本篇博客我们讲一下从线性回归到逻辑回归的激活函数Sigmoid,
以及其优化loss函数cross entropy,及多分类函数softmax和其loss;
Sigmoid:
在之前介绍的线性回归当中也有涉及到sigmoid,其形式理解起来很简单,其背后的原理其实也没有那么复杂(相当于一个条件概率的变形如下图所示):
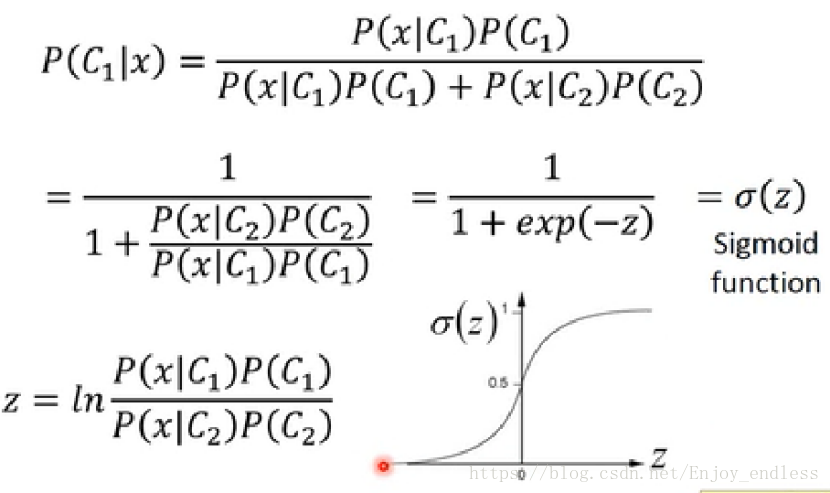
关于条件概率贝叶斯之前文章机器学习系列五已经有过详细介绍;在这里需要注意的一点是其只适用于二分类任务,如上公式所示:C1/C2;其背后原理以及形式均以上图展示不在赘述;
逻辑回归与线性回归的关系,其实就是应用了类似如上的激活函数,将其值压缩至一定范围并定义相应规则,在什么范围时属于哪一类:
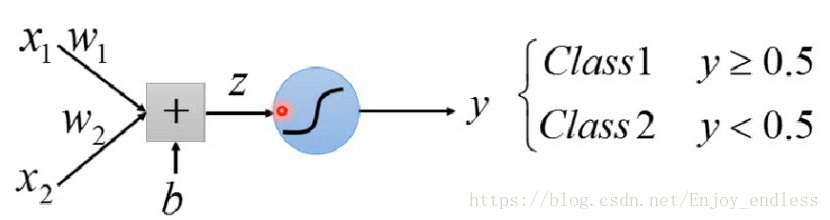
Cross Entropy:
Sigmoid函数实现了由线性回归到逻辑回归的转换,但是基于其自身的独特特点加上我们之前惯用的平方误差损失函数之后,其训练效果会出现一定问题,具体如下;
我们先来看一下机器学习的三个过程:
1、Define you function set(Model)
2、define you loss function based on training data
3、find the best function(Gradient Descent…..)
现在我们按照如上三步来利用sigmoid+Square Error函数走一下,如下所示:

如上function set为sigmoid,loss function为Square Error,我们对其求梯度结果如上(其中对z求导部分如下):
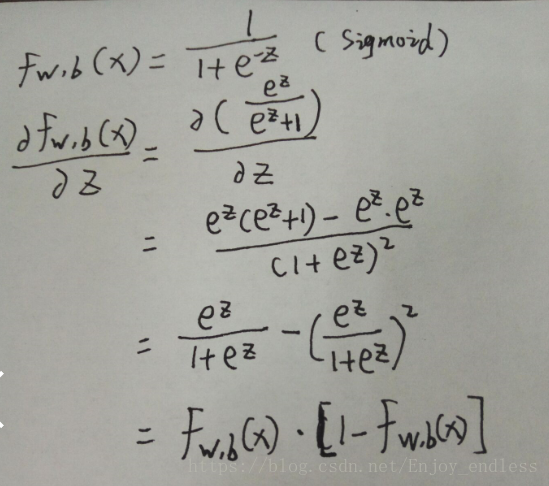
对于以上求导结果,我们假设真实值y为1,当估计值也为1或非常接近1时,或者当估计值为0或非常接近于0时,那么求得其梯度值都将为0,梯度值为0意味着更新的脚步非常缓慢乃至停滞,这就是之前用到最多的Square Error在结合了sigmoid函数之后所出现的最大问题所在;如下图所示:
图中下方的红色网格表示的就是Sigmoid+Square Error,我们根据图可以看到在远离中心最低点以及靠近中心最低点的地方,其图形的变化都是非常缓和的;也就是随着参数w的变化其Total loss基本上是没大变化的;而其上的黑色网格与其形成鲜明对比,下面我们来介绍学习一下新的优化的损失函数Cross Entropy:
关于其背后的原理在这里不在深究,可参见链接:https://www.zhihu.com/question/65288314/answer/230209104,我们来看一下其表达形式:
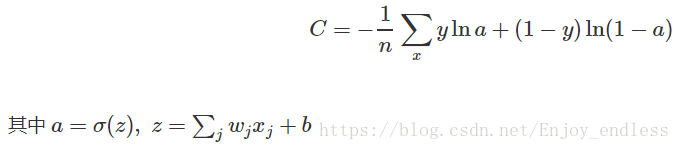
其中y:1 for class 1,0 for class 2; n为样本个数;
我们将其对参数w、b进行求梯度结果如下:

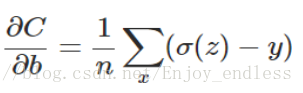
从公式可以看到其梯度的大小也即更新速度的大小直接取决于预测值与真实值y的差值,而不是原来的Sigmoid函数的导数值;其最终的表现结果即上图中黑色网格所示更新速度明显加快;
Softmax:
如之前所述的Sigmoid函数是进行二分类任务的,而softmax可以说是作为sigmoid的推广,其可用于多分类任务:

如图所示,假设样本总共三个类别C1、C2、C3,样本经卷积、全连接处理之后输入到最后的softmax层,其输出为样本属于每个类别的概率大小(其计算过程如图所示),最后选择概率最大的最为样本的类别;知道了softmax的原理及计算过程之后我们来看一下其损失函数:
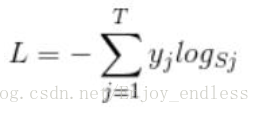
其中Sj为样本对应的每个标签的概率值即softmax的输出,而Yj表示的是该样本类别是否为标签j(只取值0/1),其实其求和之后最后值表示为-log(Sj),此时的Sj单指最后选取的标签概率值;可以看到,当Sj较大时其loss值是较小的;
另一方面我们可以看出softmax loss函数与cross entropy是如此的相似,他们之间有着千丝万缕的关系:当cross entropy的输入P是softmax的输出时,cross entropy等于softmax loss。那么其优点也将与cross entropy相同!