动态时间规整算法(DTW)是最近接触的一种提取时间序列模板方法。本文主要是一些自己的学习记录,并适当地加入自己的理解。若有见解不一致之处,欢迎交流。
1 动态时间规整(DTW)基本思想
先从单词语音时间序列的规整问题引入DTW的基本思想。
假设下图两个时间序列对应的是同一个单词的发音(实则不是,只是为了便于理解)。黑色的线表示两个时间序列的相似的点(用幅度差异刻画时间序列点的相似性,幅度差异越小,相似性越高)。由于不同人语速上存在差异,某些人可能会把字母‘A’发得很长(延长发音),某些人却发得较短(短促发音),这样同一个字母展现出来的时间序列上就存在着很大的差异,如图中绿色圈出的时间波形所示。因此就需要对原始的两个时间序列进行规整,即对时间序列进行延伸和缩短,提取两个时间序列的相似性,从而对语音进行识别。
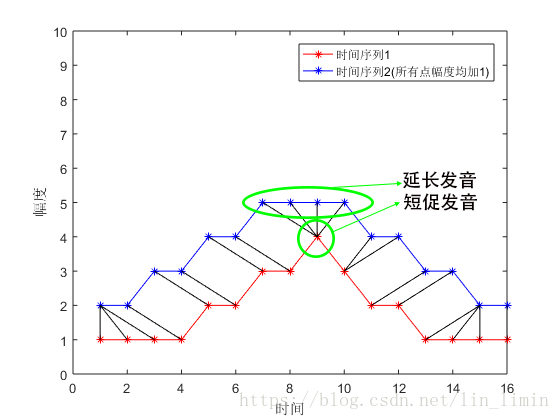
图1 动态时间规整基本思想
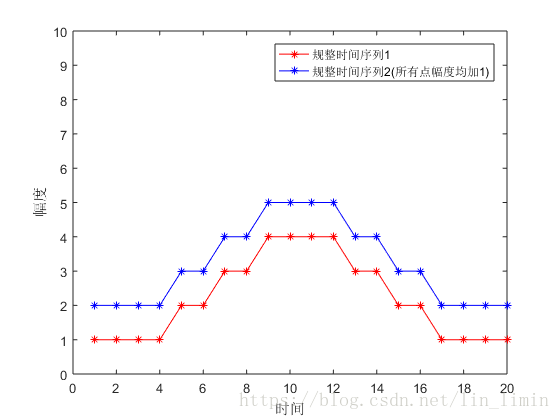
图2 时间序列规整结果
图2对应的就是原始时间序列的规整结果。
所以动态时间规整的思想就是:通过对两个时间序列点之间的相似性进行比较(图1黑线),对原始时间序列进行拉伸到相同时间长度(原始时间序列的长度很可能不一致),进而比较两个时间序列的相似性。
动态时间规整要解决的问题就是:找到一条最优的规整路径
,其中
,即认为时间序列1的第i个点和时间序列2的第j个点是相似的。所有相似点的距离之和作为规整路径距离,用规整路径距离来衡量两个时间序列的相似性。规整路径距离越小,相似度越高。
2 动态规划解DTW问题
假设原始时间序列为X,Y,它们的时间长度分别为
和
。对于规整路径
,有:
k表示两个序列最终被拉伸的长度。
规整路径必须从
开始,到
结束,以保证X和Y序列的每个坐标点都出现一次。另外,规整路径
中的i和j必须是单调递增的,所谓单调递增指的是:
所以如果路径已经通过了格点(i,j),那么路径的下一个格点只能是(i+1,j),(i,j+1),(i+1,j+1)中的一种,如图3中绿色剪头所示。
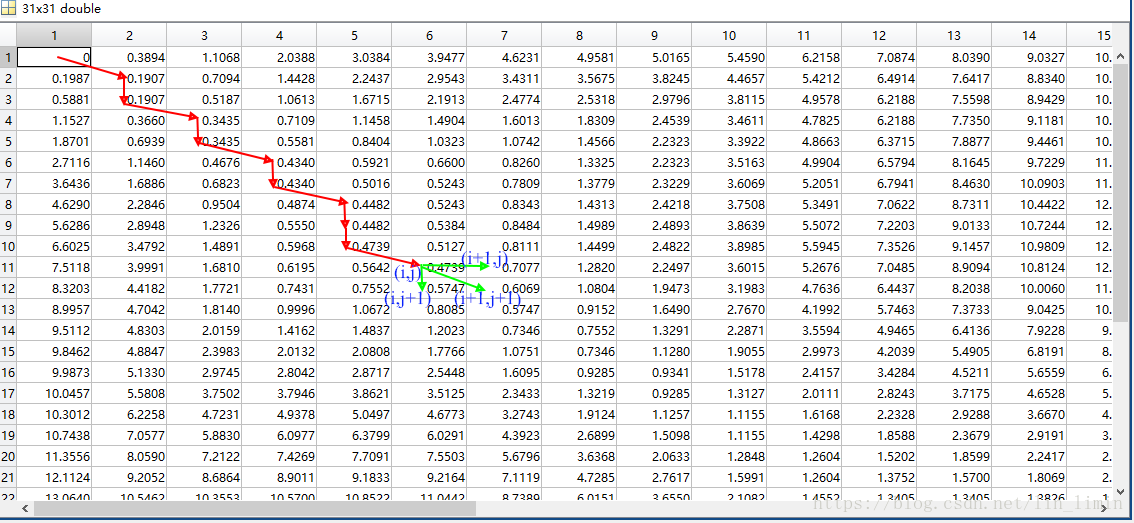
图3 规整路径示意
所以对于路径规整距离矩阵
,有:
其中,
表示X序列第i个点与Y序列第j个点之间的距离(两个点的相似性)。
衡量的是X序列前i个点与Y序列前j个点的相似性。最终的规整路径距离为
。
的值越小,两个原始时间序列的相似性越大。
有了式子(3),我们就可以用动态规划来对DTW问题进行求解。
设定不一样的采样频率对正弦函数进行采样,得到两个原始时间序列如图4所示。其中时间序列1的前半段采样频率低于时间序列2前半段的采样频率,后半段高于时间序列2的采样频率。利用动态规划的递推公式(3)可以求得路径规整矩阵
如图5所示。由
可得规整路径如图6所示。规整路径规定了时间序列X与时间序列Y的时间对齐方式。由此可以得到如图7所示的规整时间序列。可见,在DTW的作用下,完成了两个时间序列的规整目标。
这边代码借鉴于动态时间规整借鉴代码,在此多谢博主!!
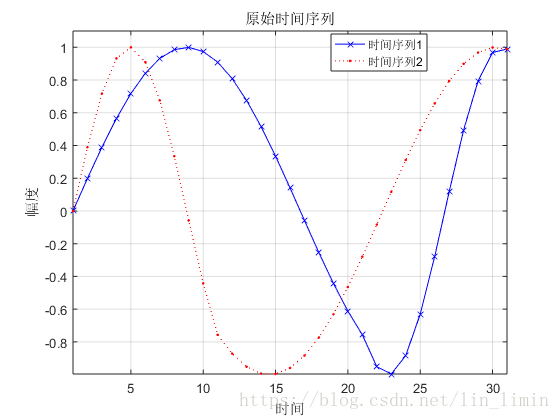
图4 采样频率不同而生成的两个原始时间序列
图5 规整距离矩阵
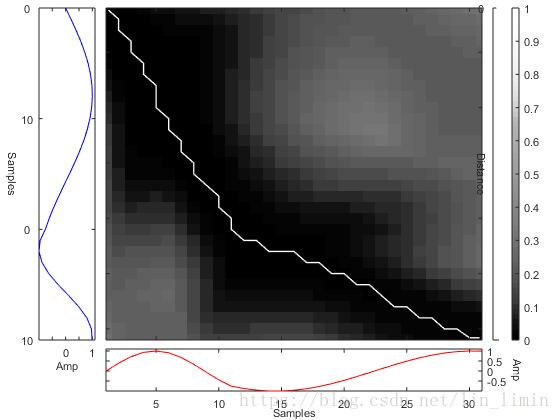
图6 规整路径
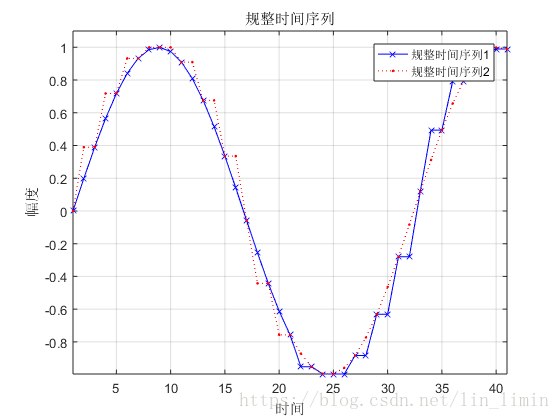
图7 DTW规整后的时间序列
图7所示的规整序列基本达到了时间序列的对齐目的。可是,如果有两个时间序列的幅值不同,将会产生什么样的规整结果?图9是对图8进行规整得到的规整时间序列。由此可知,最终的效果并不理想。为了使得DTW能够提取原始序列的时间特征而忽略幅值对序列规整的影响,我在原有代码的基础上加入了zscore对原始数据进行标准化。最终的结果如图10所示。
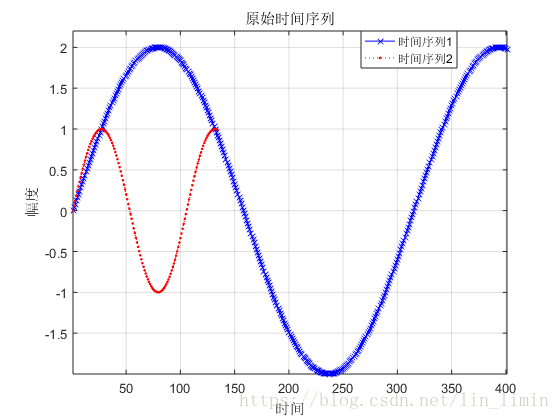
图8 具有不同幅值的两个原始时间序列
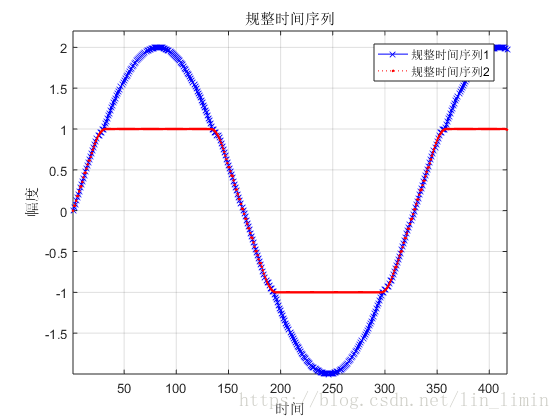
图9 不同幅值时间序列的规整结果
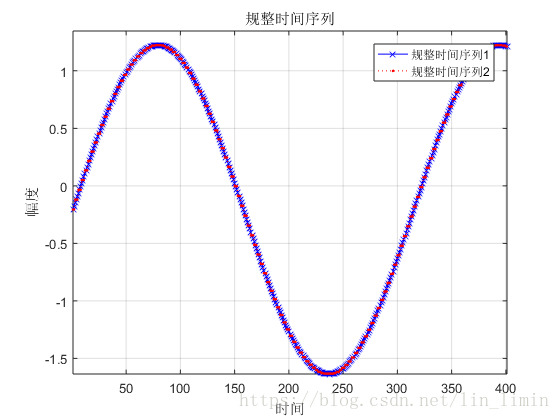
图10 加入zscore标准化处理后的规整结果
3 一个简单的单词语音音频识别实例
●语音时间序列规整
这边我利用自己录制的几段单词mp3文件来探讨动态时间规整算法对语音时间序列的对齐。图11所示为两段‘water’这个单词的语音时间序列。由于语速和发音时刻的差异,两个原始序列之间存在差异,但明显可以看出两者之间有很大的相似性。利用第2小节阐述的DTW算法,最终的语音规整结果如图12所示,基本达到了目的。当然这边做的非常粗糙,比如语音里面的很多毛刺,低频信号完全可以用滤波的方式先消掉,然后再交由DTW进行处理。
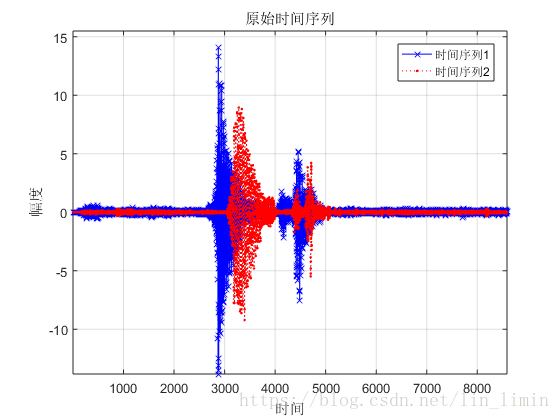
图11 两段’water’音频的原始时间序列
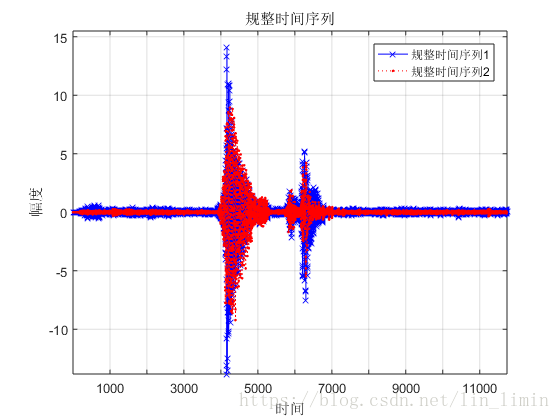
图12 语音时间序列规整
●单词语音音频识别
如何利用DTW算法来做简单的语音音频识别?第2小节已经提及,DTW做序列规整时利用规整路径距离 来衡量时间序列X和时间序列Y的相似性。所以,假设我们现有‘water’,’teacher’,’apple’的几段音频序列,要识别某一个音频的发音到底是这三个单词中的哪一个,就只需要将这个待识别音频序列分别与三个单词的音频序列做规整,得到各自的规整路径距离 (即附录代码中的变量Dist)。 越小,说明两者的相似度越高。这样可以初步完成单词语音音频识别的任务。当然,实际上进行这样操作的复杂度是很高的,实用性很差。
4 总结
① 动态时间规整算法(DTW)是一种时间序列对齐方法。它通过寻找一条规整路径来使得规整距离最小。规整路径距离
表征了两个时间序列的相似性:
越小,相似度越高。
② 可以利用DTW算法来做单词音频的识别。
5 代码附录
代码和示例音频文件可以从这里下载动态时间规整算法代码+单词音频。