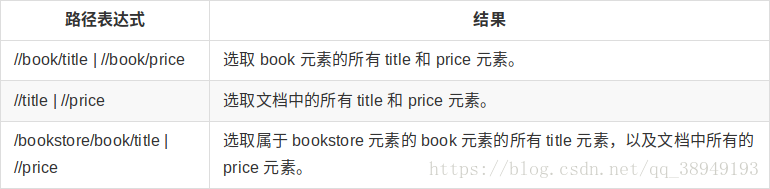
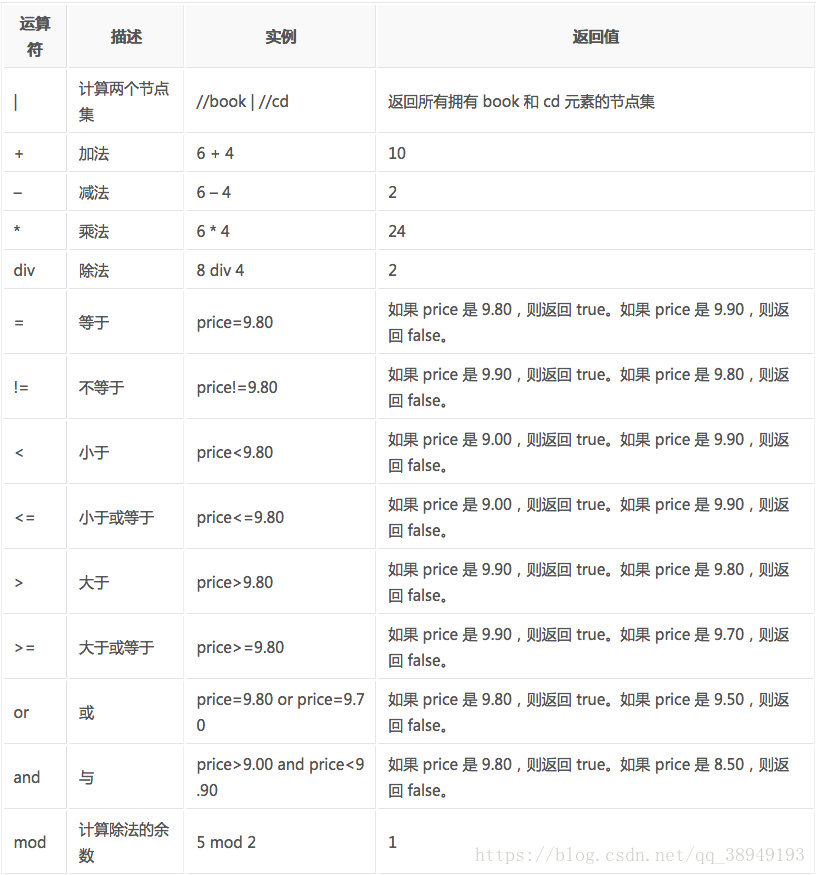
如果使用正则表达式提取页面数据会相当的麻烦,那么有没有一种比较简单的解析工具?
有!那就是XPath,我们可以先将 HTML文件 转换成 XML文档,然后用 XPath 查找 HTML 节点或元素。
什么是XPath?
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
安装lxml
安装lxml库,lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据
通过pip安装:pip install lxml
使用XPath
获取标签下面的文本内容
from lxml import html
html_text = '''<html>
<body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body>
</html>'''
#把html文档转换成树结构的文档
content = html.etree.HTML(html_text)
#使用xpath提取数据,提取class为item=0的li标签下a标签下的文本内容
result = content.xpath('//li[@class="item-0"]/a/text()')
print(result)
#输出结果
['first item', 'fifth item']获取标签的属性内容,很多时候需要获取img标签的src,a标签的href,当然不管是什么属性内容都可以获取到
from lxml import html
html_text = '''<html>
<body>
<div>
<ul>
<li class="item-0"><a href="www.haha.com/link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<div id='box'><img src='www.example.com'></div>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
</ul>
</div>
</body>
</html>'''
#把html文档转换成树结构的文档
content = html.etree.HTML(html_text)
#使用xpath提取数据
href = content.xpath('//li[@class="item-0"]/a/@href')
src = content.xpath('//div[@id="box"]/img/@src')
print(href)
print(src)
#输出结果
['www.haha.com/link1.html']
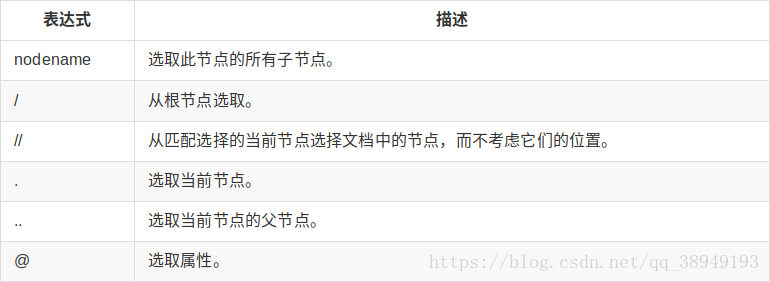
['www.example.com']XPath语法


扫描二维码关注公众号,回复:
2427570 查看本文章