参考网站: https://github.com/znxlwm/pytorch-generative-model-collections
GAN的发展史及paper: http://blog.csdn.net/u013369277/article/details/60954170
1、CGAN (Condition GAN)
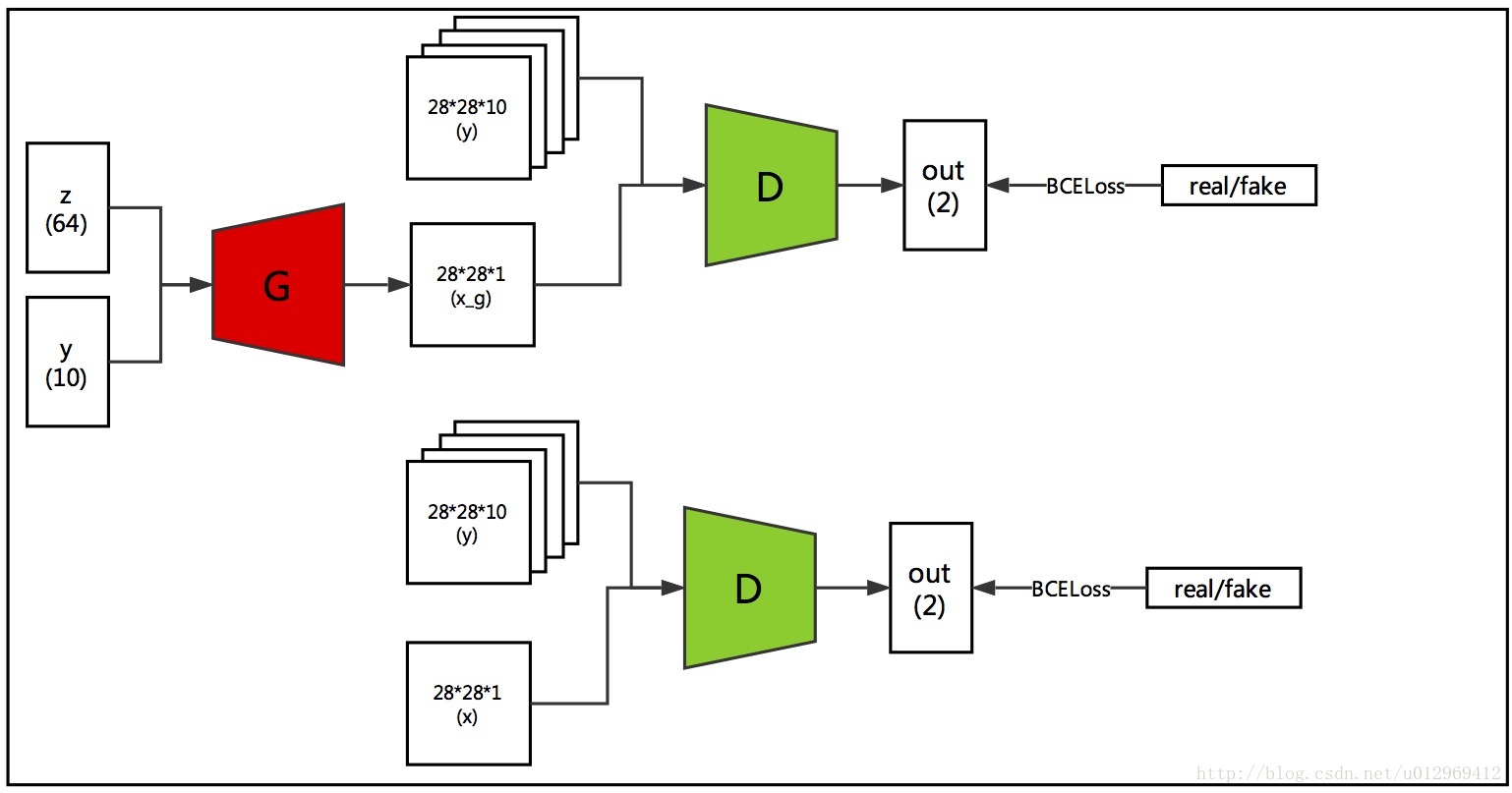
2、ACGAN (Auxiliary Classifier GAN)
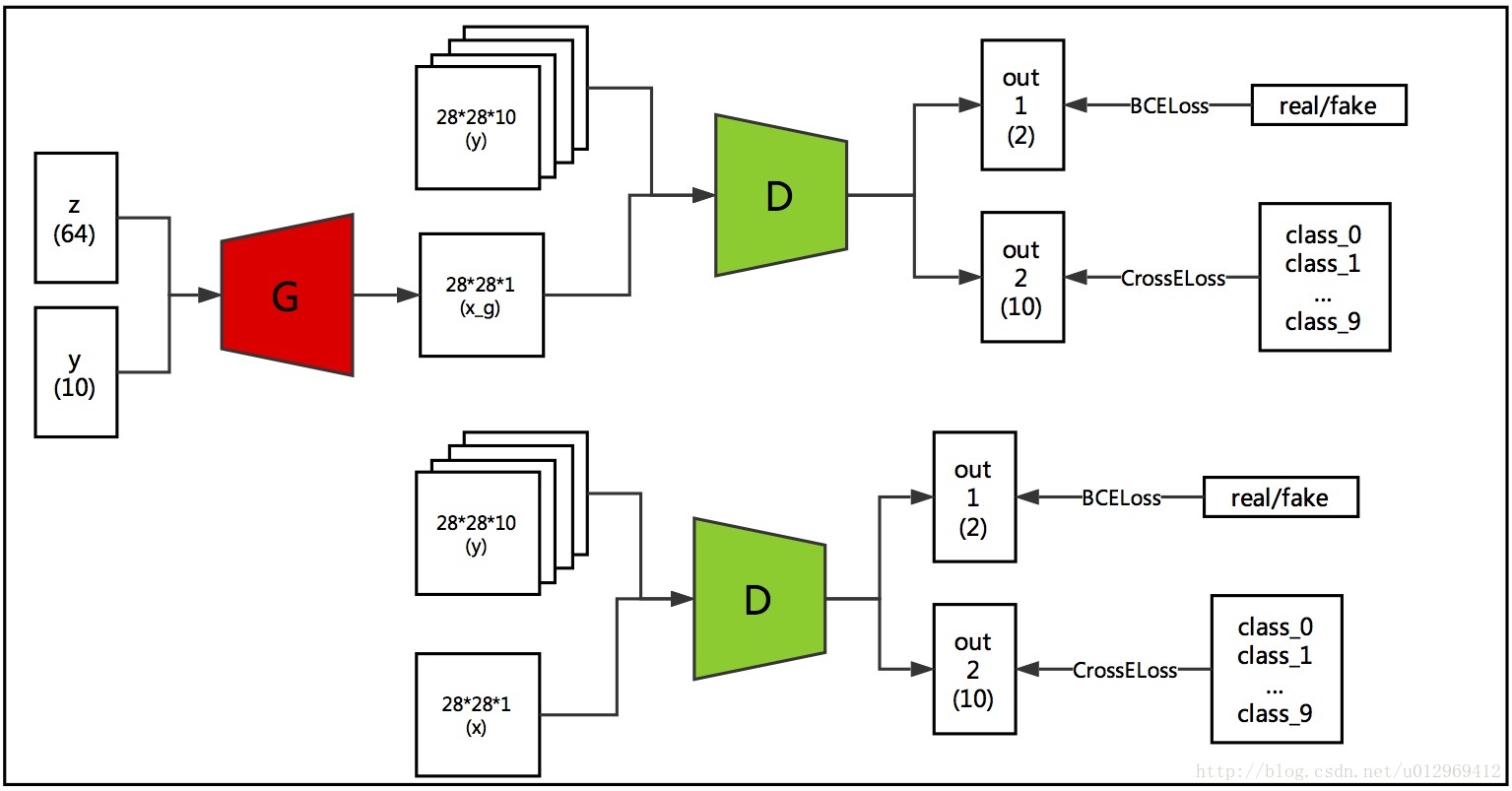
3、GAN used in Semantic Segmentation
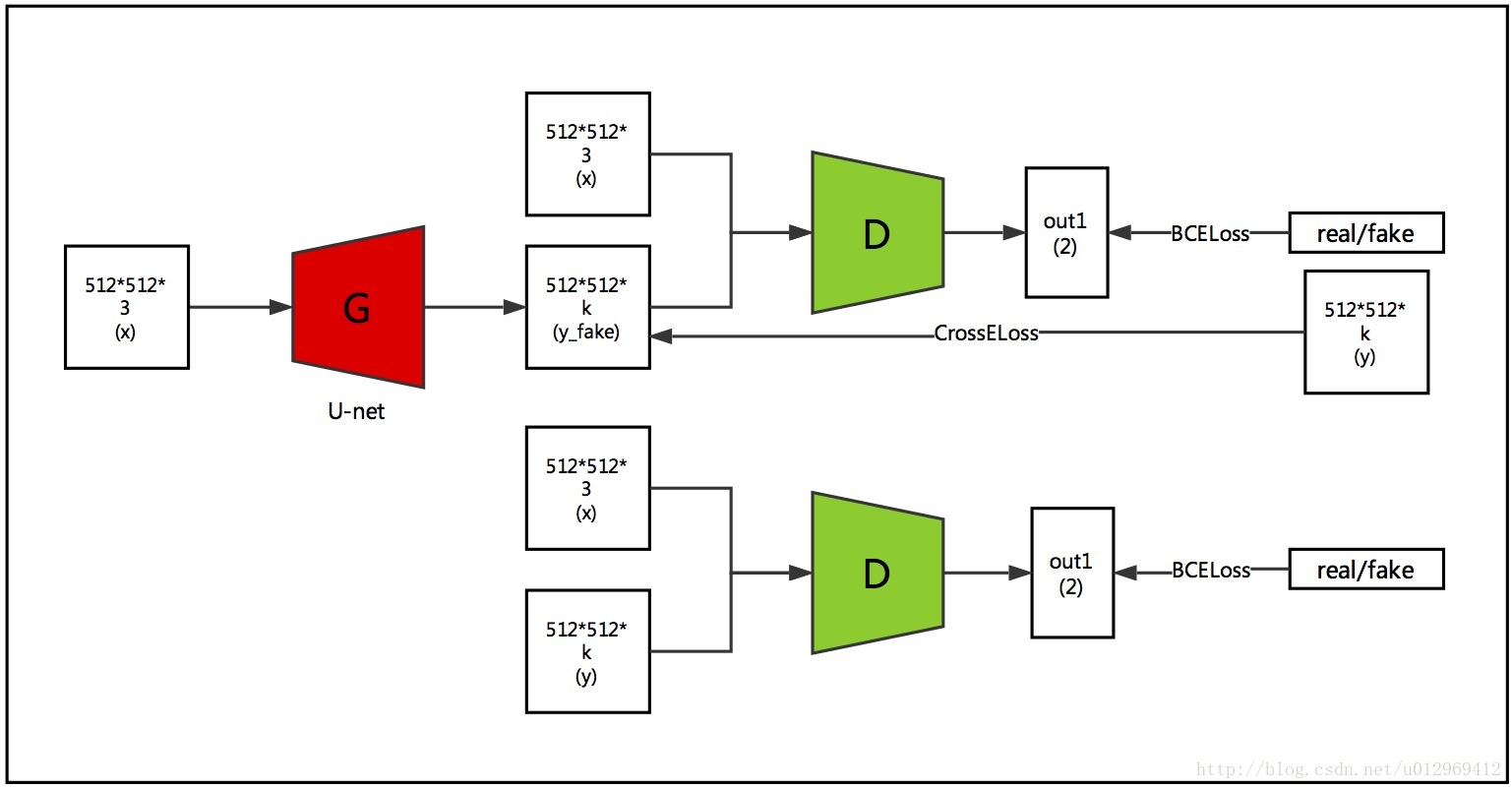


4 、Semi-Supervised GAN
参考地址:https://blog.csdn.net/shenxiaolu1984/article/details/75736407
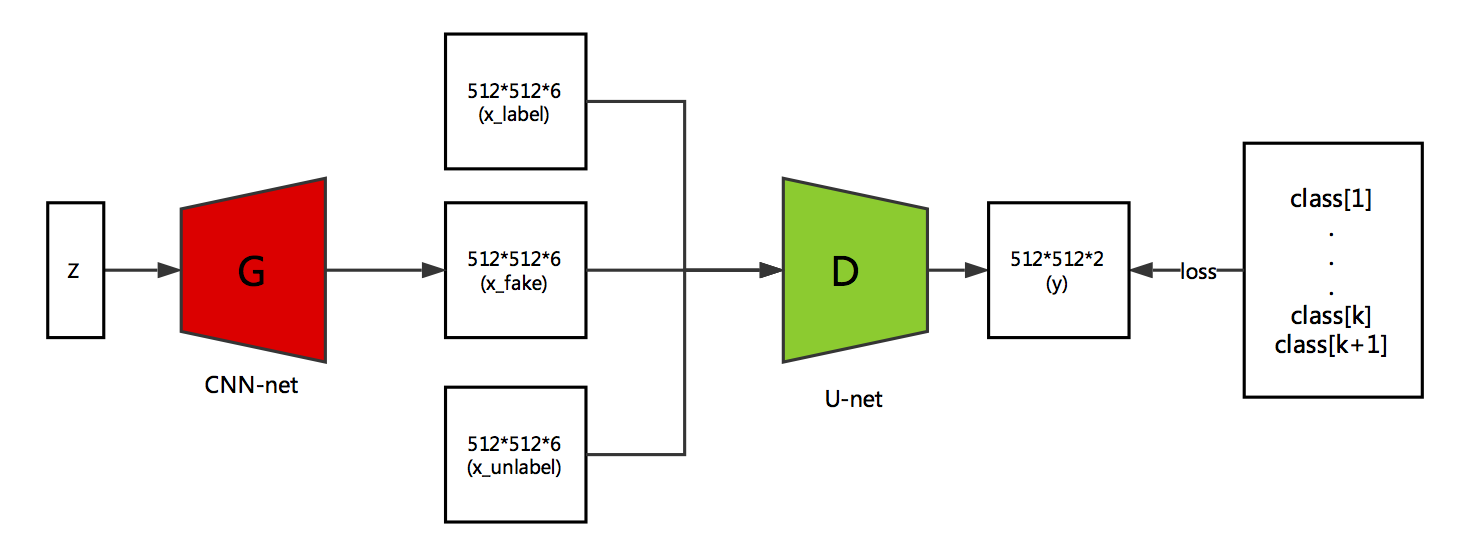
z为随机噪声100维随机向量,G是卷积网络,输出512*512*6(自由设计大小)大小的图像x_fake. 鉴别器是我们最终需要的分割模型,分割类别为K类,但是D输出类别有K+1类,第K+1类是假样本类。鉴别器D输入有三类数据。1、有标签样本x_label。2、无标签样本x_unlabel。3、生成器生成的假样本x_fake。三种样本对应三种误差。
三种误差
整个系统涉及三种误差。
对于训练集中的有标签样本,考察估计的标签是否正确。即,计算分类为相应的概率:
Llabel=−E[lnp(y|x)]Llabel=−E[lnp(y|x)]
对于训练集中的无标签样本,考察是否估计为“真”。即,计算不估计为K+1K+1类的概率:
Lunlabel=−E[ln(1−p(K+1|x))]Lunlabel=−E[ln(1−p(K+1|x))]
对于生成器产生的伪样本,考察是否估计为“伪”。即,计算估计为K+1K+1类的概率:
Lfake=−E[lnp(K+1|x)]
训练G
最小化-E[ ln(1-p( K+1 | D(G(z)) )) ]。使得G生成的x_fake 被D认为是非第K+1类。
训练D
最小化三个误差。