最近有点空余时间,在项目中也经常遇到集合相关的代码,今天利用时间对集合框架中,常用的几个集合进行梳理,首先对hashmap进行梳理,好对其中的概念,和使用技巧进行增强。
1、hashmap 的继承体系
查看 HashMap类,可以看到
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable{}
hashMap 继承了 AbstractMap 方法,并实现了Map ,Cloneable, Serializable接口 ,
AbstractMap 中,AbstractMap 实现了Map 接口,有这么一下属性 和方法
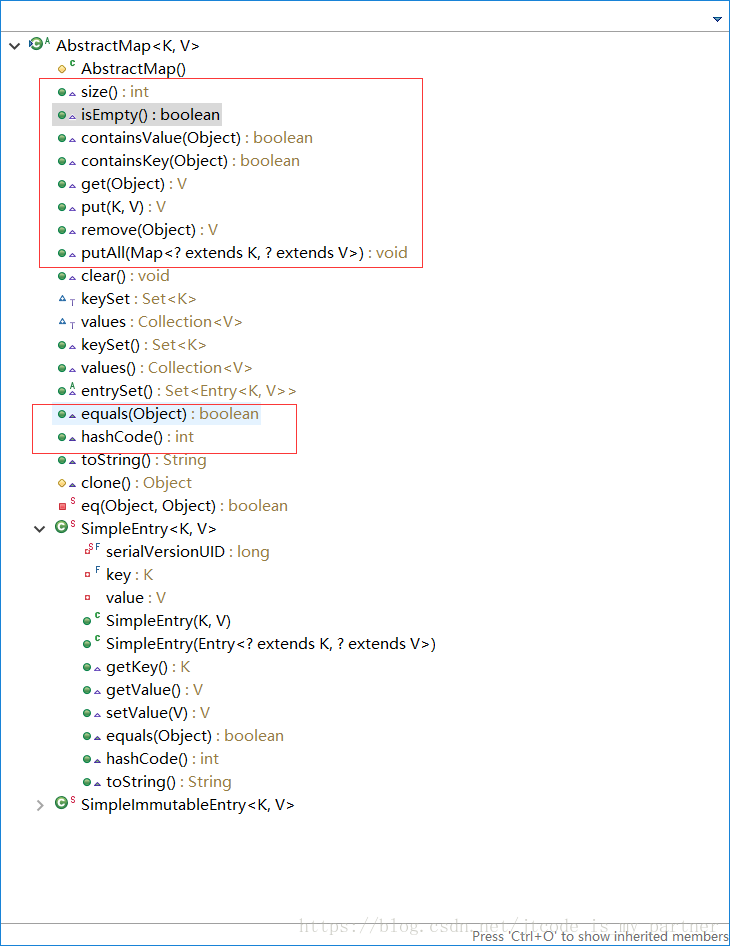
Map 接口
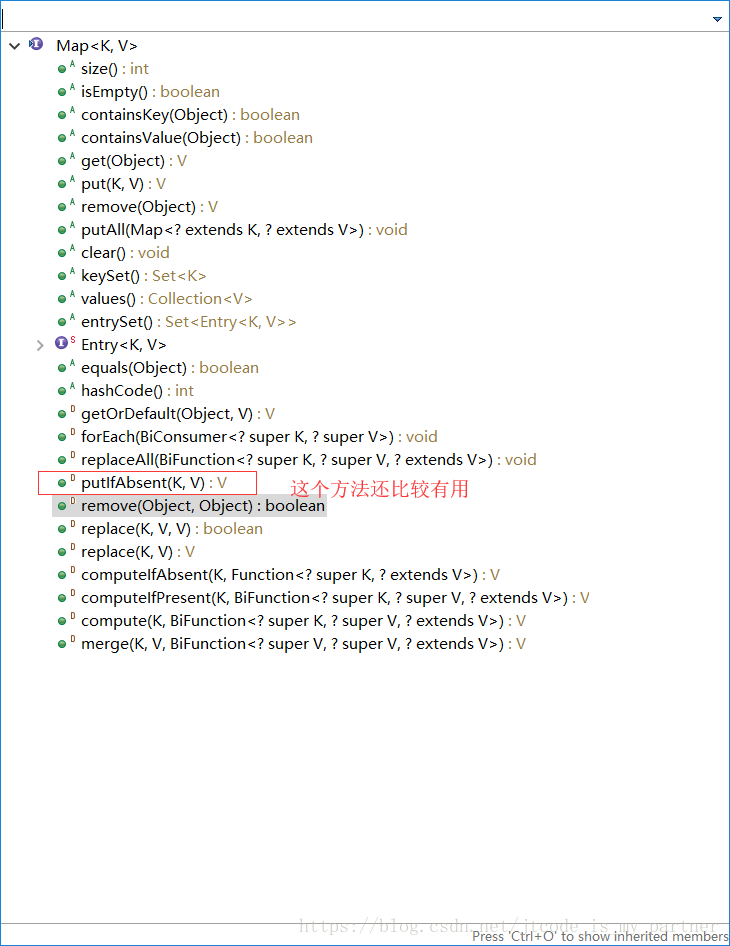
Cloneable接口 Serializable接口,表示该类是可以被clone 的 以及可以被序列化的。

继承体系看完了,我们再来探究一下hashMap 类的内部是怎么样的。
2、查看hashMap 类,映入眼帘的是一些静态常量
/**
* 默认的初始容量,
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* 最大的容量
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 装载因子,
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 该参数就比较重要了,涉及了一个重要概念,就是hashmap 的同一个hashcode 节点上数据的存储方式转变,
* 该值是链表转为树存储的阈值,如果节点上多余了8个,则改为树存储,这样有利于查询操作。
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 该参数和上面的阈值概念相似,不过是由树转变为链表的阈值,
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* 链表转换为树结构的最小表容量,也就是说,当某个节点,即使超过了上面所说的8个节点值时,但表容量没有超过64,则 *仍然以链表来存储,只是 进行表格的扩容。
*/
static final int MIN_TREEIFY_CAPACITY = 64;
3、 研究一个数据结果,首先得知道,其底层用的什么来存储,源码可以看到,其底层有这么一个属性
/**
* 数据存储的表格,
*/
transient Node<K,V>[] table;
没错,其底层就是用的数组来进行存储的,数组中存储的是一个node 节点类型。数组的大小有一个初始容量,就扩容因此来确定,
然后再来看看这个Node<K,V>类型,该类型为一个静态内部类,

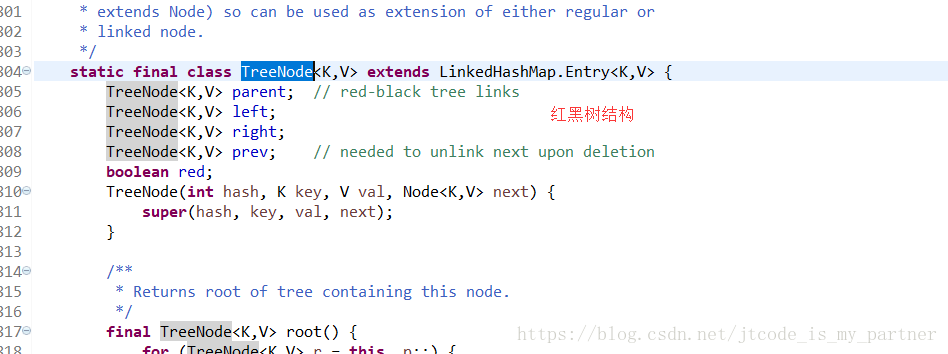
从这些内部类,我们可以大致的知道,底层的存储方式为 数组+ (链表/ 红黑树的结构)
4、值是怎么存储到相应的数组位置和链表的机构中的。
类中有一个put 方法,其底层调用的是putvalue 方法


该方法中有几个需要介绍的是,hash 值的获取,根据key 值进行获取,

链表转树的代码
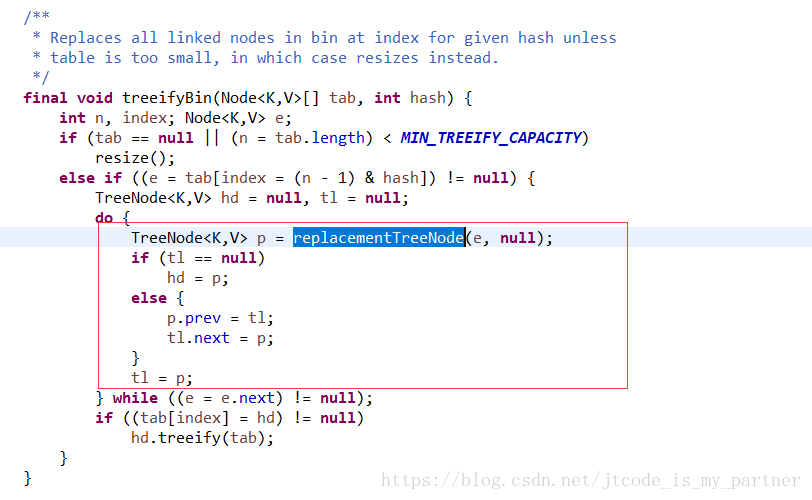
5、说了这么多存储的代码,再来看看获取指定key 又是怎么实现,其实和存储很类似,都是根据key 值获取相应的hash值,然后找到相应的数组位置,再在链表或者是红黑树里面查找
final Node<K,V> getNode(int hash, Object key) { // 根据hash 值 和key 值,找到相应的节点,
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key); 如果是树节点,则根据树的规则取找节点
do { //不是则按照链表规则找节点
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) //首先看hash值是否相等,其次看key 值是否相同
return e;
} while ((e = e.next) != null); 依次向后找节点。
}
}
return null;
}
6. 总结
上面主要对hashmap 的底层存储结构进行分析,知道了其是按照 数组加链表或者是红黑树的方式来存储的,同时其存储的机理是按照key 值及其hash 值来存储到相应的位置的, 同时对源代码进行了增加和查询这两个操作进行了探索,虽然没有完全对代码进行分析,但其他的分析过程也相似。