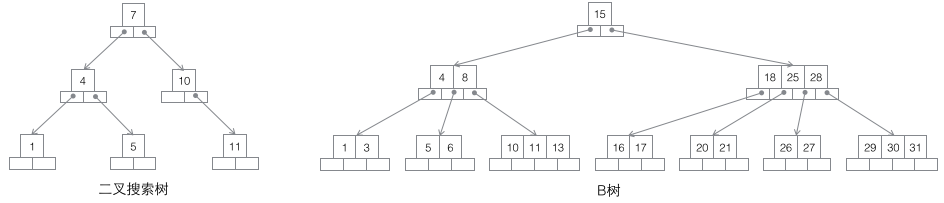
1 搜索二叉树:每个节点有两个子节点,数据量的增大必然导致高度的快速增加,显然这个不适合作为大量数据存储的基础结构。
2 B树:一棵m阶B树是一棵平衡的m路搜索树。最重要的性质是每个非根节点所包含的关键字个数 j 满足:┌m/2┐ - 1 <= j <= m - 1;一个节点的子节点数量会比关键字个数多1,这样关键字就变成了子节点的分割标志。一般会在图示中把关键字画到子节点中间,非常形象,也容易和后面的B+树区分。由于数据同时存在于叶子节点和非叶子结点中,无法简单完成按顺序遍历B树中的关键字,必须用中序遍历的方法。
3 B+树:一棵m阶B树是一棵平衡的m路搜索树。最重要的性质是每个非根节点所包含的关键字个数 j 满足:┌m/2┐ - 1 <= j <= m;子树的个数最多可以与关键字一样多。非叶节点存储的是子树里最小的关键字。同时数据节点只存在于叶子节点中,且叶子节点间增加了横向的指针,这样顺序遍历所有数据将变得非常容易。
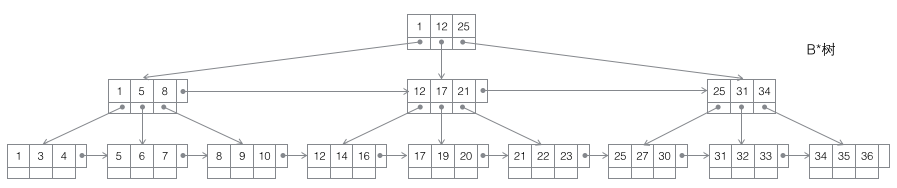
4 B*树:一棵m阶B树是一棵平衡的m路搜索树。最重要的两个性质是1每个非根节点所包含的关键字个数 j 满足:┌m2/3┐ - 1 <= j <= m;2非叶节点间添加了横向指针。

B/B+/B*三种树有相似的操作,比如检索/插入/删除节点。这里只重点关注插入节点的情况,且只分析他们在当前节点已满情况下的插入操作,因为这个动作稍微复杂且能充分体现几种树的差异。与之对比的是检索节点比较容易实现,而删除节点只要完成与插入相反的过程即可(在实际应用中删除并不是插入的完全逆操作,往往只删除数据而保留下空间为后续使用)。
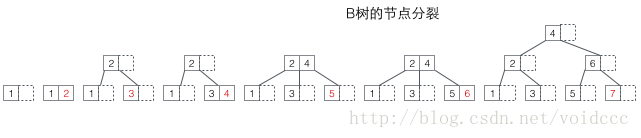
先看B树的分裂,下图的红色值即为每次新插入的节点。每当一个节点满后,就需要发生分裂(分裂是一个递归过程,参考下面7的插入导致了两层分裂),由于B树的非叶子节点同样保存了键值,所以已满节点分裂后的值将分布在三个地方:1原节点,2原节点的父节点,3原节点的新建兄弟节点(参考5,7的插入过程)。分裂有可能导致树的高度增加(参考3,7的插入过程),也可能不影响树的高度(参考5,6的插入过程)。
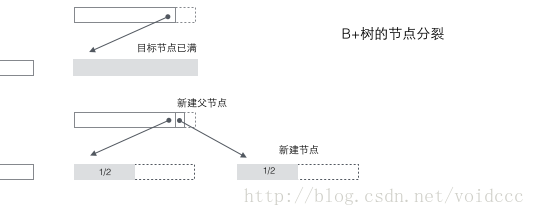
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟节点的指针。
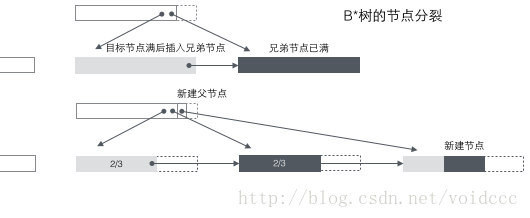
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了)。如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。可以看到B*树的分裂非常巧妙,因为B*树要保证分裂后的节点还要2/3满,如果采用B+树的方法,只是简单的将已满的节点一分为二,会导致每个节点只有1/2满,这不满足B*树的要求了。所以B*树采取的策略是在本节点满后,继续插入兄弟节点(这也是为什么B*树需要在非叶子节点加一个兄弟间的链表),直到把兄弟节点也塞满,然后拉上兄弟节点一起凑份子,自己和兄弟节点各出资1/3成立新节点,这样的结果是3个节点刚好是2/3满,达到B*树的要求,皆大欢喜。
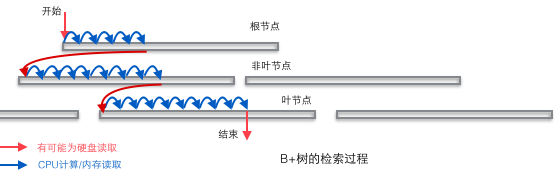
B+树适合作为数据库的基础结构,完全是因为计算机的内存-机械硬盘两层存储结构。内存可以完成快速的随机访问(随机访问即给出任意一个地址,要求返回这个地址存储的数据)但是容量较小。而硬盘的随机访问要经过机械动作(1磁头移动 2盘片转动),访问效率比内存低几个数量级,但是硬盘容量较大。典型的数据库容量大大超过可用内存大小,这就决定了在B+树中检索一条数据很可能要借助几次磁盘IO操作来完成。如下图所示:通常向下读取一个节点的动作可能会是一次磁盘IO操作,不过非叶节点通常会在初始阶段载入内存以加快访问速度。同时为提高在节点间横向遍历速度,真实数据库中可能会将图中蓝色的CPU计算/内存读取优化成二叉搜索树(InnoDB中的page directory机制)。
真实数据库中的B+树应该是非常扁平的,可以通过向表中顺序插入足够数据的方式来验证InnoDB中的B+树到底有多扁平。我们通过如下图的CREATE语句建立一个只有简单字段的测试表,然后不断添加数据来填充这个表。通过下图的统计数据(来源见参考文献1)可以分析出几个直观的结论,这几个结论宏观的展现了数据库里B+树的尺度。
1 每个叶子节点存储了468行数据,每个非叶子节点存储了大约1200个键值,这是一棵平衡的1200路搜索树!
2 对于一个22.1G容量的表,也只需要高度为3的B+树就能存储了,这个容量大概能满足很多应用的需要了。如果把高度增大到4,则B+树的存储容量立刻增大到25.9T之巨!
3 对于一个22.1G容量的表,B+树的高度是3,如果要把非叶节点全部加载到内存也只需要少于18.8M的内存(如何得出的这个结论?因为对于高度为2的树,1203个叶子节点也只需要18.8M空间,而22.1G从良表的高度是3,非叶节点1204个。同时我们假设叶子节点的尺寸是大于非叶节点的,因为叶子节点存储了行数据而非叶节点只有键和少量数据。),只使用如此少的内存就可以保证只需要一次磁盘IO操作就检索出所需的数据,效率是非常之高的。
