一、设计方案
1.爬虫名称:爬取百度热榜
2.爬取内容:爬取网页热搜排名,标题,热度值。
3.方案概述:访问网页得到状态码200,分析网页源代码,找出所需要的的标签,逐个提取标签保存到相同路径csv文件中,读取改文件,进行数据清洗,数据模型分析,数据可视化处理,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和绘制拟合曲线。
技术难点:做数据分析,即求回归系数,因为标题是文字,无法与数字作比较,需要把标题这一列删除才可。由于不明原因,输出结果经常会显示超出列表范围。
二、主题页面的结构特征分析
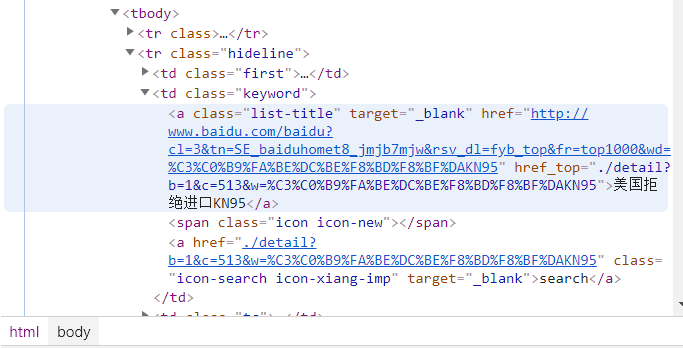
1.主题页面的结构与特征分析:发现前三的排名标签是‘span.num-top’ 第四名开始的标签又是‘span.num-normal’,所以找统一的标签,即' td.first '.标题标签为' a.list-title '.热度标签 ' span.icon-rise '.
2.页面解析:
三、
1.
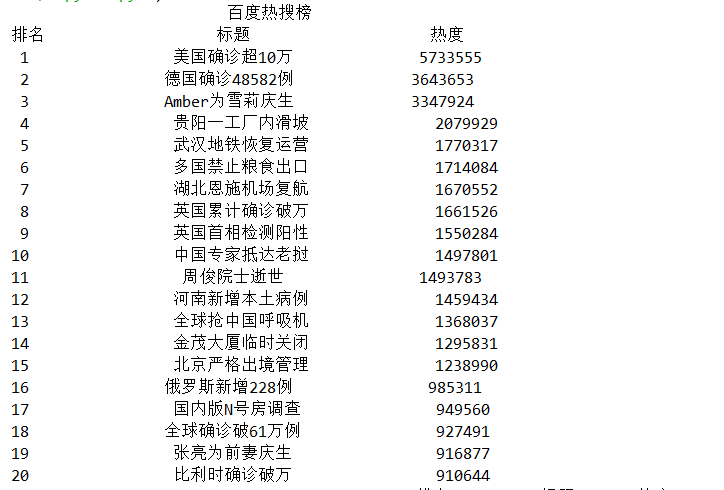
#获取html网页 url = 'http://top.baidu.com/buzz.php?p=top10&tdsourcetag=s_pctim_aiomsg&qq-pf-to=pcqq.c2c?' header={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36', 'Referer': 'http://top.baidu.com/'} #请求超时时间为30秒 r = requests.get(url,timeout = 30,headers=header) #如果状态码不是200,则引发日常 r.raise_for_status() #配置编码 r.encoding = r.apparent_encoding #获取源代码 r.text html=r.text soup=BeautifulSoup(html,'html.parser') title = soup.find_all('a', class_='list-title') point = soup.find_all('span', class_='icon-rise') print('{:^55}'.format('百度热搜榜')) print('{:^5}\t{:^40}\t{:^10}'.format('排名', '标题', '热度')) num = 20 lst = [] for i in range(num): print('{:^5}\t{:^40}\t{:^10}'.format(i+1, title[i].string, point[i].string)) lst.append([i+1,title[i].string,point[i].string]) df = pd.DataFrame(lst,columns=['排名','标题','热度']) rank = r'rank.xlsx' df.to_excel(rank)
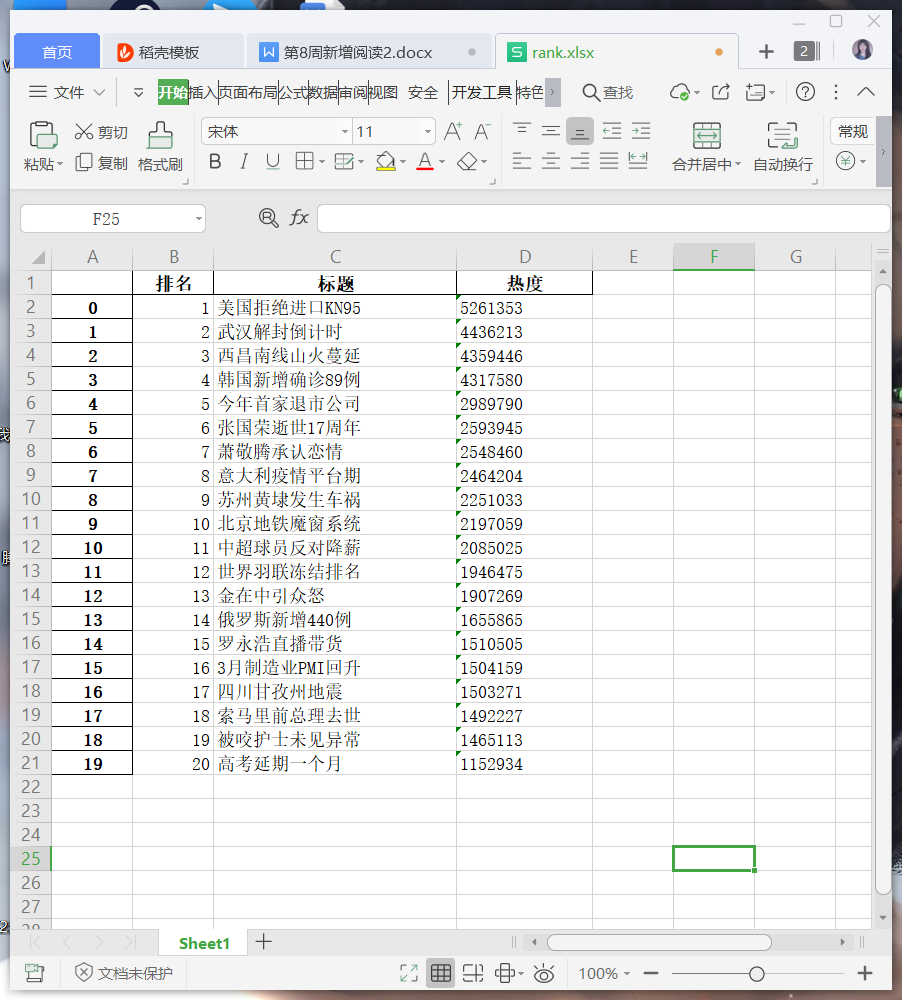
2.
#读取csv文件 rank=pd.DataFrame(pd.read_excel('rank.xlsx')) print(rank.head())

3.
#删除无效列 #rank.drop('标题',axis=1,inplace=True) #print(rank.head)
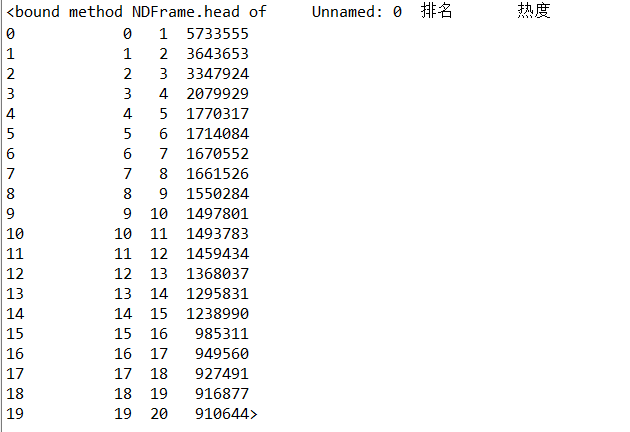
4.
#检查是否有重复值 print(rank.duplicated())

5.
#检查是否有空值 print(rank['热度'].isnull().value_counts())
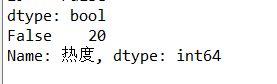
6.
#异常值处理 print(rank.describe()) #发现“热度”字段的最大值为4457381而平均值为1301384,假设异常值为4457381 print(top.replace([4457381,top['热度'].mean()]))
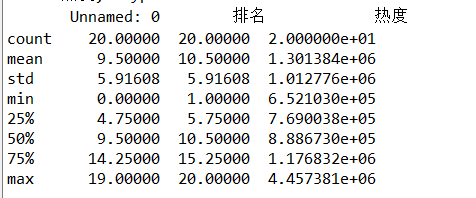
7.
#数据分析 from sklearn.linear_model import LinearRegression X = df.drop("标题",axis=1) predict_model = LinearRegression() predict_model.fit(X,df['热度']) print("回归系数为:",predict_model.coef_)
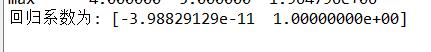
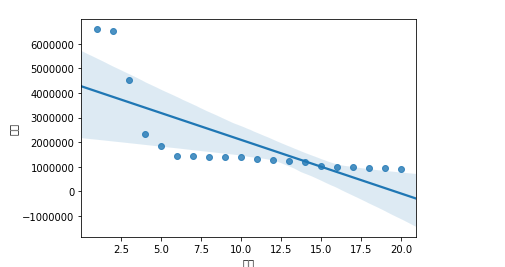
8.
#绘制排名与热度的回归图 import seaborn as sns sns.regplot(rank_df.排名,rank_df.热度)
9.
#画出散点图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 N=10 x=np.random.rand(N) y=np.random.rand(N) size=50 plt.xlabel("排名") plt.ylabel("热度") plt.scatter(x,y,size,color='r',alpha=0.5,marker="o") #散点图 kind='reg' sns.jointplot(x="排名",y="热度",data=rank,kind='reg') # kind='hex' sns.jointplot(x="排名",y="热度",data=rank,kind='hex') # kind='kde' sns.jointplot(x="排名",y="热度",data=rank,kind="kde",space=0,color='g')
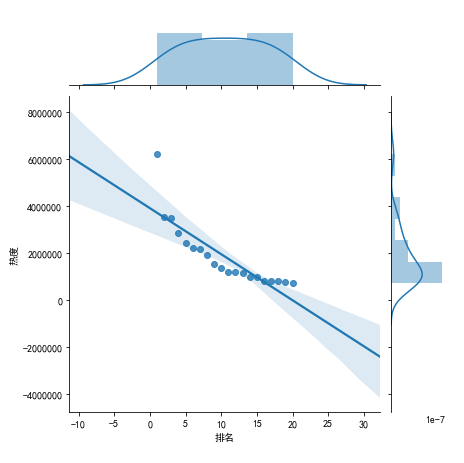
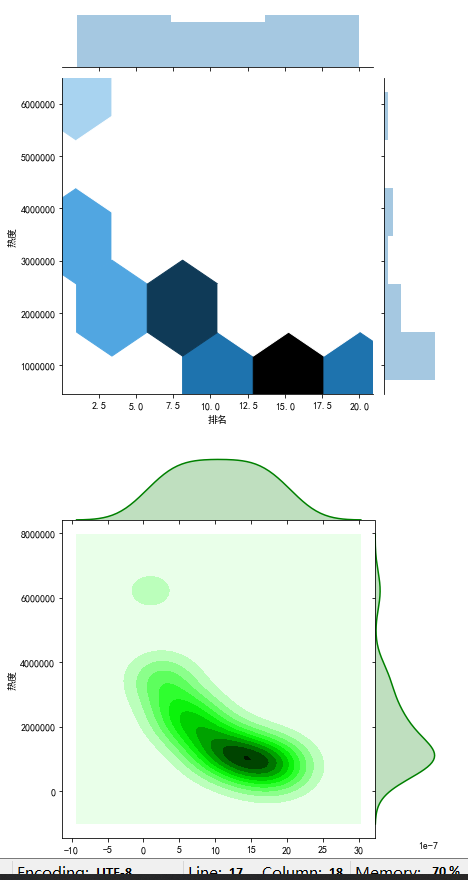
10.
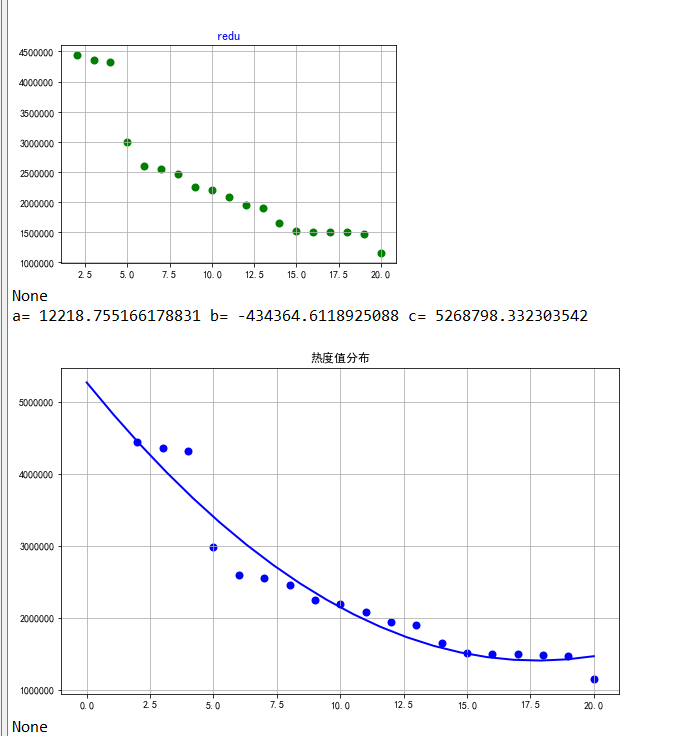
#选择排名和热度两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 colnames=[" ","排名","标题","热度"] df = pd.read_excel('rank.xlsx',skiprows=1,names=colnames) X = df.排名 Y = df.热度 Z = df.标题 def A(): plt.scatter(X,Y,color="blue",linewidth=2) plt.title("RM scatter",color="blue") plt.grid() plt.show() def B(): plt.scatter(X,Y,color="green",linewidth=2) plt.title("redu",color="blue") plt.grid() plt.show() def func(p,x): a,b,c=p return a*x*x+b*x+c def error(p,x,y): return func(p,x)-y def main(): plt.figure(figsize=(10,6)) p0=[0,0,0] Para = leastsq(error,p0,args=(X,Y)) a,b,c=Para[0] print("a=",a,"b=",b,"c=",c) plt.scatter(X,Y,color="blue",linewidth=2) x=np.linspace(0,20,20) y=a*x*x+b*x+c plt.plot(x,y,color="blue",linewidth=2,) plt.title("热度值分布") plt.grid() plt.show() print(A()) print(B()) print(main())
四、完整代码
from bs4 import BeautifulSoup import requests import pandas as pd import time import random from matplotlib import pyplot as plt import numpy as np from numpy import genfromtxt import matplotlib.pyplot as plt import matplotlib from scipy.optimize import leastsq #睡眠 模拟用户 time.sleep(1+random.random()) #获取html网页 url = 'http://top.baidu.com/buzz.php?p=top10&tdsourcetag=s_pctim_aiomsg&qq-pf-to=pcqq.c2c?' header={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36', 'Referer': 'http://top.baidu.com/'} #请求超时时间为30秒 r = requests.get(url,timeout = 30,headers=header) #如果状态码不是200,则引发日常 r.raise_for_status() #配置编码 r.encoding = r.apparent_encoding #获取源代码 r.text html=r.text soup=BeautifulSoup(html,'html.parser') title = soup.find_all('a', class_='list-title') point = soup.find_all('span', class_='icon-rise') print('{:^55}'.format('百度热搜榜')) print('{:^5}\t{:^40}\t{:^5}'.format('排名', '标题', '热度')) num = 20 lst = [] for i in range(num): print('{:^5}\t{:^40}\t{:^5}'.format(i+1, title[i].string, point[i].string)) lst.append([i+1,title[i].string,point[i].string]) df = pd.DataFrame(lst,columns=['排名','标题','热度']) rank = r'rank.xlsx' df.to_excel(rank) #读取csv文件 rank=pd.DataFrame(pd.read_excel('rank.xlsx')) print(rank.head()) #删除无效列 #rank.drop('标题',axis=1,inplace=True) #print(rank.head) #检查是否有重复值 print(rank.duplicated()) #检查是否有空值 print(rank['热度'].isnull().value_counts()) #异常值处理 print(rank.describe()) #发现“热度”字段的最大值为4457381而平均值为1301384,假设异常值为4457381 #print(top.replace([4457381,top['热度'].mean()])) #数据分析 from sklearn.linear_model import LinearRegression X = df.drop("标题",axis=1) predict_model = LinearRegression() predict_model.fit(X,df['热度']) print("回归系数为:",predict_model.coef_) #绘制排名与热度的回归图 import seaborn as sns #sns.regplot(rank_df.排名,rank_df.热度) #画出散点图 # 用来正常显示中文标签 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示负号 plt.rcParams['axes.unicode_minus'] = False N=10 x=np.random.rand(N) y=np.random.rand(N) size=50 plt.xlabel("排名") plt.ylabel("热度") plt.scatter(x,y,size,color='r',alpha=0.5,marker="o") #散点图 kind='reg' sns.jointplot(x="排名",y="热度",data=rank,kind='reg') # kind='hex' sns.jointplot(x="排名",y="热度",data=rank,kind='hex') # kind='kde' sns.jointplot(x="排名",y="热度",data=rank,kind="kde",space=0,color='g') #选择排名和热度两个特征变量,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和拟合曲线 colnames=[" ","排名","标题","热度"] df = pd.read_excel('rank.xlsx',skiprows=1,names=colnames) X = df.排名 Y = df.热度 Z = df.标题 def A(): plt.scatter(X,Y,color="blue",linewidth=2) plt.title("RM scatter",color="blue") plt.grid() plt.show() def B(): plt.scatter(X,Y,color="green",linewidth=2) plt.title("redu",color="blue") plt.grid() plt.show() def func(p,x): a,b,c=p return a*x*x+b*x+c def error(p,x,y): return func(p,x)-y def main(): plt.figure(figsize=(10,6)) p0=[0,0,0] Para = leastsq(error,p0,args=(X,Y)) a,b,c=Para[0] print("a=",a,"b=",b,"c=",c) plt.scatter(X,Y,color="blue",linewidth=2) x=np.linspace(0,20,20) y=a*x*x+b*x+c plt.plot(x,y,color="blue",linewidth=2,) plt.title("热度值分布") plt.grid() plt.show() print(A()) print(B()) print(main())
五、总结
1.经过对数据的分析和可视化,从回归方程和拟合曲线可以看出散点大部分都落在曲线上,说明热度是随着排名的递增而递增的。又从散点图可以看出热度大部分停留在1-2W之间。
2.小结:在这次对百度热榜的分析的过程中,我从中学会了不少函数及用法。很多次都卡在一个点上,绞尽脑汁去想解决问题的办法,通过观看b站的视频,百度搜索等方法去找寻答案。这两个星期来也养成了耐心和独立思考的习惯,并且提高了我对Python的兴趣。