1.数值积分
数值积分是对定积分的数值求解,例如可以利用数值积分计算某个形状的面积。下面让我们来考虑一下如何计算半径为1的半圆的面积,根据圆的面积公式,其面积应该等于PI/2。单位半圆曲线可以用下面的函数表示:
def half_circle(x):
return (1-x**2)**0.5下面的程序使用经典的分小矩形计算面积总和的方式,计算出单位半圆的面积:

利用上述方式计算出的圆上一系列点的坐标,还可以用numpy.trapz进行数值积分:

此函数计算的是以x,y为顶点坐标的折线与X轴所夹的面积。同样的分割点数,trapz函数的结果更加接近精确值一些。
如果我们调用scipy.integrate库中的quad函数的话,将会得到非常精确的结果:

2.解常微分方程组
scipy.integrate库提供了数值积分和常微分方程组求解算法odeint。下面让我们来看看如何用odeint计算洛仑兹吸引子的轨迹。洛仑兹吸引子由下面的三个微分方程定义:
这三个方程定义了三维空间中各个坐标点上的速度矢量。从某个坐标开始沿着速度矢量进行积分,就可以计算出无质量点在此空间中的运动轨迹。其中 σ, ρ, β 为三个常数,不同的参数可以计算出不同的运动轨迹: x(t), y(t), z(t)。 当参数为某些值时,轨迹出现馄饨现象:即微小的初值差别也会显著地影响运动轨迹。下面是洛仑兹吸引子的轨迹计算和绘制程序:
# -*- coding: utf-8 -*-
from scipy.integrate import odeint
import numpy as np
def lorenz(w, t, p, r, b):
#给出位置矢量w,和三个参数p, r, b计算出 dx/dt, dy/dt, dz/dt的值
x, y, z = w
# 直接与lorenz的计算公式对应
return np.array([p*(y-x), x*(r-z)-y, x*y-b*z])
t = np.arange(0, 30, 0.01) # 创建时间点
#调用ode对lorenz进行求解, 用两个不同的初始值
track1 = odeint(lorenz, (0.0, 1.00, 0.0), t, args=(10.0, 28.0, 3.0))
track2 = odeint(lorenz, (0.0, 1.01, 0.0), t, args=(10.0, 28.0, 3.0))
#绘图
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
fig = plt.figure()
ax = Axes3D(fig)
ax.plot(track1[:,0], track1[:,1], track1[:,2])
ax.plot(track2[:,0], track2[:,1], track2[:,2])
plt.show()在程序中先定义一个lorenz函数,它的任务是计算出某个位置的各个方向的微分值,这个计算直接根据洛仑兹吸引子的公式得出。然后调用odeint,对微分方程求解,odeint有许多参数,这里用到的四个参数分别为:
- lorenz, 它是计算某个位移上的各个方向的速度(位移的微分)
- (0.0, 1.0, 0.0),位移初始值。计算常微分方程所需的各个变量的初始值
- t, 表示时间的数组,odeint对于此数组中的每个时间点进行求解,得出所有时间点的位置
- args, 这些参数直接传递给lorenz函数,因此它们都是常量
运行结果如下所示:
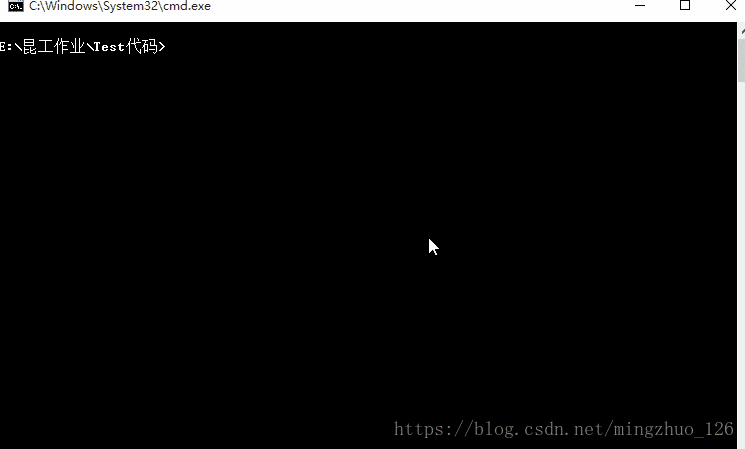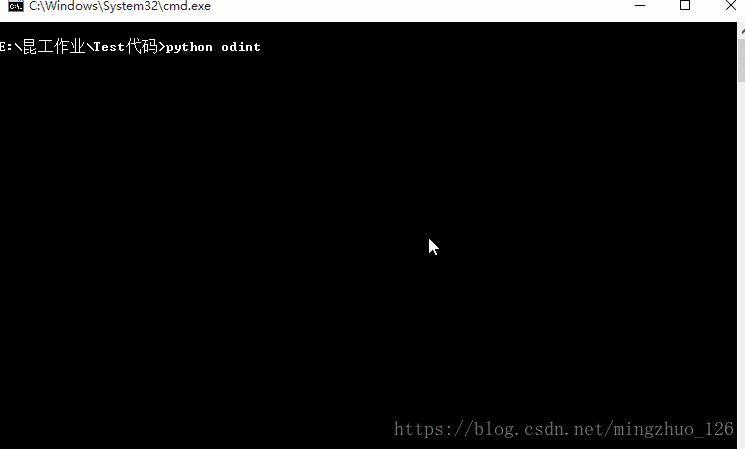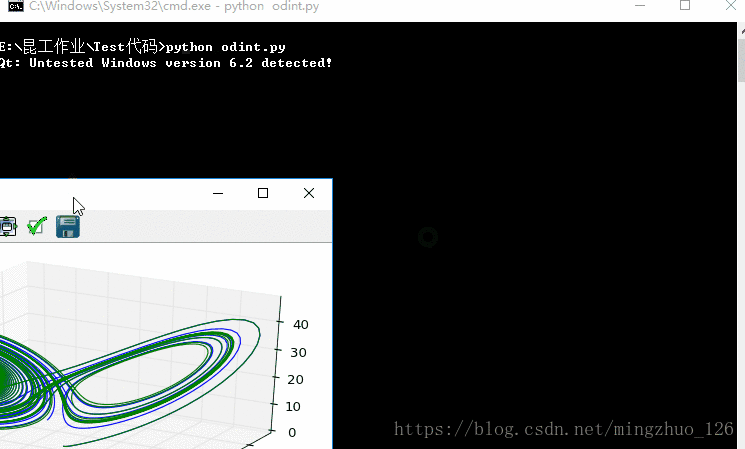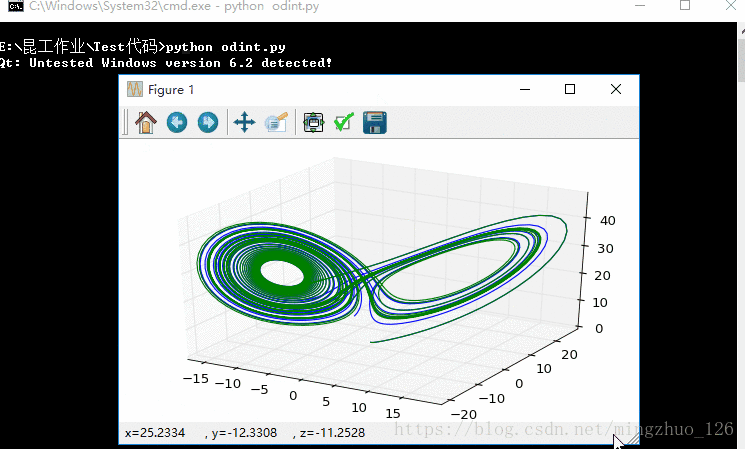
即使初始值只相差0.01,两条运动轨迹也是完全不同的。
3. 用Weave嵌入C语言
Python作为动态语言其功能虽然强大,但是在数值计算方面有一个最大的缺点:速度不够快。在Python级别的循环和计算的速度只有C语言程序的百分之一。SciPy提供了快速调用C++语言程序的方法– Weave。下面是对NumPy的数组求和的例子:
# -*- coding: utf-8 -*-
import scipy.weave as weave
import numpy as np
import time
def my_sum(a):
n=int(len(a))
code="""
int i;
double counter;
counter =0;
for(i=0;i<n;i++){
counter=counter+a(i);
}
return_val=counter;
"""
err=weave.inline(
code,['a','n'],
type_converters=weave.converters.blitz,
compiler="gcc"
)
return err
a = np.arange(0, 10000000, 1.0)
# 先调用一次my_sum,weave会自动对C语言进行编译,此后直接运行编译之后的代码
my_sum(a)
start = time.clock()
for i in xrange(100):
my_sum(a) #直接运行编译之后的代码
print "my_sum:",(time.clock() - start) / 100.0
start = time.clock()
for i in xrange(100):
np.sum(a) #numpy中的sum,其实现也是C语言级别
print"np.sum:",(time.clock() - start) / 100.0
start = time.clock()
sum(a) #Python内部函数sum通过数组a的迭代接口访问其每个元素,因此速度很慢
print"sum:", time.clock() - startweave.inline函数的第一个参数为需要执行的C++语言代码,第二个参数是一个列表,它告诉weave要把Python中的两个变量a和n传递给C++程序,注意我们用字符串表示变量名。converters.blitz是一个类型转换器,将numpy的数组类型转换为C++的blitz类。C++程序中的变量a不是一个数组,而是blitz类的实例,因此它使用a(i)获得其各个元素的值,而不是用a[i]。最后我们通过compiler参数告诉weave要采用gcc为C++编译器。
运行结果如下所示:

可以看到用Weave编译的C语言程序比numpy自带的sum函数还要快。而Python的内部函数sum使用数组的迭代器接口进行运算,因此速度是比较慢。