前言
Python中能够爬虫的包还有很多,但requests号称是“让HTTP服务人类”...口气不小,但的确也很好用。
本文是博客里爬虫的第一篇,实现一个很简单的功能:获取自己博客主页里的访问量。
当然了,爬虫一般肯定逃不掉要用正则表达式(regular expression),因此Python的re包也是十分常用的。
分析
打开博客园网站并登录,点击左边“我的随笔”:
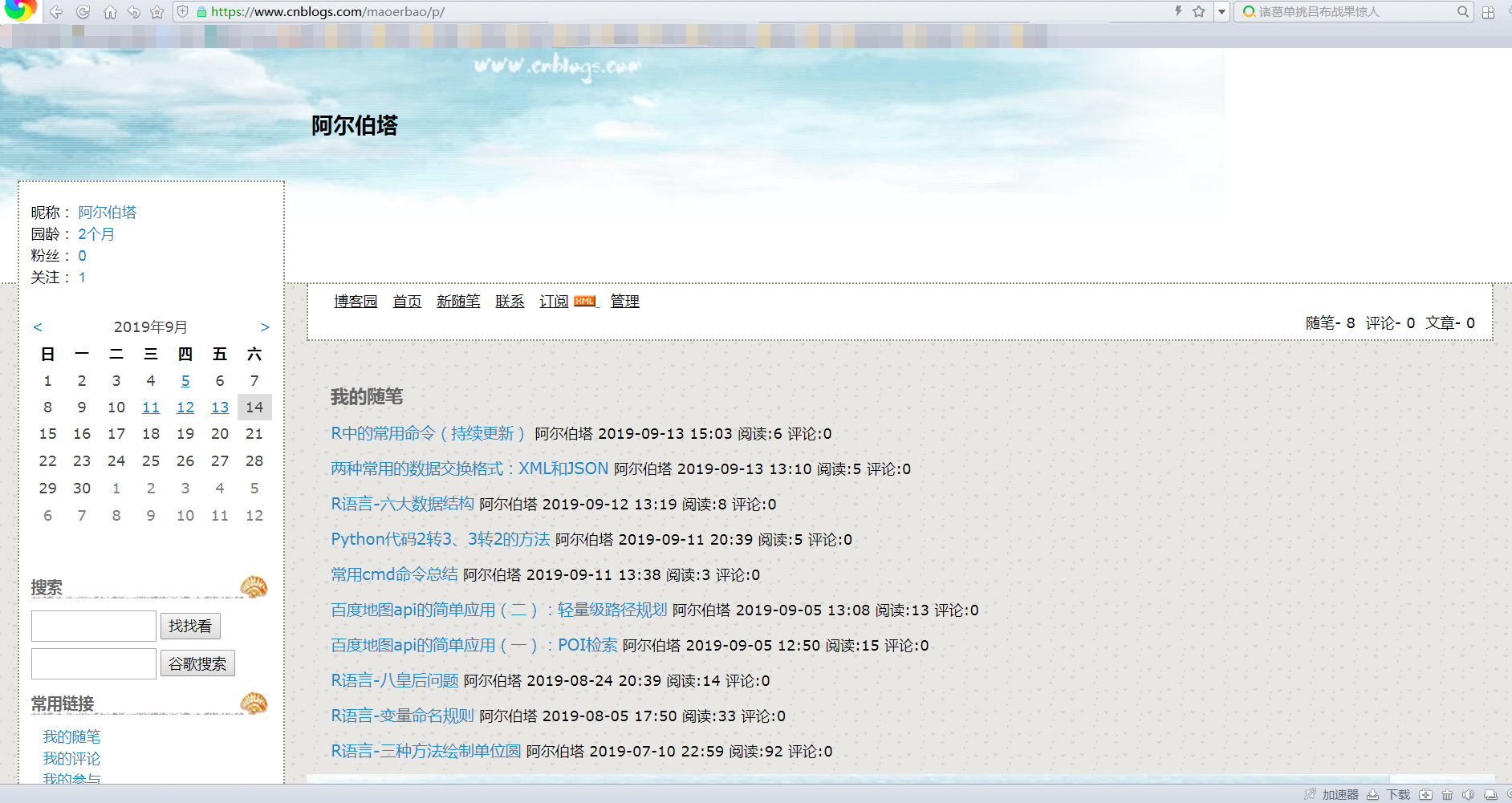
点击F12可以查看网页源代码:
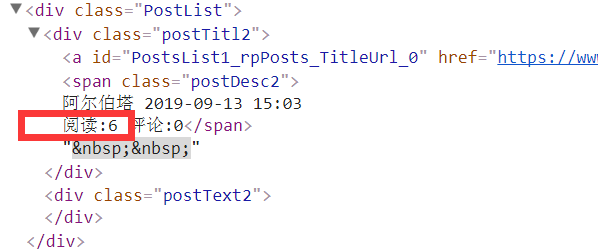
然后发现每一篇的阅读量表现为“阅读:”+数字,注意这里的冒号是英文,数字的位数不确定。
正则表达式中,数字用'\d'描述即可,
出现0-n次用'*',出现0-n次用'+',出现0-1次用'?',
在这里,“阅读:”后面必定有数字,因此用'*'或'+'皆可以。
代码
import requests import re url = 'https://cnblogs.com/maoerbao/p/' #我所有随笔集合的网址 f = requests.get(url).text #获取html页面内容,并转换成文本 a = re.findall('阅读:\d*',f) #正则表达式,提取每篇的阅读量 zydl = 0 L = [] for i in a: ydl = int(i[3:]) zydl = ydl + zydl L.append(ydl) print('阿尔伯塔的博客:\n') print('总篇数:%d'%len(L)) print('总阅读量:%d'%zydl) print('最大单篇阅读量:%d'%max(L)) print('最小单篇阅读量:%d'%min(L))
运行结果
