这些概念有点混,借此梳理记录一下。
sigmoid
sigmoid函数是常用的二分类函数,函数形式为:
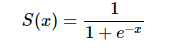
曲线形式如下:
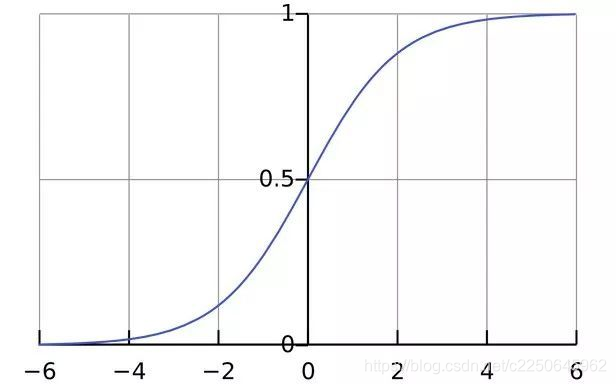
Sigmoid 是一个可微的有界函数,在各点均有非负的导数。当 x→∞ 时,S(x)→1;当 x→−∞ 时,S(x)→0。常用于二元分类(Binary Classification)问题,以及神经网络的激活函数(Activation Function)(把线性的输入转换为非线性的输出)。
Softmax
函数形式为:
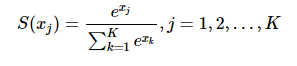
对于一个长度为 K 的任意实数矢量,Softmax 可以把它压缩为一个长度为 K 的、取值在 (0, 1) 区间的实数矢量,且矢量中各元素之和为 1。它在多元分类(Multiclass Classification)和神经网络中也有很多应用。Softmax 不同于普通的 max 函数:max 函数只输出最大的那个值,而 Softmax 则确保较小的值也有较小的概率,不会被直接舍弃掉,是一个比较“Soft”的“max”。
Softmax函数的分母综合了原始输出值的所有因素,这意味着,Softmax函数得到的不同概率之间相互关联
在二元分类的情况下,对于 Sigmod,有:
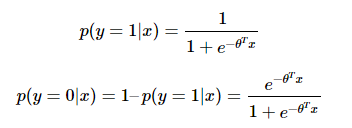
而对 K=2 的 Softmax ,有:

其中:
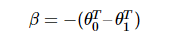
可见在二元分类的情况下,Softmax 退化为了 Sigmoid。
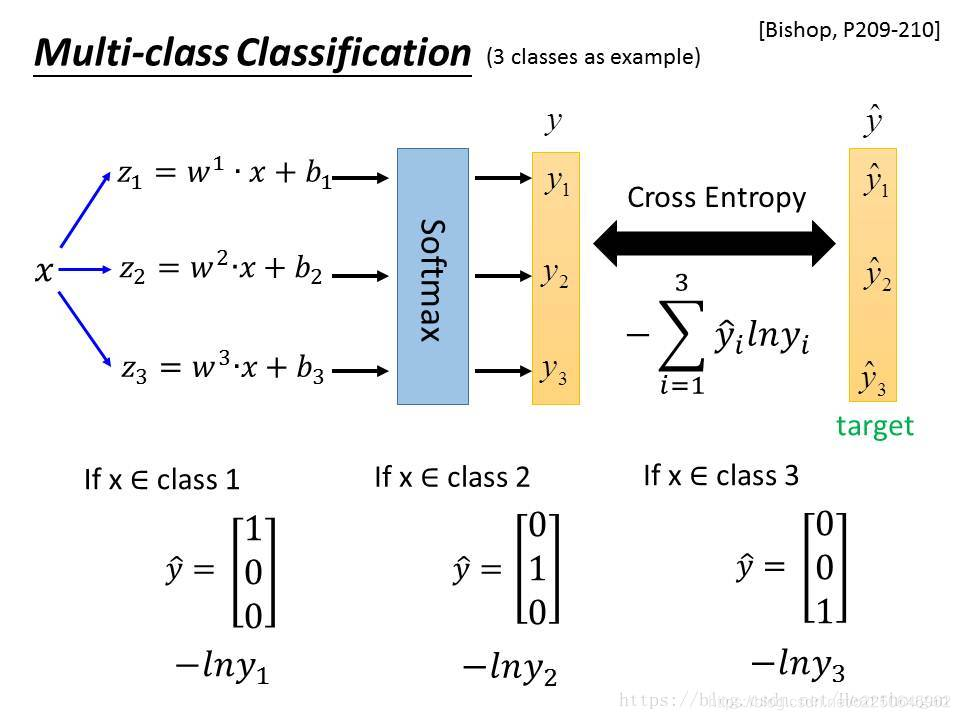
Softmax loss
softmax loss函数是指针对softmax分类器的损失函数,其定义为:
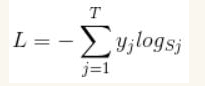
首先L是损失。Sj是softmax的输出向量S的第j个值,表示的是这个样本属于第j个类别的概率。yj前面有个求和符号,j的范围也是1到类别数T,因此y是一个1*T的向量,里面的T个值,而且只有1个值是1,其他T-1个值都是0。那么哪个位置的值是1呢?答案是真实标签对应的位置的那个值是1,其他都是0。所以结果为:
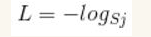
j指向当前样本的真实标签。假设一个5分类问题,然后一个样本I的标签y=[0,0,0,1,0],也就是说样本I的真实标签是4,假设模型预测的结果概率(softmax的输出)p=[0.2,0.3,0.4,0.6,0.5],可以看出这个预测是对的,那么对应的损失L=-log(0.6)。
Cross entropy
假设p和q是关于样本集的两个分布,其中p是样本集的真实分布,q是样本集的估计分布,那么按照真实分布p来衡量识别一个样本所需要编码长度的期望(即,平均编码长度):
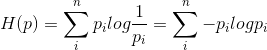
如果用估计分布q来表示真实分布p的平均编码长度,应为:
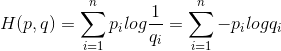
这就是交叉熵。
看起来与Softmax loss很像,
在神经网络后面添加Softmax,真实的标签(或者是类别)就相当于真实的分布,经过Softmax得出的值就是预测的结果,当cross entropy的输入q是softmax的输出时,cross entropy等于softmax loss。
relative entropy
相对熵,也叫KL散度,是衡量两个概率分布之间的差异。
在机器学习中,比如分类问题,如果把结果当作是概率分布来看,标签表示的就是数据真实的概率分布,由softmax函数产生的结果其实是对于数据的预测分布,预测分布和真实分布差值叫做KL散度或者是相对熵。
相对熵又等于交叉熵减去数据真实分布的熵,即
KL散度 = H(p,q) - H§
