什么是动态时间规整算法,他是用来干什么的
用于两个时间不同的特征序列的相似度比较。
举个例子:该算法最早的应用对象是语音识别,通过进行数据库语音特征和说话语音特征的相似度比较进行语音识别,但每个人说话的语速有所不同。具体来说,比如数据库存储的语音特征是“动态时间规整”,但有些人语速较慢“动~态~时~间~规~整”,而有些人语速有的地方快有的地方慢“动态~时间~规整”。
我们通过图像的形式表示三类人的语音特征(图像为示例,并非真实语音特征)。
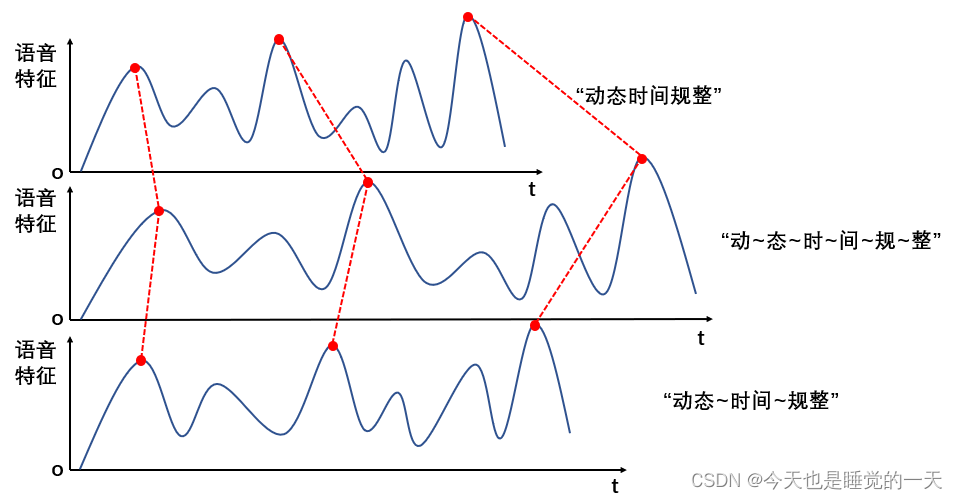
图1 不同语速语音特征匹配示意图
如图所示,蓝色曲线代表了不同语速下的语音特征,红色虚线表示部分特征对应关系,动态时间规整算法就是要找出特征对应关系,进而方便进行相似度比较。
算法实现
假设两组特征序列A,B
①定义距离公式
距离公式的定义是整个算法中唯一需要人为给定的部分,通常将相似度计算公式作为距离公式
本例定义距离公式为特征值差值的绝对值
②计算累积距离矩阵
特征序列A,B的累积距离矩阵D如下图所示(注意:需要按照图中顺序对A,B中的元素进行排列)
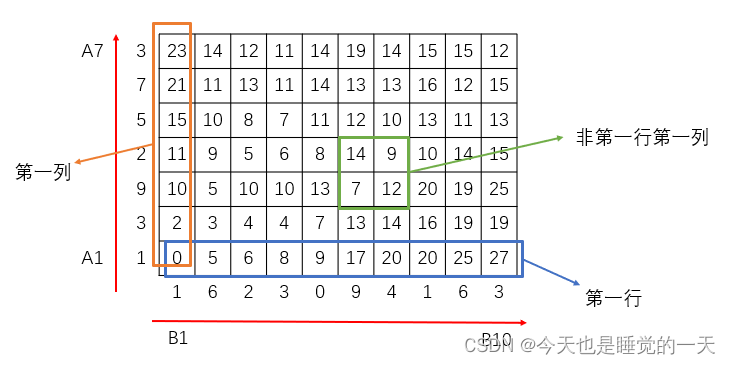
图2 累积距离矩阵示意图
累积矩阵D中的第i行第j列个元素计算公式如下
非第一行第一列:
第一行:
第一列:
第一行第一列元素:
简单来说,D[i,j]就是和
的距离+元素D[i,j]左下侧三个元素的最小值
③匹配并输出匹配结果
从矩阵右上角开始,在左下三个元素中,寻找最小元素作为下一个节点,直至到达元素D[1,1]

图3 特征匹配示意图
以矩阵块1为例,匹配从右上角元素D[7,10]=12开始,左下三元素大小分别为15、12、15,则选择元素D[6,9]=12作为下一个节点。
矩阵块2同理。
对于第一行元素或第一列元素,因为左下侧只有一个元素,则直接选择该元素作为下一个节点。
匹配结果
我们可以根据匹配结果计算特征序列A,B的相似度,相似度计算公式同距离公式
相似度计算结果
N为特征值匹配对的数量