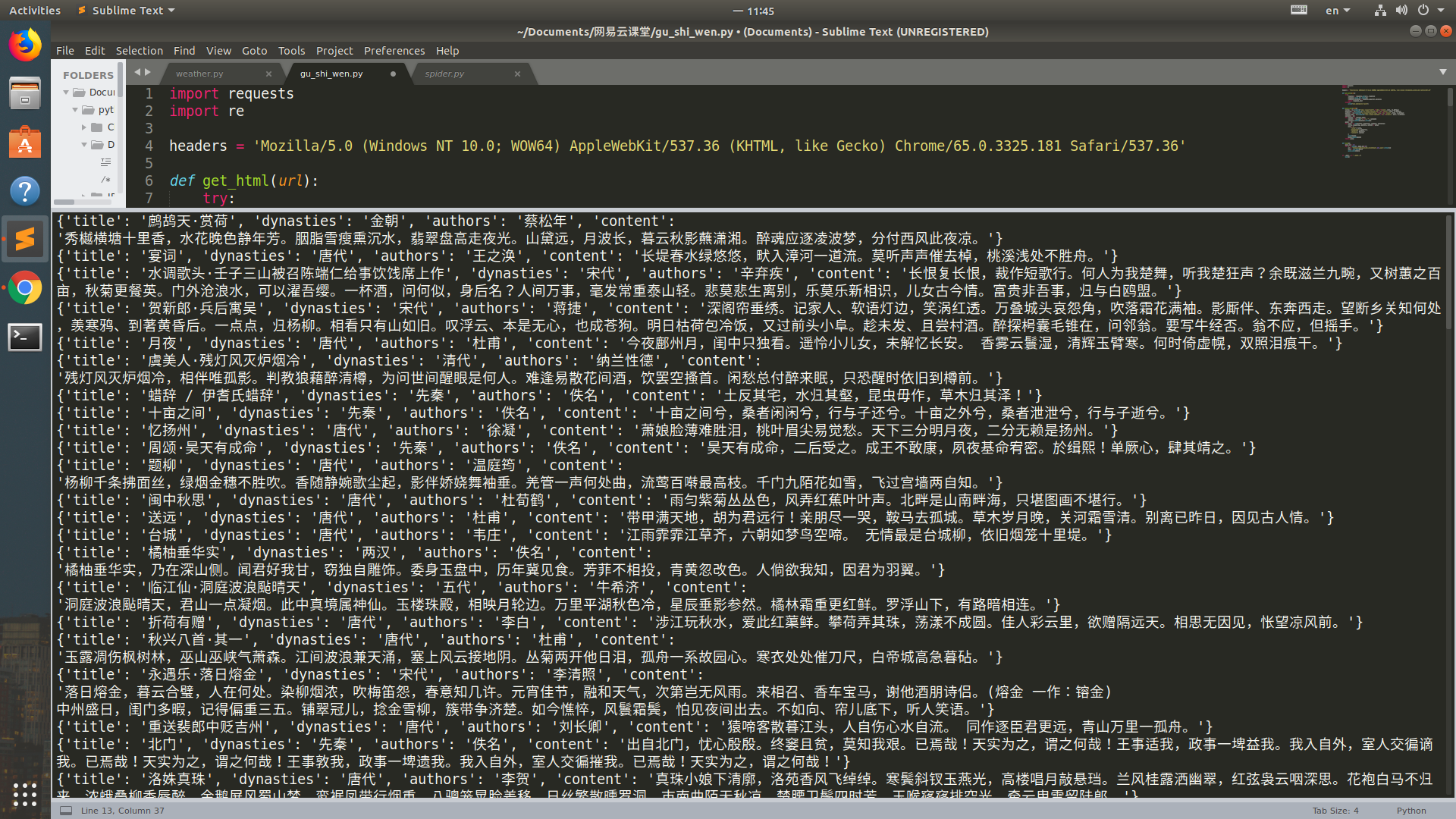
程序中请求到的和网页中内容不一样,但也是古诗,不是道是不是因为请求头的原因,使得网站推荐的古诗有差异
1 import requests 2 import re 3 4 headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' 5 6 def get_html(url): 7 try: 8 response = requests.get(url, headers) 9 response.raise_for_status() 10 response.encoding = response.apparent_encoding 11 return response.text 12 except: 13 print('get_html(url) faild') 14 15 16 def parse_html(html): 17 titles = re.findall(r'<div class="cont">.*?<b>(.*?)</b>', html, re.DOTALL) 18 dynasties = re.findall(r'<p class="source"><a.*?>(.*?)</a>', html, re.DOTALL) 19 authors = re.findall(r'<p class="source"><a.*?><a.*?>(.*?)</a>', html, re.DOTALL) 20 content_tags = re.findall(r'<div class="contson".*?>(.*?)</div>', html, re.DOTALL) 21 contents = [] 22 for content in content_tags: 23 content = re.sub(r'<.*?>', '', content) 24 contents.append(content.strip()) 25 poems = [] 26 for value in zip(titles, dynasties, authors, contents): 27 title, dynasties, authors, content = value 28 poem = { 29 'title': title, 30 'dynasties': dynasties, 31 'authors': authors, 32 'content': content 33 } 34 print(poem) 35 poems.append(poem) 36 return poems 37 38 39 def main(): 40 page_num = 10 41 for i in range(1, page_num+1): 42 url = 'https://www.gushiwen.org/default_{0}.aspx'.format(i) 43 html = get_html(url) 44 parse_html(html) 45 46 47 if __name__ == '__main__': 48 main()
运行结果