一. 引入
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中
查找信息地语言。它最初是用来搜寻XML文档的,而XML文档与HTML文档关系紧密,Xpath同样适用于HTML文档的搜索。
二. 安装
pip install lxml
三. 快速开始
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">It's a good story</p>
<p>
<!--Hey, buddy. Want to buy a used parser?-->
</p>
"""
from lxml import etree
html = etree.HTML(html_doc)
result = etree.tostring(html)
print(result.decode('utf-8'))
- 这里首先导入 lxml库的etree模块,然后声明了一段HTML文本,调用HTML类进行初始化,这样就构成了一个XPath解析对象。这样需要注意的是,HTML文本中 html 和 body节点是没有闭合的,但etree模块可以自动修正HTML文本。 这里的 tostring()方法即可输出修正后的HTML代码,但是结果是bytes类型。这里利用decode()方法转化成str类型,结果如下:

- 两种使用方式:
- 本地文件:
tree = etree.parse('文件名')
ret =tree.xpath(路径表达式)
- 网页字符串:
tree = etree.HTML('网页字符串')
ret =tree.xpath(路径表达式)
四. Xpath 常用规则

五. 获取节点
- 获取所有节点,我们一般会用 // 开头的 XPath规则来获取所有符合要求的节点。如下图所示:

这里使用 * 代表所有节点,也就是整个HTML文档中的所有节点都会被获取。可以看到,返回形式是一个列表,每个元素是Element类型,其后跟了节点的名称,如 html、body、p等,所有节点都包含在列表中了。
-
选取指定节点名称,如果想获得所有的 p 节点,示例如下:

-
获取子节点,我们通过 / 或 // 即可查找元素的子节点或子孙节点。假如现在想选择 p节点的所有直接的a子节点,可以这样实现:
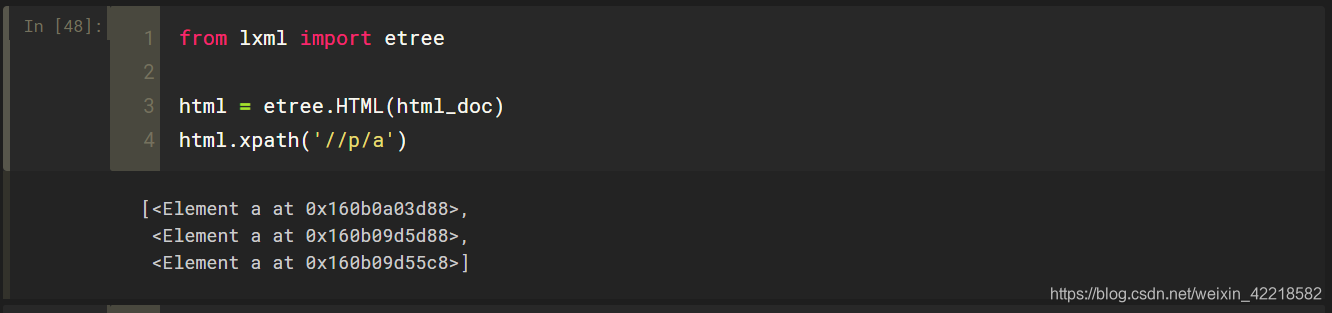
这里我们通过追加 /a 即选择了所有p节点的所有直接a节点。因为 //p 用于选中所有p节点,/a 用于选中p节点的所有直接子节点,二者结合在一起获取所有p节点的所有直接a节点。但是如果这里用了 //body/a,就无法获取到任何结果了。因为 / 用于获取直接子节点,而在 body节点下并没有直接的 a 节点,只有 p 节点和 dt 节点,所以无法获取任何匹配结果,代码如下:

因此,我们要注意 / 和 // 的区别,其中 / 用于获取直接子节点,// 用于获取子孙节点 -
获取父节点,我们知道通过连续的 / 或 //可以查找 子节点或子孙节点,那么假如我们知道子节点,怎样来查找父节点呢?可以使用 ..
比如,现在首先选中 id 属性为 link1的a节点,然后在获取其父节点,然后再取其 class属性,相关代码如下:

- 属性匹配,在选取的时候,我们还可以用 @ 符号进行属性过滤。比如,这里如果要选取 class 属性为 title 的 p 节点,可以这样实现:

这里我们通过假如 [@class=“title”],限制了节点的class属性为 title,而HTML文本中符合条件的p节点只有一个,即上图所返回的结果。

-
文本获取,我们用XPath中的 text()方法获取节点中的文本,接下来尝试获取 所有 p 节点的文本,代码如下:

另一种,获得方法,代码如下:

p.text 方法 获得到的是 p节点 直接子节点中的文本,第一个 p 节点中的直接子节点并没有文本内容,所以返回为 None -
属性获取,我们知道可以使用 text() 方法获取节点内部文本,那么节点属性该怎样获取呢?其实还是 用 @符号就可以。比如,我们想获取所有 a 节点的 href 属性,代码如下:

这里我们通过 @href即可获取节点的href属性。注意,此处和属性匹配的方法不同,属性匹配是中括号加属性名和值来限定某个属性,如 [@href=“story”],而此处的@href指的是获取节点的某个属性,二者要注意区分。
-
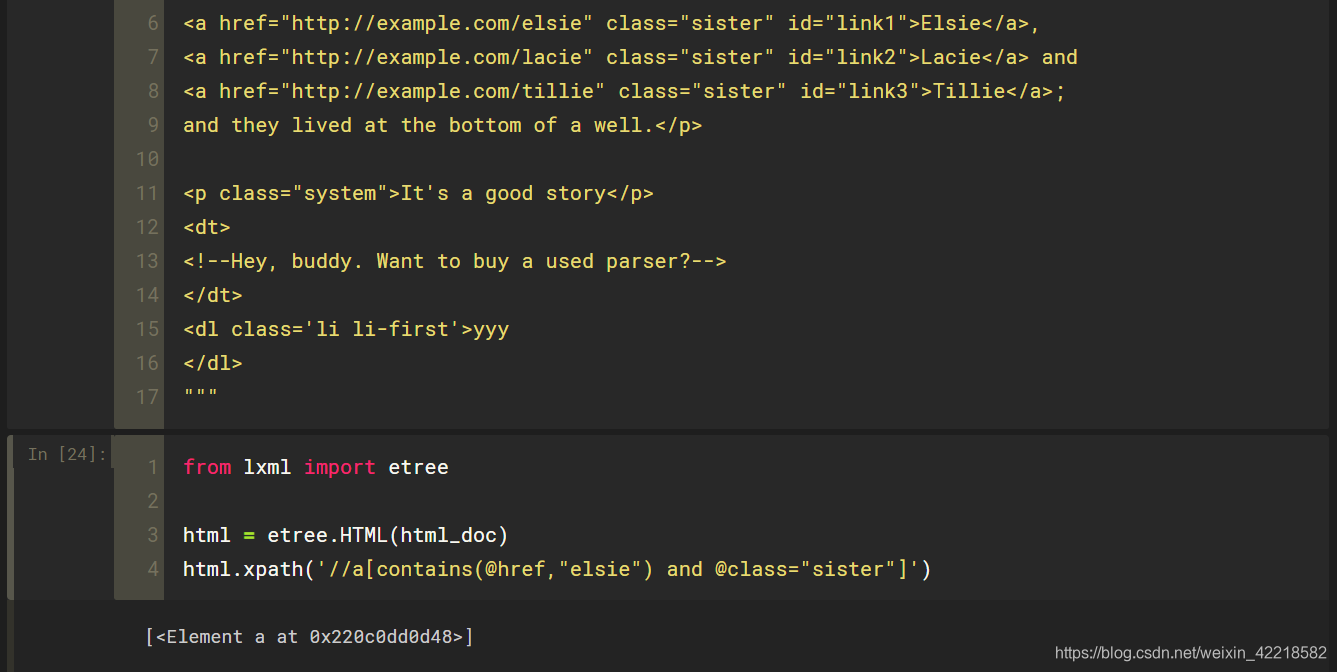
属性多值匹配,有时候,某些节点的某个属性可能有多个值,例如,节点 dl,class属性有两个值 li 和 li-first,此时需要使用 contains() 函数进行匹配,运行结果如下:

- 多属性匹配,还可能遇到这种情况,那就是根据多个属性来确定一个节点,这时就需要同时匹配多个属性。此时可以使用运算符 and 来连接,如下:
这里的 and 其实是 XPath中的运算符。另外,还有很多运算符,如 or mod 等,在此总结如下表所示:

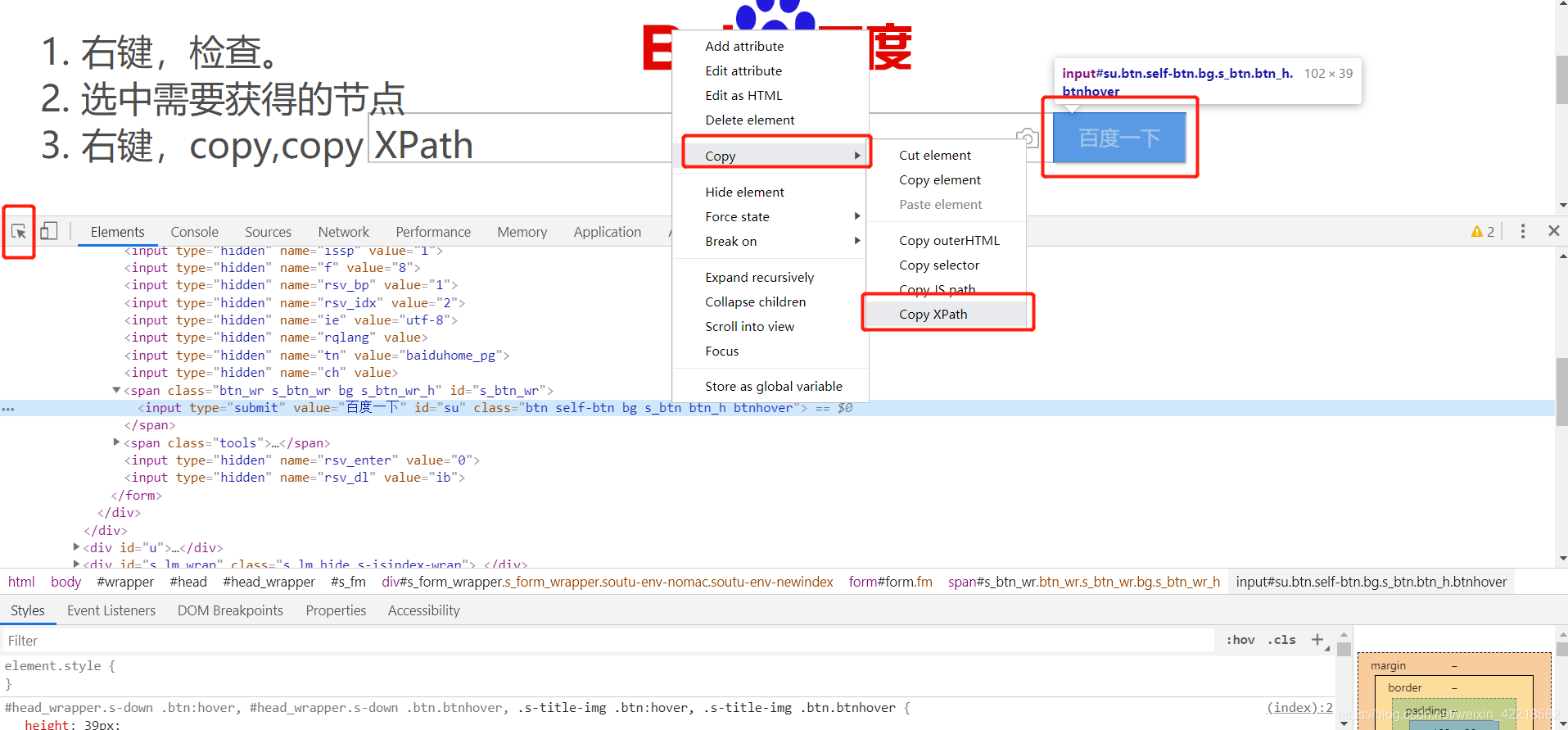
六. chrome插件XPath Helper 工具 安装 与 使用
-
下载,由于目前 谷歌商店 没有 FQ 是访问不了的,这里,我将已经下载好的,打包放在网盘中,供大家下载。
链接:https://pan.baidu.com/s/13cnVKhBQeM8Tv2vAEmdiXA
提取码:n8bj -
安装方法:
下载到本地,打开 chrome浏览器,进入设置,点击扩展程序,将下载好的 .crx后缀文件拖入扩展程序即可。
-
使用方法:
打开网页后,快捷键 ctrl + shift + x 来使用插件。 结果如下:

可以在 query中写 XPath 路径表达式,进行测试。当然,还有一种方法,直接复制 浏览器中某个节点的XPath 路径表达式: