GAN这一概念是由Ian Goodfellow于2014年提出,并迅速成为了非常火热的研究话题,GAN的变种更是有上千种,深度学习先驱之一的Yann LeCun就曾说,"GAN及其变种是数十年来机器学习领域最有趣的idea"。那么什么是GAN呢?GAN的应用有哪些呢?GAN的原理是什么呢?怎样去实现一个GAN呢?本文将一一阐述。具体大纲如下:
- 1.什么是GAN?
- 2.GAN的应用
- 3.GAN的原理
- 4.实现DCGAN[Github链接]
- 5.GAN小技巧
- 6.参考
- 7.未完待续(后期还会加一些其他的GAN)
1. 什么是GAN?
GAN的英文全称是Generative Adversarial Network,中文名是生成对抗网络,它由两个部分组成,一个是生成器(generative),还有一个是鉴别器,与生成器是敌对(Adversarial)关系。对GAN有了初步了解,知道它有两个模块组成,下面通过事例来理解这两个模块的产生思想?
1.1 对抗思想——啵啵鸟与枯叶蝶
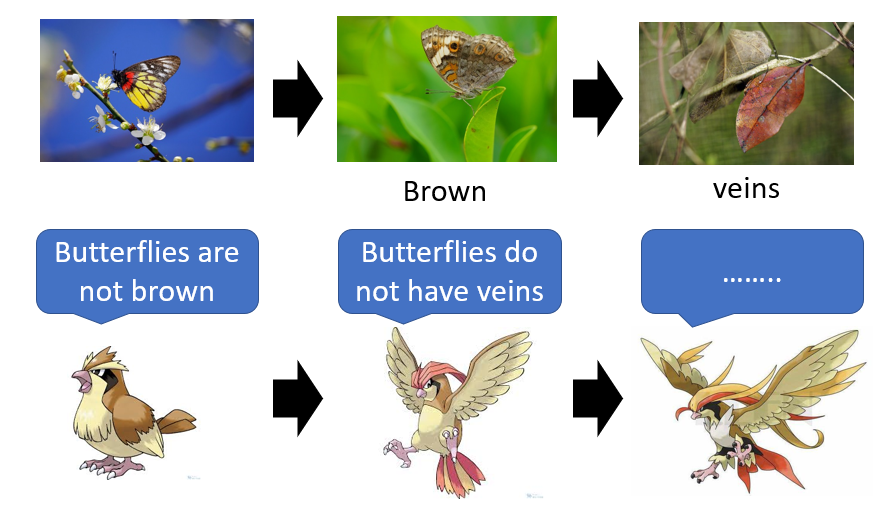
在生物进化的过程中,被捕食者会慢慢演化自己的特征,从而达到欺骗捕食者的目的,而捕食者也会根据情况调整自己对被捕食者的识别,共同进化,上图中的啵啵鸟和枯叶蝶就是这样的一种关系。生成器代表的是枯叶蝶,鉴别器代表的是啵啵鸟。它们的对抗思想与GAN类似,但GAN却有所不同。
1.2 GAN思想——画画的演变
GAN之所以有所不同,这里的原因是GAN所作的工作与自然界的生物进化不同,它是已经知道最终鉴别的目标是什么样子,不知道假目标是什么样子,它会对生成器所产生的假目标做惩罚和对真目标进行奖励,这样鉴别器就知道什么目标是不好的假目标,什么目标是好的真目标,而生成器则是希望通过进化,产生比上一次更好的假目标,使鉴别器对自己的惩罚更小。以上是一个轮回,下一个轮回,鉴别器通过学习上一个轮回进化的假目标和真目标,再次进化对假目标的惩罚,而生成器不屈不挠,再次进化,直到以假乱真,与真目标一致,至此进化结束。
以上图为例,我们最开始画人物头像只知道有一个头的大致形状,有眼睛有鼻子等等,但画得不精致,后来通过找老师学习,画得更好了,有模有样,直到,我们画得与专门画头像的老师一样好。这里的我们就像是生成器,一步步进化(对应生成器不同的等级),这里的老师就像是鉴别器(这里只是比喻说明,现实世界的老师已经是一个成熟的鉴别器,不需要通过假样本进行学习,这里有那个意思就行)
1.3 零和博弈(zero-sum game)
玩过纸牌的人知道,赢家的快乐是建立在输家的痛苦之上,收益和损失的总和始终为0。生成器和鉴别器也是这样一对博弈关系:鉴别器惩罚生成器,鉴别器收益,生成器损失;生成器进化,使鉴别器对自己惩罚小,生成器收益,鉴别器损失。
1.4 小结
什么是GAN?GAN是由生成器和鉴别器两个部分组成,生成器的目的是生成假的目标,企图彻底骗过鉴别器的识别。而鉴别器通过学习真目标和假目标,提高自己的鉴别能力,不让假目标骗过自己。两者相互进化,相互博弈,一方进化,另一方损失,最后直到假目标与真目标很相似则停止进化。
2. GAN的应用
首先,我们要知道结构化学习(Structured Learning),GAN也是结构化学习的一种。与分类和回归类似,结构化学习也是需要找到一个X→→Y的映射,但结构化学习的输入和输出多种多样,可以是序列(sequence)到序列,序列到矩阵(matrix),矩阵到图(graph),图到树(tree)等等。这样,GAN的应用就十分广泛了。例如,机器翻译(machine translation)可以用GAN去做,如下图所示
还有语音识别(speech recognition)以及聊天机器人(chat-bot)
在图像方面,我们可以做图像转图像(image-to-image),彩色化(colorization),还有文本转图像(text-to-image)
当然,GAN的应用远不止这么些,有非常有趣的变脸,图像自动打马赛克,自动生成多表情图像,年轻转年老等等,更多cool又skr的应用静待各位挖掘!
3 GAN原理
GAN的最终目的是为了生成能够产生以假乱真的目标的生成器。那么,是不是一定要用GAN呢?生成器可不可以自己训练得到目标?鉴别器可不可以自己训练得到目标?我们先来看这两个问题,然后再深入讨论GAN。
3.1 生成器是否可以自我训练?
答案是肯定的,我们所熟知的自编码器(Auto-Encoder)以及变分自编码器(Variational Auto-Encoder)都是典型的生成器。输入通过Encoder编码成code,然后code通过Decoder重建原图,其中自编码器中的Decoder就是生成器,code可随机取值,产生不同的输出。
自编码器的结构如下:
变分自编码器的结构如下
然后自编码器存在着问题,我们来看看下面这张图
生成器的问题:由于自编码器的目标是让重建误差越来越小,但从上图中,我们可以看出,其中1个pixel的error,自编码器是觉得ok的,我们是觉得不行,另外6个pixel的误差我们觉得能接受的,自编码器不能接受,误差所在的位置很重要,而生成器并不知道这一点,自编码器缺少理解像素点之间的空间相关性的能力。还有一点,就是自编码器所产生的图像是模糊的,不能够产生十分清晰的图像,如下图所示
所以说目前单凭生成器是很难生成非常高质量的图像的。
3.2 鉴别器是否可以自我训练?
答案也是肯定的。鉴别器是给定一个输入,输出一个[0,1]的置信度,越接近1则置信越高,越接近0则置信度越低,如图所示:
鉴别器的优势在于它可以很轻易地捕捉到元素之间的相关性,例如自编码器中出现的像素问题就不会在鉴别器中出现,如图所示,用一个滤波器就解决了。
现在来说说鉴别器要怎么样产生样本,参考下图:
首先也需要随机生成负样本,然后与真实样本一起送入鉴别器进行训练,在循环迭代中,通过最大概率选出最好的负样本,再与真样本一起送入鉴别器进行训练,然而,看起来和GAN训练差不多一致,没啥问题,其实这里面还有存在着问题的。我们来看下面这张图: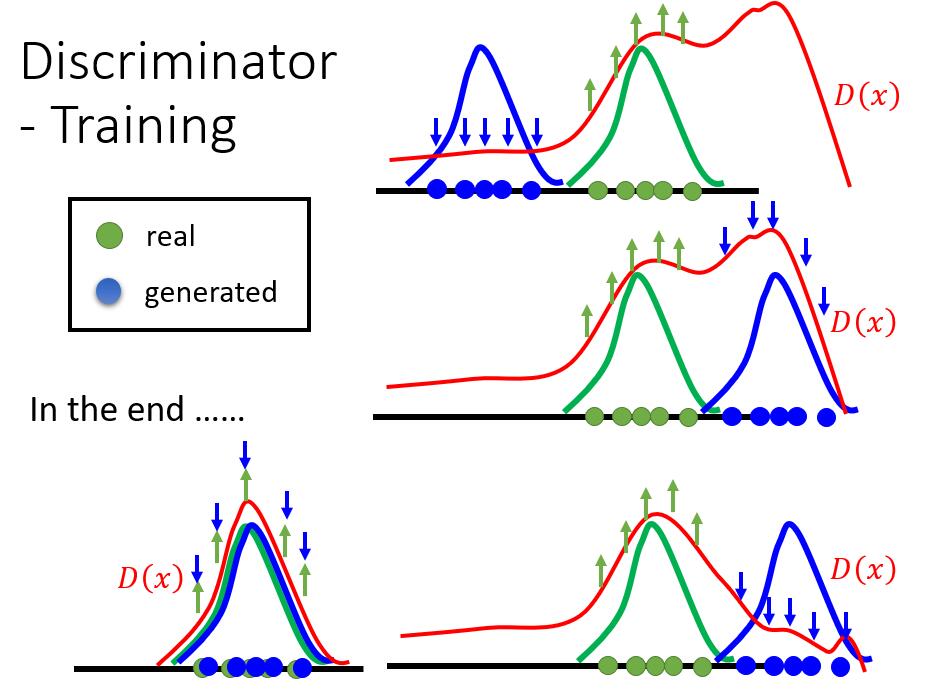
鉴别器的问题:鉴别器的训练是对真样本进行奖励,对负样本进行压低,也就是图中的绿色抬高,蓝色压低,这就造成了问题,我们要训练出好的鉴别器,训练过程需要随机采样出除绿色图像外所有的假样本,这样鉴别器就只会对真实样本的分布取高分,对其他分布取低分,这样才能训练的好,然后再高维空间中,这样的负样本采样过程其实是很难进行的,而且还有一个问题,生成样本的过程要枚举大量样本,才有可能出现一个与真样本分布相符的样本,通过求那个最大化概率问题求出最好的样本,这实在是过于繁琐。
3.3 生成器、鉴别器和GAN的优缺点
通过上面的阐述,我们初步知道了它们的优缺点,下面这张ppt直观地给出了每个的优缺点,如图所示:
可以看出生成器和鉴别器的优缺点是可以互补的,这也就是GAN的优势。(生成器+鉴别器),下图介绍了GAN的优点,从两个角度出发。
- 从鉴别器的角度出发,利用生成器去生成样本,去求解最大化问题
- 从生成器角度出发,生成的样本依旧是逐个元素,但通过鉴别器可以得到全局性。

当然,GAN也是又缺点的,它是一种隐变量模型,可解释没有生成器和鉴别器强,另外GAN是不好进行训练。我在训练DAGAN的时候就成功造成了鉴别器的误差为0,无法进行反向传播更新梯度。
3.4 GAN背后的理论
对于生成器而言,它的目标是希望能够学习到真实样本的分布,这样就可以随机生成以假乱真的样本。如下图所示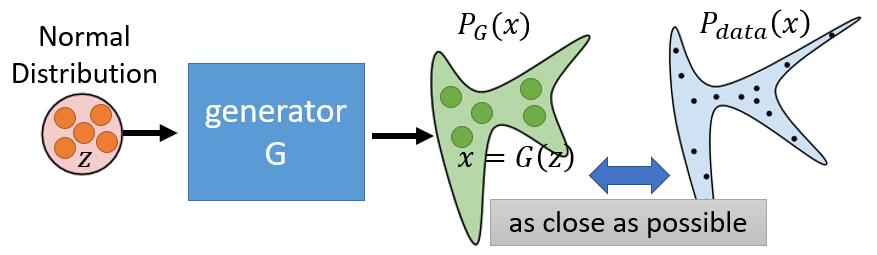
如何去学习真实样本分布呢,这就需要用到极大似然估计(Maximum Likelihood Estimation),先来看看下面这张图
我们需要随机采样真实分布中的数据,通过学习P(x;θ)P(x;θ)中的θθ,希望P(x;θ)P(x;θ)越接近Pdata(x)Pdata(x),其中每一个xx对应的Pdata(x)Pdata(x)的概率是很大的,为了使P(x;θ)P(x;θ)越接近Pdata(x)Pdata(x),原问题等价于最大化每一个P(xi;θ)P(xi;θ),合起来就是最大化∏mi=1PG(xi;θ)∏i=1mPG(xi;θ)。而实际上极大似然估计是等价于最小化KL−divergenceKL−divergence,具体推导看下图,先取loglog(loglog是单调递增,不会改变原问题)将相乘化为相加,最后变成了PdataPdata下logPG(x;θ)logPG(x;θ)的期望,然后转化成积分的形式,后面加了一项∫xPdata(x)logPdata(x)dx∫xPdata(x)logPdata(x)dx,这一项是一个常数,没有变量θθ,加了也不会影响原问题的解,加了这一项之后原问题就等于最小化Pdata和PGPdata和PG的KL−divergenceKL−divergence。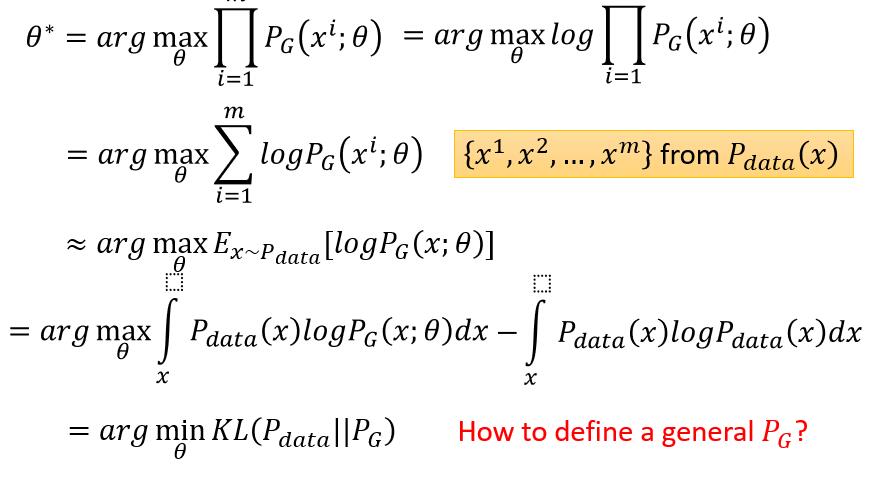
我们已经知道生成器要做的是arg minG Div(Pdata,PG)arg minG Div(Pdata,PG),这里PGPG是我们要去最优化的,虽然我们有真实样本,但PGPG的分布我们还是不知道,而且如何去定量计算PdataPdata和PGPG的divergencedivergence,也就是Div(Pdata,PG)Div(Pdata,PG),我们也是不知道的。所以接下来就需要引入鉴别器了。
虽然我们不知道PGPG和PdataPdata的分布,但我们可以随机采样它们分布的样本,如下图所示:
而我们知道鉴别器的目标是给真样本奖励,假样本惩罚,如下图所示,最后得到要鉴别器要优化的目标函数,鉴别器希望能够最大化这个目标函数,也就是arg maxD V(D,G)arg maxD V(D,G).注意,这里是是将GG是fixedfixed,是不变的。
我们再来解这个问题,解出最优D∗D∗,接下来的步骤就比较数学了,给一个目标函数,求出极大值解。具体如图下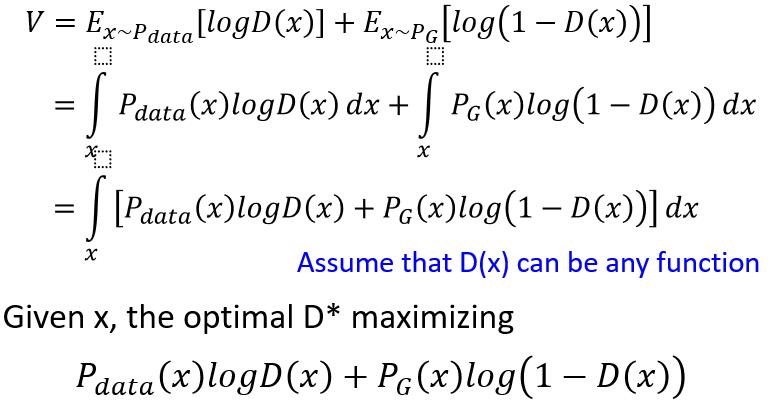


这个求解过程还是蛮详细的,最后我们竟然得到最大化V(D,G)V(D,G)竟然等于一个常数加上PGPG和PdataPdata的JS−divergenceJS−divergence(JS−divergenceJS−divergence与KL−divergenceKL−divergence类似,不会改变解),这正是我们在生成器一直想求,可不会求得东西,鉴别器帮我们做到了。
于是,原始生成器的最优化问题arg minGDiv(PG,Pdata)arg minGDiv(PG,Pdata)就可以转化成arg minG maxDV(G,D)arg minG maxDV(G,D)。那如何来求解arg minG maxDV(G,D)arg minG maxDV(G,D)这个最小最大问题呢?其实上面图上已经给出答案了,通过固定其中一个,求另一个,然后固定另一个,求之前固定住的这个。具体做法如图下:
更加详细的实践过程(也就是GAN的训练过程)如下所示,相信看了上面的一系列解释,会对GAN如此训练有了比较深的理解了吧。
GAN的理论就到此结束。
4. 实现DCGAN
这里使用数据集是Anime——台大李宏毅老师的GAN课程的数据集,点击链接下载,首先我们来看一下DCGAN的框架,如图所示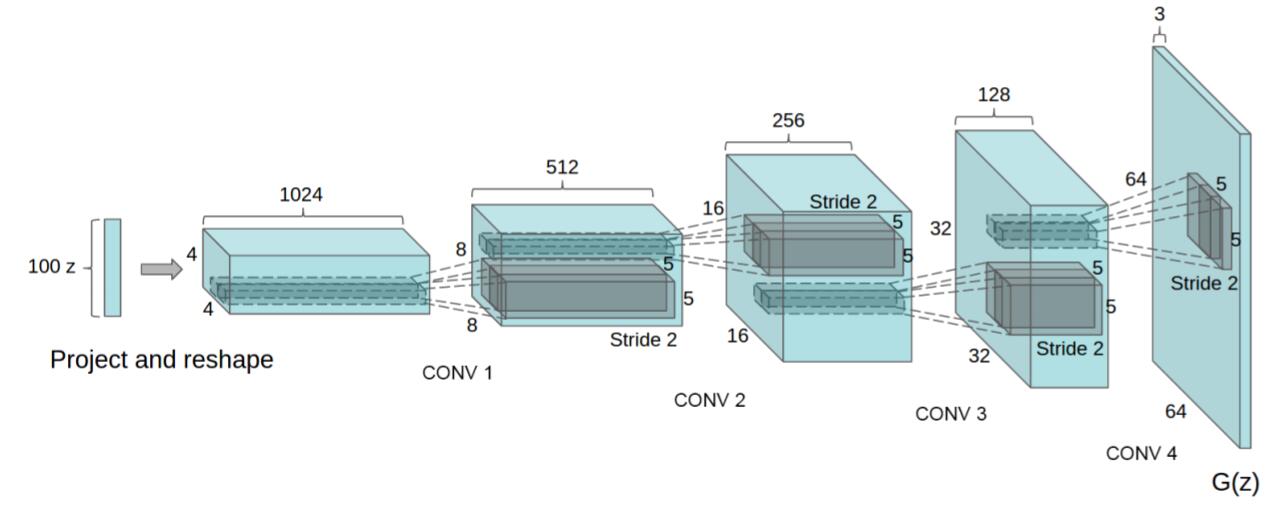
这个是生成器的结构图,鉴别器的结构与生成器大致相反,DCGAN与普通的GAN有一些区别,具体分为下面几点
- DCGAN的网络都是全卷积的
- 生成器除最后一层外都加batchnorm,鉴别器则是第一层没加bacthnorm
- 鉴别器中的激活函数使用的是leaky_relu,负斜率是0.2
- 生成器中的激活函数使用relu,输出层采用tanh
- 采用Adam优化算法,学习率是0.0002,beta1=0.5
代码使用请参考Github链接
下面进入代码实现,首先是model.py文件,实现了DCGAN中的Generate和Discriminator,代码如下:
import torch
import torch.nn as nn
import torch.functional as F
class Generate(nn.Module):
def __init__(self, input_dim=100):
super(Generate, self).__init__()
channel = [512, 256, 128, 64, 3]
kernel_size = 4
stride = 2
padding = 1
self.convtrans1_block = self.__convtrans_bolck(input_dim, channel[0], 6, padding=0, stride=stride)
self.convtrans2_block = self.__convtrans_bolck(channel[0], channel[1], kernel_size, padding, stride)
self.convtrans3_block = self.__convtrans_bolck(channel[1], channel[2], kernel_size, padding, stride)
self.convtrans4_block = self.__convtrans_bolck(channel[2], channel[3], kernel_size, padding, stride)
self.convtrans5_block = self.__convtrans_bolck(channel[3], channel[4], kernel_size, padding, stride, layer="last_layer")
def __convtrans_bolck(self, in_channel, out_channel, kernel_size, padding, stride, layer=None):
if layer == "last_layer":
convtrans = nn.ConvTranspose2d(in_channel, out_channel, kernel_size, stride, padding, bias=False)
tanh = nn.Tanh()
return nn.Sequential(convtrans, tanh)
else:
convtrans = nn.ConvTranspose2d(in_channel, out_channel, kernel_size, stride, padding, bias=False)
batch_norm = nn.BatchNorm2d(out_channel)
relu = nn.ReLU(True)
return nn.Sequential(convtrans, batch_norm, relu)
def forward(self, inp):
x = self.convtrans1_block(inp)
x = self.convtrans2_block(x)
x = self.convtrans3_block(x)
x = self.convtrans4_block(x)
x = self.convtrans5_block(x)
return x
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator,self).__init__()
channels = [3, 64, 128, 256, 512]
kernel_size = 4
stride = 2
padding = 1
self.conv_bolck1 = self.__conv_block(channels[0], channels[1], kernel_size, stride, padding, "first_layer")
self.conv_bolok2 = self.__conv_block(channels[1], channels[2], kernel_size, stride, padding)
self.conv_bolok3 = self.__conv_block(channels[2], channels[3], kernel_size, stride, padding)
self.conv_bolok4 = self.__conv_block(channels[3], channels[4], kernel_size, stride, padding)
self.conv_bolok5 = self.__conv_block(channels[4], 1, kernel_size+1, stride, 0, "last_layer")
def __conv_block(self, inchannel, outchannel, kernel_size, stride, padding, layer=None):
if layer == "first_layer":
conv = nn.Conv2d(inchannel, outchannel, kernel_size, stride, padding, bias=False)
leakrelu = nn.LeakyReLU(0.2, inplace=True)
return nn.Sequential(conv, leakrelu)
elif layer == "last_layer":
conv = nn.Conv2d(inchannel, outchannel, kernel_size, stride, padding, bias=False)
sigmoid = nn.Sigmoid()
return nn.Sequential(conv, sigmoid)
else:
conv = nn.Conv2d(inchannel, outchannel, kernel_size, stride, padding, bias=False)
batchnorm = nn.BatchNorm2d(outchannel)
leakrelu = nn.LeakyReLU(0.2, inplace=True)
return nn.Sequential(conv, batchnorm, leakrelu)
def forward(self,inp):
x = self.conv_bolck1(inp)
x = self.conv_bolok2(x)
x = self.conv_bolok3(x)
x = self.conv_bolok4(x)
x = self.conv_bolok5(x)
return x
def weight_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0,0.01)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0,0.01)
m.bias.data.fill_(0)
if __name__ == "__main__":
model1 = Generate()
x = torch.randn(10,100,1,1)
y = model1.forward(x)
print(y.size())
model2 = Discriminator()
a = torch.randn(10,3,96,96)
b = model2.forward(a)
print(b.size())
然后是AnimeDataset.py,代码如下:
import torch,torch.utils.data
import numpy as np
import scipy.misc, os
class AnimeDataset(torch.utils.data.Dataset):
def __init__(self, directory, dataset, size_per_dataset):
self.directory = directory
self.dataset = dataset
self.size_per_dataset = size_per_dataset
self.data_files = []
data_path = os.path.join(directory, dataset)
for i in range(size_per_dataset):
self.data_files.append(os.path.join(data_path,"{}.jpg".format(i)))
def __getitem__(self, ind):
path = self.data_files[ind]
img = scipy.misc.imread(path)
img = img.transpose(2,0,1)-127.5/127.5
return img
def __len__(self):
return len(self.data_files)
if __name__ == "__main__":
dataset = AnimeDataset(os.getcwd(),"anime",100)
loader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True,num_workers=4)
for i, inp in enumerate(loader):
print(i,inp.size())然后是utils.py,代码如下
import os, imageio,scipy.misc
import matplotlib.pyplot as plt
def creat_gif(gif_name, img_path, duration=0.3):
frames = []
img_names = os.listdir(img_path)
img_list = [os.path.join(img_path, img_name) for img_name in img_names]
for img_name in img_list:
frames.append(imageio.imread(img_name))
imageio.mimsave(gif_name, frames, 'GIF', duration=duration)
def visualize_loss(generate_txt_path, discriminator_txt_path):
with open(generate_txt_path, 'r') as f:
G_list_str = f.readlines()
with open(discriminator_txt_path, 'r') as f:
D_list_str = f.readlines()
D_list_float, G_list_float = [], []
for D_item, G_item in zip(D_list_str, G_list_str):
D_list_float.append(float(D_item.strip().split(':')[-1]))
G_list_float.append(float(G_item.strip().split(':')[-1]))
list_epoch = list(range(len(D_list_float)))
full_path = os.path.join(os.getcwd(), "saved/logging.png")
plt.figure()
plt.plot(list_epoch, G_list_float, label="generate", color='g')
plt.plot(list_epoch, D_list_float, label="discriminator", color='b')
plt.legend()
plt.title("DCGAN_Anime")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.savefig(full_path)
最后是main.py,代码如下:
import torch
import torch.nn as nn
from torch.optim import Adam
from torchvision.utils import make_grid
from model import Generate,Discriminator,weight_init
from AnimeDataset import AnimeDataset
import matplotlib.pyplot as plt
import numpy as np
import scipy.misc
import os, argparse
from tqdm import tqdm
from utils import creat_gif, visualize_loss
def main():
parse = argparse.ArgumentParser()
parse.add_argument("--lr", type=float, default=0.0001,
help="learning rate of generate and discriminator")
parse.add_argument("--beta1", type=float, default=0.5,
help="adam optimizer parameter")
parse.add_argument("--batch_size", type=int, default=64,
help="number of dataset in every train or test iteration")
parse.add_argument("--dataset", type=str, default="anime",
help="base path for dataset")
parse.add_argument("--epochs", type=int, default=500,
help="number of training epochs")
parse.add_argument("--loaders", type=int, default=4,
help="number of parallel data loading processing")
parse.add_argument("--size_per_dataset", type=int, default=30000,
help="number of training data")
parse.add_argument("--pre_train", type=bool, default=False,
help="whether load pre_train model")
args = parse.parse_args()
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
if not os.path.exists("saved"):
os.mkdir("saved")
if not os.path.exists("saved/img"):
os.mkdir("saved/img")
if os.path.exists("faces"):
pass
else:
print("Don't find the dataset directory, please copy the link in website ,download and extract faces.tar.gz .\n \
https://drive.google.com/drive/folders/1mCsY5LEsgCnc0Txv0rpAUhKVPWVkbw5I \n ")
exit()
if args.pre_train:
generate = torch.load("saved/generate.t7").to(device)
discriminator = torch.load("saved/discriminator.t7").to(device)
else:
generate = Generate().to(device)
discriminator = Discriminator().to(device)
generate.apply(weight_init)
discriminator.apply(weight_init)
dataset = AnimeDataset(os.getcwd(), args.dataset, args.size_per_dataset)
dataload = torch.utils.data.DataLoader(dataset, batch_size=args.batch_size, shuffle=True, num_workers=4)
criterion = nn.BCELoss().to(device)
optimizer_G = Adam(generate.parameters(), lr=args.lr, betas=(args.beta1, 0.999))
optimizer_D = Adam(discriminator.parameters(), lr=args.lr, betas=(args.beta1, 0.999))
fixed_noise = torch.randn(64, 100, 1, 1).to(device)
for epoch in range(args.epochs):
print("Main epoch{}:".format(epoch))
progress = tqdm(total=len(dataload.dataset))
loss_d, loss_g = 0, 0
for i, inp in enumerate(dataload):
# train discriminator
real_data = inp.float().to(device)
real_label = torch.ones(inp.size()[0]).to(device)
noise = torch.randn(inp.size()[0], 100, 1, 1).to(device)
fake_data = generate(noise)
fake_label = torch.zeros(fake_data.size()[0]).to(device)
optimizer_D.zero_grad()
real_output = discriminator(real_data)
real_loss = criterion(real_output.squeeze(), real_label)
real_loss.backward()
fake_output = discriminator(fake_data)
fake_loss = criterion(fake_output.squeeze(), fake_label)
fake_loss.backward()
loss_D = real_loss + fake_loss
optimizer_D.step()
#train generate
optimizer_G.zero_grad()
fake_data = generate(noise)
fake_label = torch.ones(fake_data.size()[0]).to(device)
fake_output = discriminator(fake_data)
loss_G = criterion(fake_output.squeeze(), fake_label)
loss_G.backward()
optimizer_G.step()
progress.update(dataload.batch_size)
progress.set_description("D:{}, G:{}".format(loss_D.item(), loss_G.item()))
loss_g += loss_G.item()
loss_d += loss_D.item()
loss_g /= (i+1)
loss_d /= (i+1)
with open("generate_loss.txt", 'a+') as f:
f.write("loss_G:{} \n".format(loss_G.item()))
with open("discriminator_loss.txt", 'a+') as f:
f.write("loss_D:{} \n".format(loss_D.item()))
if epoch % 20 == 0:
torch.save(generate, os.path.join(os.getcwd(), "saved/generate.t7"))
torch.save(discriminator, os.path.join(os.getcwd(), "saved/discriminator.t7"))
img = generate(fixed_noise).to("cpu").detach().numpy()
display_grid = np.zeros((8*96,8*96,3))
for j in range(int(64/8)):
for k in range(int(64/8)):
display_grid[j*96:(j+1)*96,k*96:(k+1)*96,:] = (img[k+8*j].transpose(1, 2, 0)+1)/2
img_save_path = os.path.join(os.getcwd(),"saved/img/{}.png".format(epoch))
scipy.misc.imsave(img_save_path, display_grid)
creat_gif("evolution.gif", os.path.join(os.getcwd(),"saved/img"))
visualize_loss("generate_loss.txt", "discriminator_loss.txt")
if __name__ == "__main__":
main()
最后500个epoch的结果图如下
5.GAN小技巧
1.对真实图片进行归一化,与生成图片分布一样,也就是[-1,1].
2.随机噪声使用高斯分布,不要使用均匀分布,也就是在代码中使用torch.randn,而不是torch.rand
3.初始化权重很有必要,详细见model.py中的weight_init函数
4.在训练时,在鉴别器中产生的noise,生成器也要用这个noise进行参数,这点很重要。我最开始的时候就是鉴别器随机产生noise,生成器也随机产生noise,训练得很不好。
5.在训练过程中,很有可能鉴别器的loss等于0(鉴别器太强了,起初我试过减小鉴别器的学习率,但还是会有这个情况,我猜想原因是在某一个batch中,鉴别器恰好将随机噪声产生的图片和真实图片完全区分开,loss为0),导致生成器崩溃(梯度弥散),所以最好按多少个epoch保存模型,然后在导入模型再训练。个人觉得数据增强和增大batchsize会减弱这种情况的可能性,这个还未实践。
6.参考
1 李宏毅GAN课程及PPT
2 DCGAN paper
3 chenyuntc