网站
http://cc.xjtu.edu.cn/G2S/site/preview#/rich/v/124828?ref=¤toc=192
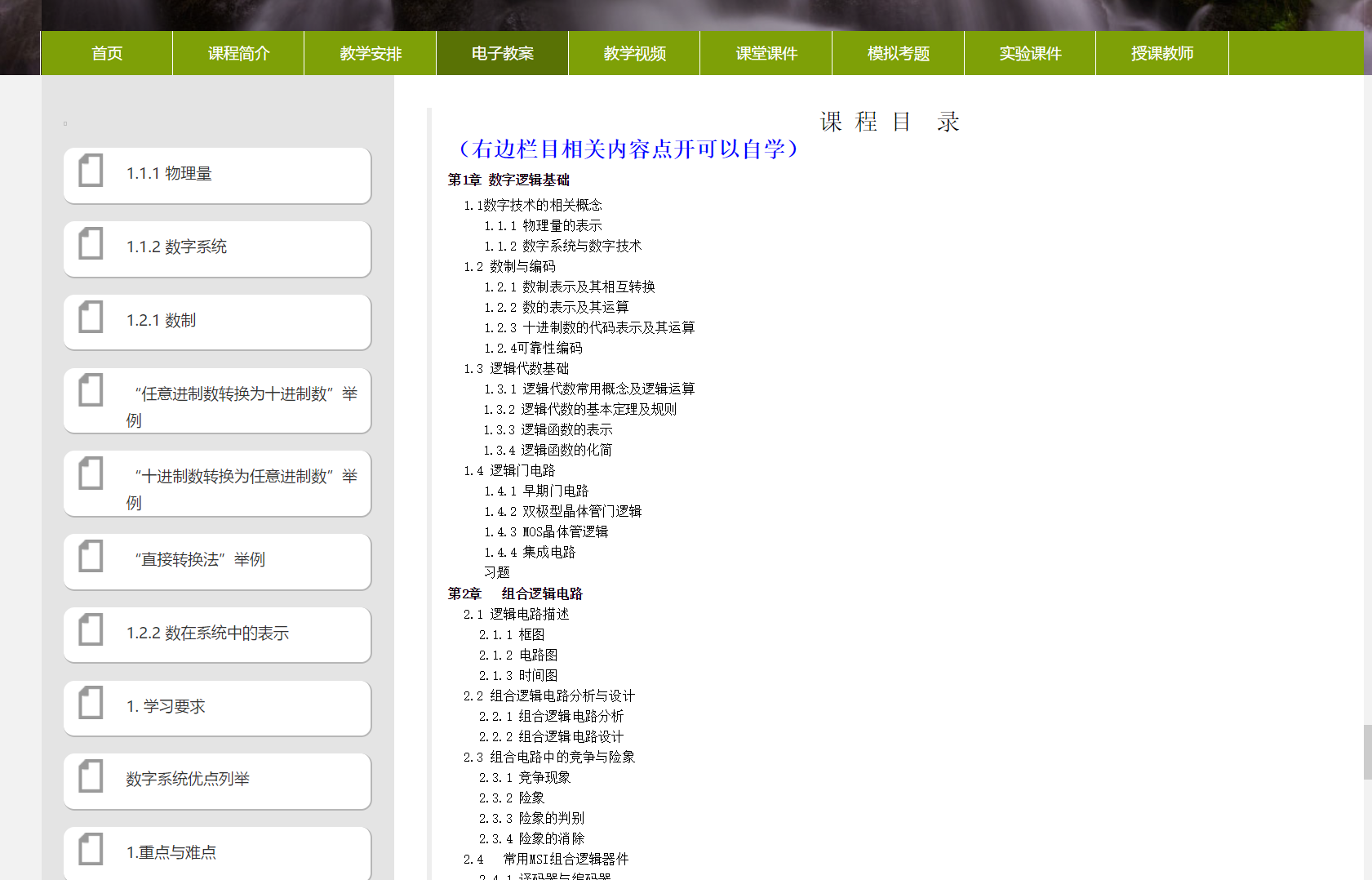
目标:将教案内容保存为pdf作为复习材料
首先在源代码中没有找到相关内容,即左边的列表和右边的内容都是生成的
刷新页面,查看XHR请求,找到页面规律和数据接口
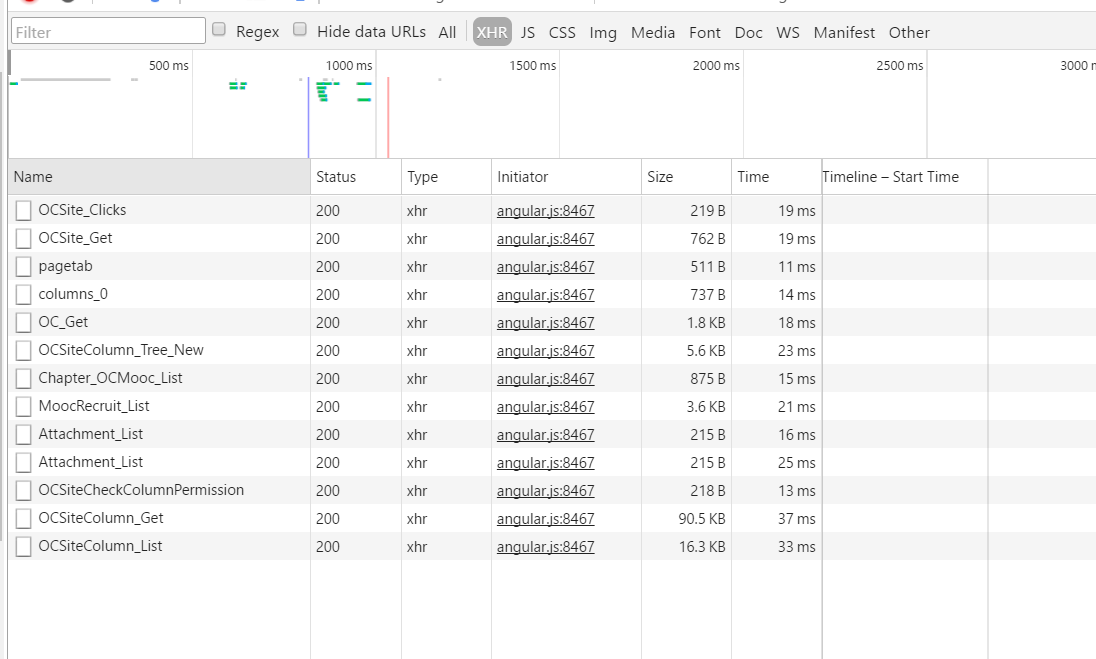
侧边栏的数据获取,数据个数与左边列表数目一致,id与列表的url对应
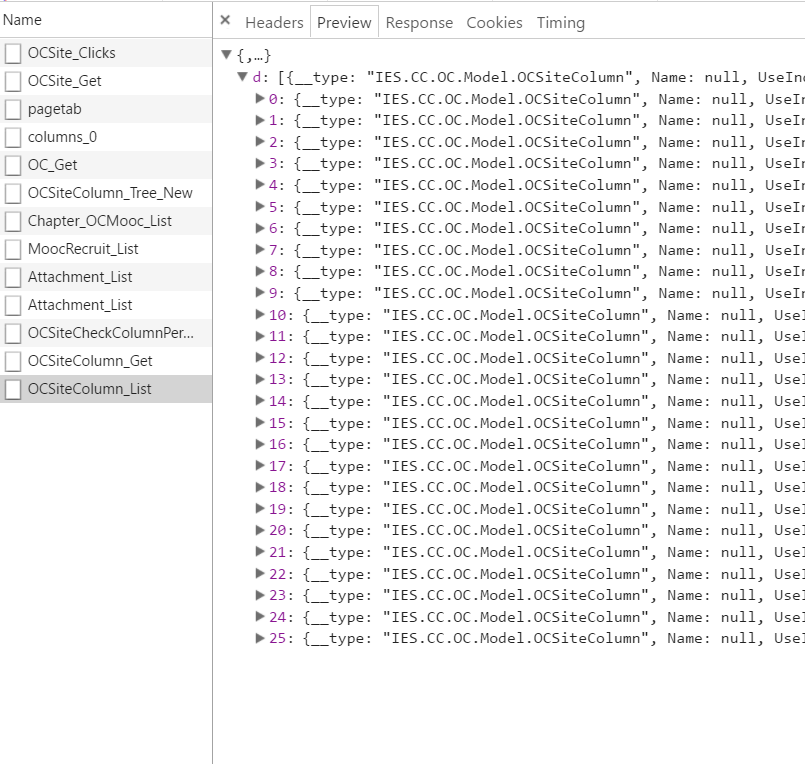
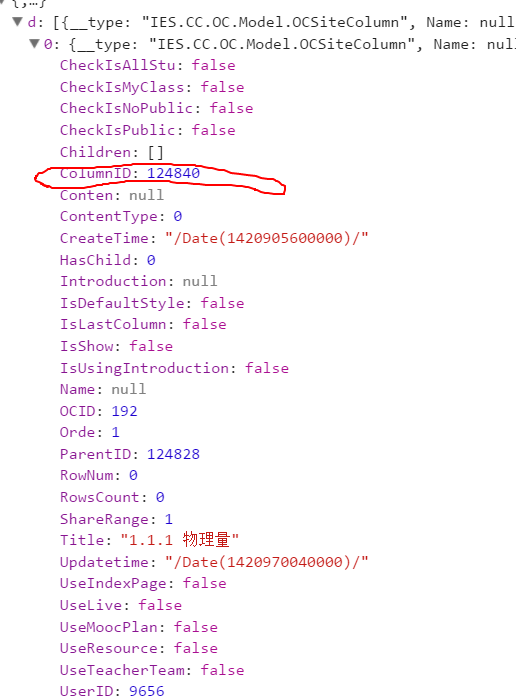
# 侧边栏的url
list_url = 'http://cc.xjtu.edu.cn/G2S/DataProvider/OC/Site/SiteProvider.aspx/OCSiteColumn_List'
with open('./html/list.json', encoding='utf8', mode='w+') as f:
text = requests.post(url, data=json.dumps({'ColumnID': '124828'}), headers=headers).text
f.write(text)
print(
text
)获取内容,内容在conten字段中,获取后直接保存即可
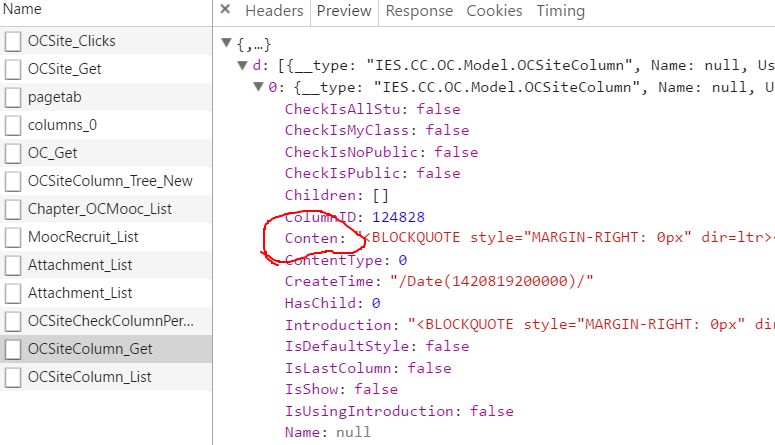
url = 'http://cc.xjtu.edu.cn/G2S/DataProvider/OC/Site/SiteProvider.aspx/OCSiteColumn_Get'
headers = {
'Host': 'cc.xjtu.edu.cn',
'Connection': 'keep-alive',
'Content-Length': '21',
'Accept': 'application/json, text/plain, */*',
'Origin': 'http://cc.xjtu.edu.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.3964.2 Safari/537.36',
'Content-Type': 'application/json;charset=UTF-8',
'Referer': 'http://cc.xjtu.edu.cn/G2S/site/preview',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cookie': 'ASP.NET_SessionId=ouwltyfoe4v1lshm4kscyvga',
}
print(
requests.post(url, data=json.dumps({'ColumnID': '124843'}), headers=headers).text
)获取所有教案信息并保存为对应的文件
import json
import requests
import pdfkit
headers = {
'Host': 'cc.xjtu.edu.cn',
'Connection': 'keep-alive',
'Content-Length': '21',
'Accept': 'application/json, text/plain, */*',
'Origin': 'http://cc.xjtu.edu.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.3964.2 Safari/537.36',
'Content-Type': 'application/json;charset=UTF-8',
'Referer': 'http://cc.xjtu.edu.cn/G2S/site/preview',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cookie': 'ASP.NET_SessionId=ouwltyfoe4v1lshm4kscyvga',
}
def saveHtml(uid):
url = 'http://cc.xjtu.edu.cn/G2S/DataProvider/OC/Site/SiteProvider.aspx/OCSiteColumn_Get'
with open(f"./html/{uid}.html", mode='w+', encoding='utf8') as f:
text = requests.post(url, data=json.dumps({'ColumnID': uid}), headers=headers).json()
f.write('<head><meta charset="UTF-8"> </head>' + text['d'][0]['Conten'])
def saveAll():
# saveHtml('124905')
with open('./html/t.json', mode='r', encoding='utf8') as f:
url_list = json.load(f)
for i in url_list['d']:
print(i['ColumnID'])
saveHtml(i['ColumnID'])
saveAll()
将html文件合并为pdf文件,注意内容乱码的解决是添加编码格式的标签
<head><meta charset="UTF-8"> </head>import pdfkit
import json
def savePdf():
with open('./html/t.json', encoding='utf8', mode='r') as f:
url_list = json.load(f)['d']
file_paths = [f"./html/{i['ColumnID']}.html" for i in url_list]
pdfkit.from_file(file_paths, 'out.pdf')
savePdf()
结果,感觉还是要挂啊,。。。。。