摘要
HashMap是Java开发人员使用频率最高的一种数据类型。Java在实现键值对映射时定义了一个接口java.util.Map,此接口主要有四个常用的实现类,分别是HashMap、Hashtable、LinkedHashMap和TreeMap。JDK1.8对HashMap底层的实现进行了优化,比较重要的是引入红黑树的数据结构和扩容的优化。
HashMap根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,理想情况下的访问速度是O(1)。HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap是线程不安全的,即任一时刻可以有多个线程同时写HashMap,可能导致数据的不一致。另外,HashMap的遍历顺序是不确定的,如果需要保证顺序,可以用LinkedHashMap;如果并发需要保证线程安全,可以用ConcurrentHashMap。
存储模型
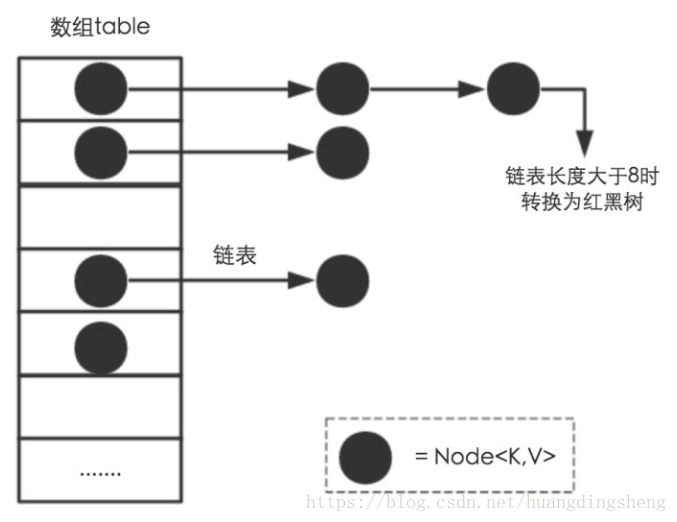
HashMap用哈希表来存储。哈希表为解决冲突,一般采用开发地址法和链地址法解决问题。HashMap采用了链地址法。简单来说就是数组加链表的结合。在每个数组元素上放上一个链表结构,当待存数据被hash后,得到数组下标,把数据放在对应下标元素的链表上。当两个数据被hash到相同位置时,表示发生了hash碰撞。理想情况下,空间足够大,可以认为没有hash冲突,存取的时间复杂度都是O(1)。但是,内存空间有限,必然会存在哈希冲突。所以HashMap要在空间成本和时间成本之间权衡,需要有好的hash算法和扩容机制。
hash算法
首先,我们需要清楚源码里已经实现的两个策略:
1.hash取模时,用的是位运算(按位与"&")
2.数组初始化容量是16(2的4次方),扩容时也会以大于且最接近指定值大小的2次幂来初始化。
JDK1.8源码摘取:
// 取模
static int indexFor(int h, int length) {
return h & (length-1);
}
- 1
- 2
- 3
- 4
// 扩容时的容量计算 Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
- 1
- 2
- 3
- 4
分析:
- 显然,因为"模"运算的消耗还是比较大的,用位运算替代是个不错的优化选择。
- 为什么数组的容量要保持2的幂次方?
有两个原因
1)支持取模时的位运算(数学规律)
2)效率
举个例子:
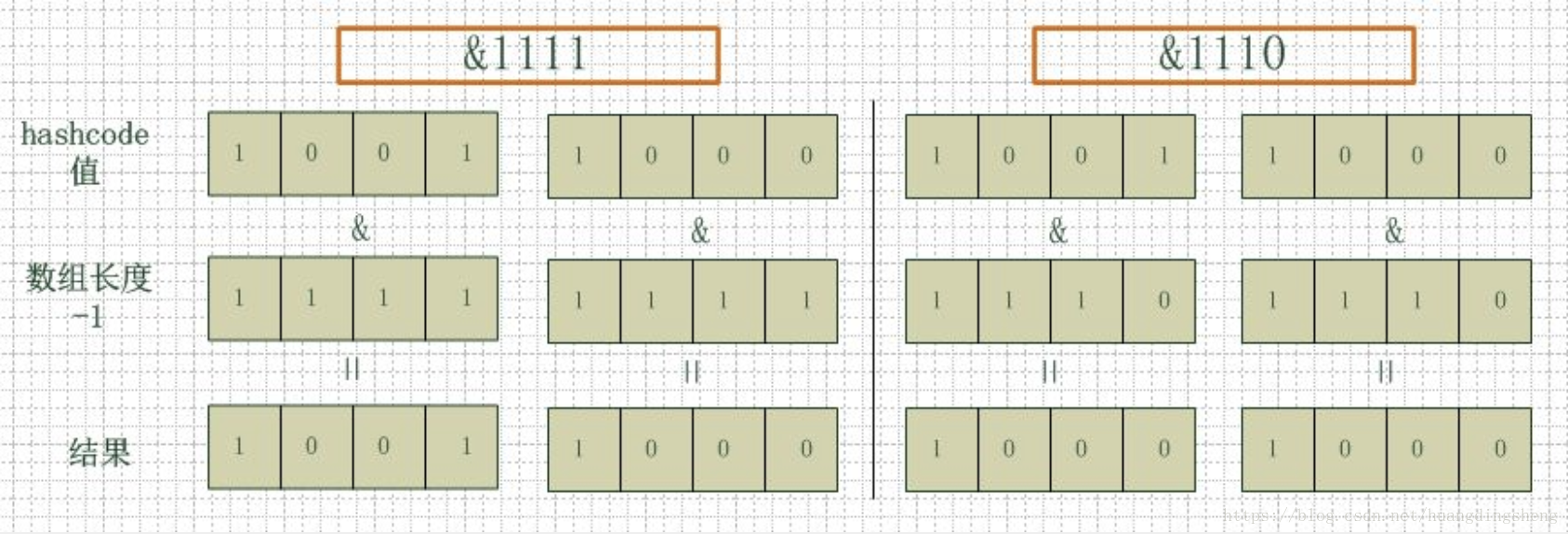
如上图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率。
扩容时的resize问题
HashMap扩容时最消耗性能的点:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
HashMap什么时候进行扩容?当HashMap中的元素个数超过数组大小和扩容因子loadFactor的乘积时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过160.75=12的时候,就把数组的大小扩展为216=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size >1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
引入红黑树的原因
HashMap的查询、插入、修改、删除平均时间复杂度都是O(1)。最坏的情况是所有的key都散列到一个Entry中,时间复杂度会退化成O(N)。这就是为什么Java8的HashMap引入了红黑树的原因。当Entry中的链表长度超过8,链表会进化成红黑树。红黑树是一个自平衡二叉查找树,它的查询/插入/修改/删除的平均时间复杂度为O(log(N))。
小结
1)扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
2)负载因子是可以修改的,也可以大于1,但是建议不要轻易修改,除非情况非常特殊。
3)HashMap是线程不安全的,不要在并发的环境中同时操作HashMap,建议使用ConcurrentHashMap。
4)JDK1.8引入红黑树大程度优化了HashMap的性能。
5)HashMap的key为null时不会报空指针异常,但Hashtable会。
参考资料:
1.JDK1.8源码.
2.红黑联盟,Java类集框架之HashMap(JDK1.8)源码剖析,2015. https://www.2cto.com/kf/201505/401433.html
3.深入理解HashMap. http://www.iteye.com/topic/539465
4.美团点评技术团队 Java 8系列之重新认识HashMap https://zhuanlan.zhihu.com/p/21673805