正则的一个实例,提取古诗文网https://www.gushiwen.org/default_1.aspx的诗文。
参照课程写的。
1 import re 2 import requests 3 4 5 def parse_page(url): 6 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} 7 response = requests.get(url,headers=headers) 8 text = response.text 9 # print(text) 10 values = re.findall( 11 '<p><a style="font-size.*? target="_blank"><b>(.+?)</b></a>[\s\S]*?target="_blank">(.+?)</a><span>.+? ' 12 'target="_blank">(.+?)</a></p>[\s\S]+?<div class="contson".+?>\n([\s\S]+?)\n</div>', text) 13 14 poems = [] 15 for value in values: 16 title, dynasty, author, content = value 17 # 替换br为换行 ,,有些诗文中会有<p>标签要去掉 18 content = re.sub('<br />', '\n', content) 19 content = re.sub('<.*?>', '', content) 20 poem = { 21 'title': title, 22 'dynasty': dynasty, 23 'author': author, 24 'content': content 25 } 26 poems.append(poem) 27 return poems 28 29 30 def main(): 31 url = 'https://www.gushiwen.org/default_1.aspx' 32 poems = parse_page(url) 33 print(poems) 34 35 36 if __name__ == '__main__': 37 main()
老师课程中代码是将标题、朝代、作者、内容分开获取的,然后用zip函数将多个列表组合成一个元祖列表。
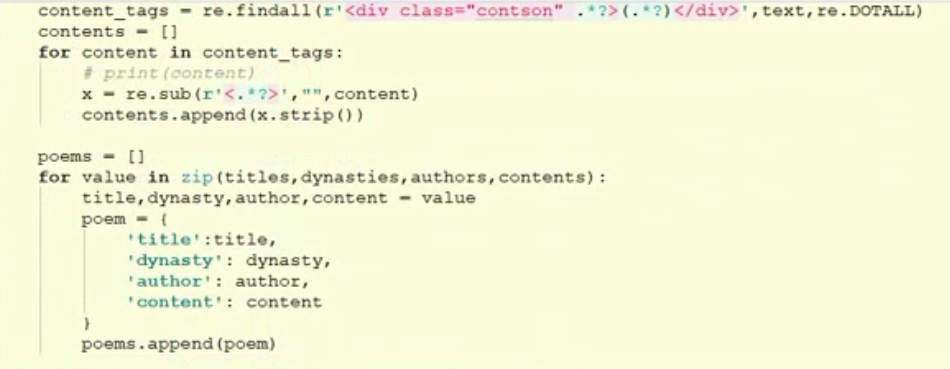
备忘点
一、zip函数,可以将多个列表组合成一个元祖的列表

二、
title, dynasty, author, content = value可以直接将元祖value中的元素分别赋值
三、
re.findall(pattern, text, re.DOTALL)正则中点.不能匹配换行,可以使用[\s\S]表示所有字符,或者可以使用re.DOTALL或re.S标志就可以使点.表示所有字符了
首先想到的是[.\n]表示,可是不能匹配,查百度发现原来是[.]表示的就只是点.这一个字符了.所以不行.