1、string
1.1 复制 SET key value
1.2 取值 GET key
1.3 取值时同时对key进行赋值操作。GETSET key value
1.4 删除 del key
1.5 数值增减
(1)递增
127.0.0.1:6379> incr num
(integer) 1
127.0.0.1:6379> incr num
(integer) 2
127.0.0.1:6379> incr num
(integer) 3
(2)增加指定的整数
127.0.0.1:6379> incrby num 2
(integer) 5
127.0.0.1:6379> incrby num 2
(integer) 7
127.0.0.1:6379> incrby num 2
(integer) 9
(3) 递减数值
decr key
2、数据类型 hash
2.1使用String的问题
假设有User对象以JSON序列化的形式存储到Redis中,User对象有id,username、password、age、name等属性,存储的过程如下:
保存、更新:
User对象 --→ json(string) --→ redis
如果在业务上只是更新age属性,其他的属性并不做更新我应该怎么做呢? 如果仍然采用上边的方法在传输、处理时会造成资源浪费,下边讲的hash可以很好的解决这个问题。
2.2 redis hash 介绍
hash叫散列类型,它提供了字段和字段值的映射。字段值只能是字符串类型,不支持散列类型、集合类型等其它类型。如下:
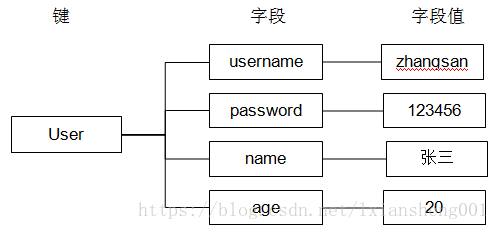
redis hash存储比关系数据库的好处?
2.3 命令
2.3.1 赋值 (HSET命令不区分插入和更新操作,当执行插入操作时HSET命令返回1,当执行更新操作时返回0)
HSET key field value 一次只能设置一个字段值
127.0.0.1:6379> hset user username zhangsan
(integer) 1
-----------------------------
HMSET key field value [field value ...] 一次可以设置多个字段值
127.0.0.1:6379> hmset user age 20 username lisi
OK
HSET命令不区分插入和更新操作,当执行插入操作时HSET命令返回1,当执行更新操作时返回0.2.3.2 取值
HGET key field 一次只能获取一个字段值
127.0.0.1:6379> hget user username
"zhangsan“
----------------------------
HMGET key field [field ...] 一次可以获取多个字段值
127.0.0.1:6379> hmget user age username
1) "20"
2) "lisi"
----------------------------
HGETALL key
127.0.0.1:6379> hgetall user
1) "age"
2) "20"
3) "username"
4) "lisi"
2.3.3 删除字段
可以删除一个或多个字段,返回值是被删除的字段个数
HDEL key field [field ...]
127.0.0.1:6379> hdel user age
(integer) 1
127.0.0.1:6379> hdel user age name
(integer) 0
127.0.0.1:6379> hdel user age username
(integer) 1
2.3.4 增加字数
HINCRBY key field increment
127.0.0.1:6379> hincrby user age 2 将用户的年龄加2
(integer) 22
127.0.0.1:6379> hget user age 获取用户的年龄
"22“
1.4 应用
商品信息展示。
商品id、商品名称、商品描述、商品库存、商品好评
定义商品信息的key:
商品1001的信息在 redis中的key为:items:1001
存储商品信息
192.168.101.3:7003> HMSET items:1001 id 3 name apple price 999.9
OK
获取商品信息
192.168.101.3:7003> HGET items:1001 id
"3"
192.168.101.3:7003> HGETALL items:1001
1) "id"
2) "3"
3) "name"
4) "apple"
5) "price"
6) "999.9"
3、数据类型--list
3.1 ArrayList 与 LinkedList的区别和优缺点
(1)ArrayList使用数组方式存储数据,所以根据索引查询数据速度快,而新增或者删除元素时需要设计到位移操作,所以比较慢。
(2) LinkedList使用双向链接方式存储数据,每个元素都记录前后元素的指针,所以插入、删除数据时只是更改前后元素的指针指向即可,速度非常快,然后通过下标查询元素时需要从头开始索引,所以比较慢,但是如果查询前几个元素或后几个元素速度比较快。
3.2 redis list介绍
列表类型(list)可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获得列表的某一个片段。
列表类型内部是使用双向链表(double linked list)实现的,所以向列表两端添加元素的时间复杂度为0(1),获取越接近两端的元素速度就越快。这意味着即使是一个有几千万个元素的列表,获取头部或尾部的10条记录也是极快的。
顺序类似于值栈
3.3 命令
3.3.1 向列表两端增加元素
LPUSH key value [value ...]
RPUSH key value [value ...]
向列表左边增加元素
127.0.0.1:6379> lpush list 1 2 3
(integer) 3
向列表右边增加元素
127.0.0.1:6379> rpush list 4 5 6
(integer) 3
3.3.2 查看列表
LRANGE key start stop
LRANGE命令是列表类型最常用的命令之一,获取列表中的某一片段,将返回start、stop之间的所有元素(包含两端的元素),索引从0开始。索引可以是负数,如:“-1”代表最后边的一个元素。
127.0.0.1:6379> lrange list 0 -1
1) "3"
2) "2"
3) "1"3.3.3 从列表两端弹出元素
LPOP key
RPOP key
LPOP命令从列表左边弹出一个元素,会分两步完成,第一步是将列表左边的元素从列表中移除,第二步是返回被移除的元素值。
3.3.4 获取类表中元素的个数 LLen key
3.4 商品评论列表
在redis中创建商品评论列表
用户发布商品评论,将评论信息转成json存储到list中。
用户在页面查询评论列表,从redis中取出json数据展示到页面。
定义商品评论列表key:
商品编号为1001的商品评论key:items: comment:1001
192.168.93.88:6379> LPUSH items:comment:1002 '{"id":1,"name":"goo","date":1430295077289}'注意 redis不能存储zh 中文
4、数据类型--set
4.1 redis set 介绍
在集合中的每个元素都是不同的,且没有顺序。
集合类型和列表类型的对比:

集合类型的常用操作是向集合中加入或删除元素、判断某个元素是否存在等,由于集合类型的Redis内部是使用值为空的散列表实现,所有这些操作的时间复杂度都为0(1)。
Redis还提供了多个集合之间的交集、并集、差集的运算。
4.2 命令
4.2.1增加/删除元素
SADD key member [member ...]
SREM key member [member ...]
127.0.0.1:6379> sadd set a b c
(integer) 3
127.0.0.1:6379> sadd set a
(integer) 0
127.0.0.1:6379> srem set c d
(integer) 1
4.2.2 获取集合中所有的元素
SMEMBERS key
判断元素是否在集合中,无论集合中有多少元素都可以极速的返回结果。
SISMEMBER key member
4.2.3 其他命令(集合的差、并、交运算)
5、数据类型--sorted set
5.1 redis zsort介绍
在集合类型的基础上有序集合类型为集合中的每个元素都关联一个分数,这使得我们不仅可以完成插入、删除和判断元素是否存在在集合中,还能够获得分数最高或最低的前N个元素、获取指定分数范围内的元素等与分数有关的操作。
在某些方面有序集合和列表类型有些相似。
1、二者都是有序的。
2、二者都可以获得某一范围的元素。
但是,二者有着很大区别:
1、列表类型是通过链表实现的,获取靠近两端的数据速度极快,而当元素增多后,访问中间数据的速度会变慢。
2、有序集合类型使用散列表实现,所有即使读取位于中间部分的数据也很快。
3、列表中不能简单的调整某个元素的位置,但是有序集合可以(通过更改分数实现)
4、有序集合要比列表类型更耗内存。
5.2 命令
5.2.1 增加元素
向有序集合中加入一个元素和该元素的分数,如果该元素已经存在则会用新的分数替换原有的分数。返回值是新加入到集合中的元素个数,不包含之前已经存在的元素。
ZADD key score member [score member ...]
127.0.0.1:6379> zadd scoreboard 80 zhangsan 89 lisi 94 wangwu
(integer) 3
127.0.0.1:6379> zadd scoreboard 97 lisi
(integer) 0
获取元素的分数
ZSCORE key member
127.0.0.1:6379> zscore scoreboard lisi
"97"
5.2.2 删除元素
ZREM key member [member ...]
移除有序集key中的一个或多个成员,不存在的成员将被忽略。
当key存在但不是有序集类型时,返回一个错误。
127.0.0.1:6379> zrem scoreboard lisi
(integer) 1
5.2.3 获取排名在某个范围的元素列表
ZRANGE key start stop [WITHSCORES] 按照元素分数从小到大的顺序返回索引从start到stop之间的所有元素(包含两端的元素)
127.0.0.1:6379> zrange scoreboard 0 2
1) "zhangsan"
2) "wangwu"
3) "lisi“ZREVRANGE key start stop [WITHSCORES] 按照元素分数从大到小的顺序返回索引从start到stop之间的所有元素(包含两端的元素)
127.0.0.1:6379> zrevrange scoreboard 0 2
1) " lisi "
2) "wangwu"
3) " zhangsan “如果需要获得元素的分数的可以在命令尾部加上WITHSCORES参数
127.0.0.1:6379> zrange scoreboard 0 1 WITHSCORES
1) "zhangsan"
2) "80"
3) "wangwu"
4) "94"