python3爬虫之访问量、点击率数据的爬取分析
1.明确问题:


通过开发者工具分析我们可以看出,这个点击率并不是‘静态数据’,而是一个脚本返回,那么这个数据到底藏在哪里呢?
经验告诉我,不是Doc 就在Js找,如果还找不到,那很有可能就在XHR(Ajax的一种用法 即异步加载)中了,果不其然,通过查找确定我们要的数据在这里:
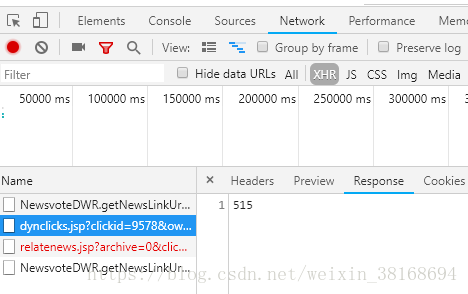
2.该怎么取回数据呢?
分析Header:

我们可以确定网址,那么这个网址有什么特点呢?
http://www2017.tyut.edu.cn/system/resource/code/news/click/dynclicks.jsp?clickid=9578&owner=1353264808&clicktype=wbnews
经过规律总结,我发现clickid={}&owner={}这两个值是不停变化的,其他的部分并没有动。
那这两个值是怎么变化的呢?返回去找原文章点击量的脚本,我发现
点击率:[<script>_showDynClicks("wbnews", **1353264808**, **9578**)</script>]次</span></div>
这时候我们可以确定怎么取数据了
3.数据取法:
x = soup.select('.xxxx script')[0].text.replace(' ', '').strip(')').split(',')
resulturl = 'http://www2017.tyut.edu.cn/system/resource/code/news/click/dynclicks.jsp?clickid={}&owner={}&clicktype=wbnews'.format(
x[2], x[1])
count = BeautifulSoup(requests.get(resulturl).text, 'html.parser')4.结果验证(由于时间过去了一会儿导致点击率又增加了ps:好像很多人看的样子QAQ):
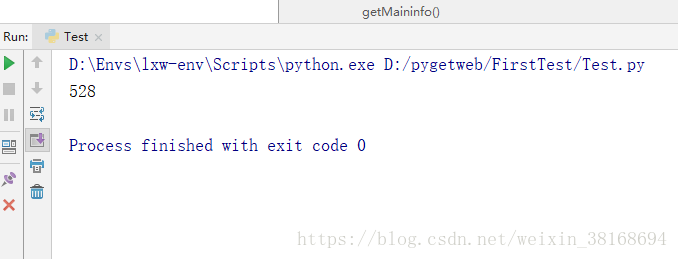
5.心得小结:
到这里python3爬虫项目实战就告一段落了,本人一天6更啊(跟写小说似的),在项目实战中,你应该掌握
- python爬虫环境搭建
- 利用requests库获取全部html目标代码
- 利用BeautifulSoup4解析你想要的部分并脱去标签
- 利用函数、for循环等实现‘自动化’批量爬取数据
- 获取数据的回传
- 最后用Pandas库生成长期可存储数据文件