问题
个人遇到问题,参考性可能不大
网址:https://trains.ctrip.com/trainbooking/TrainSchedule/D677/
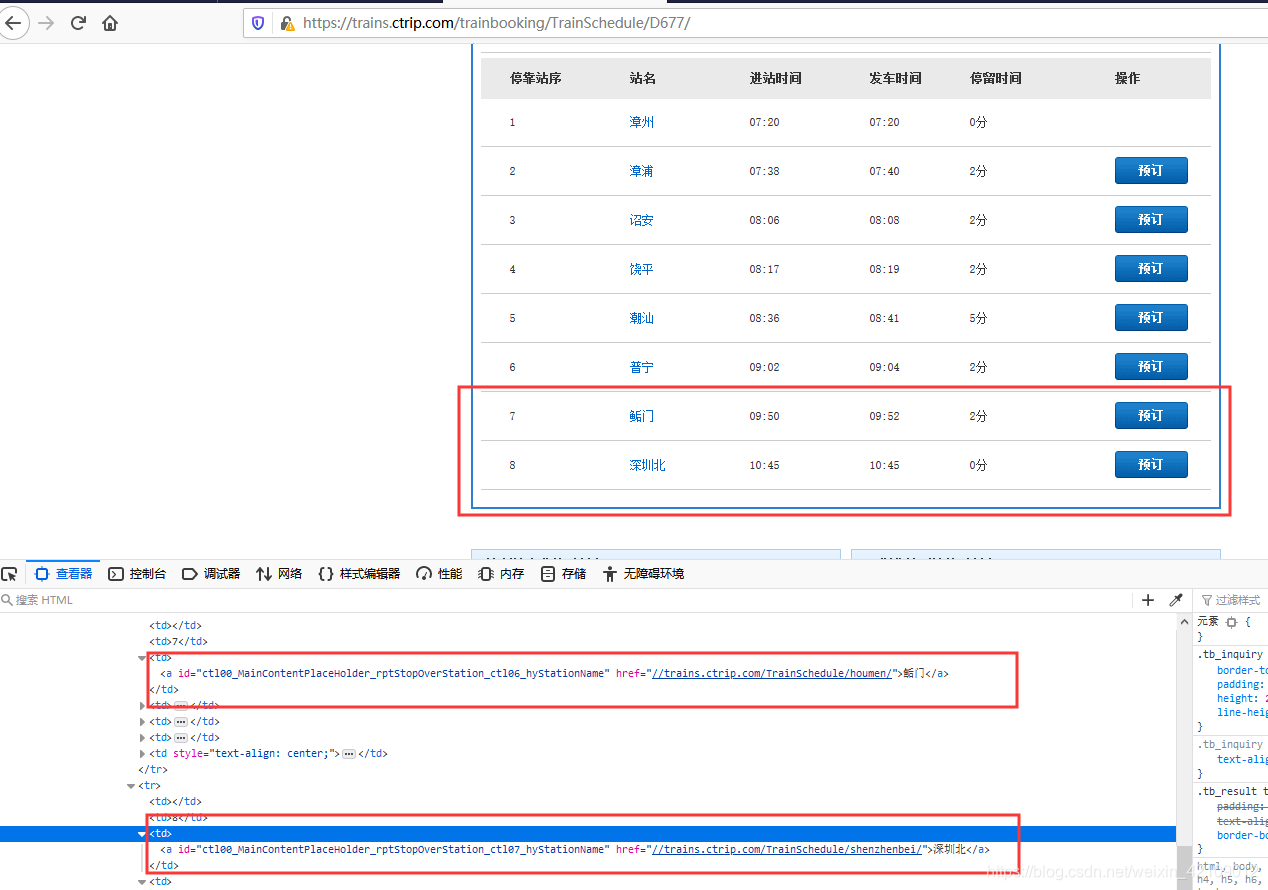
今天爬取携程火车车次信息,开始运行结果好好的,但是运行到这里时出现了错误,报错是超出列表范围。
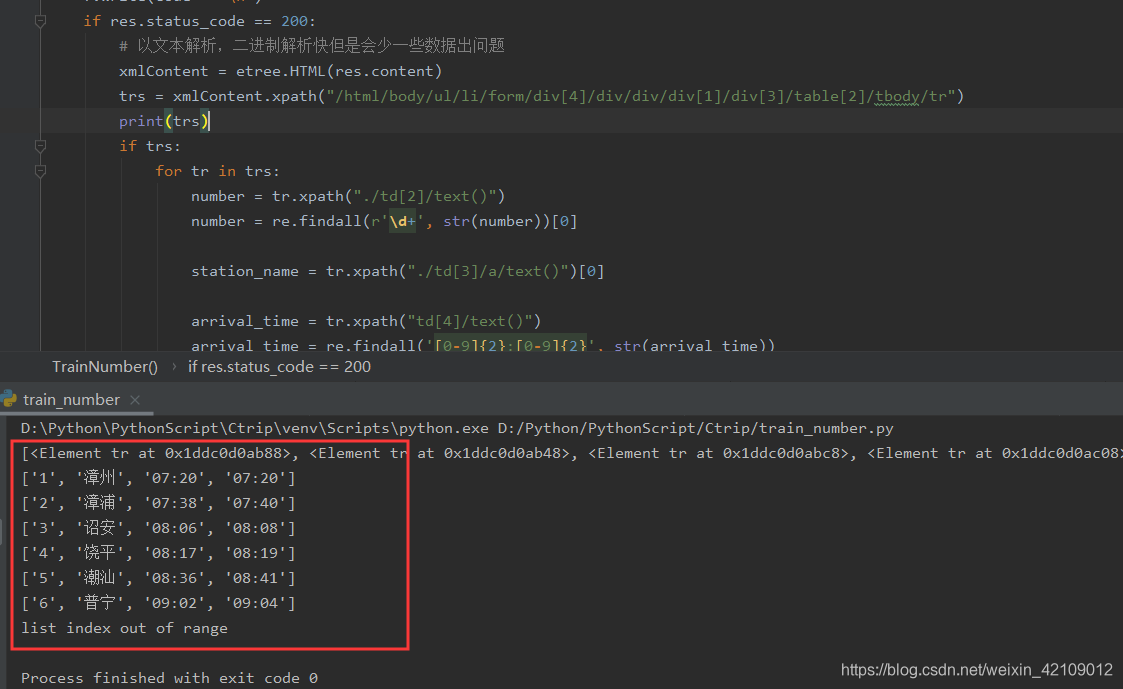
我仔细查看发现是:lxml.etree.HTML.xpath 解析网页不完整,网页明明有 8 个数据,结果只能读取 7 个数据,且 第七个数据不能解析,结果只能返回 6 个数据,程序终止。
解决
1、尝试
我想了一上午都没想出来,试了很多办法:
- 仔细检查路径,改为绝对路径,查看是否要tbody,还是不行。
- 查看HTML是否能下载完全,发现能够得到完全HTML。

2、解决
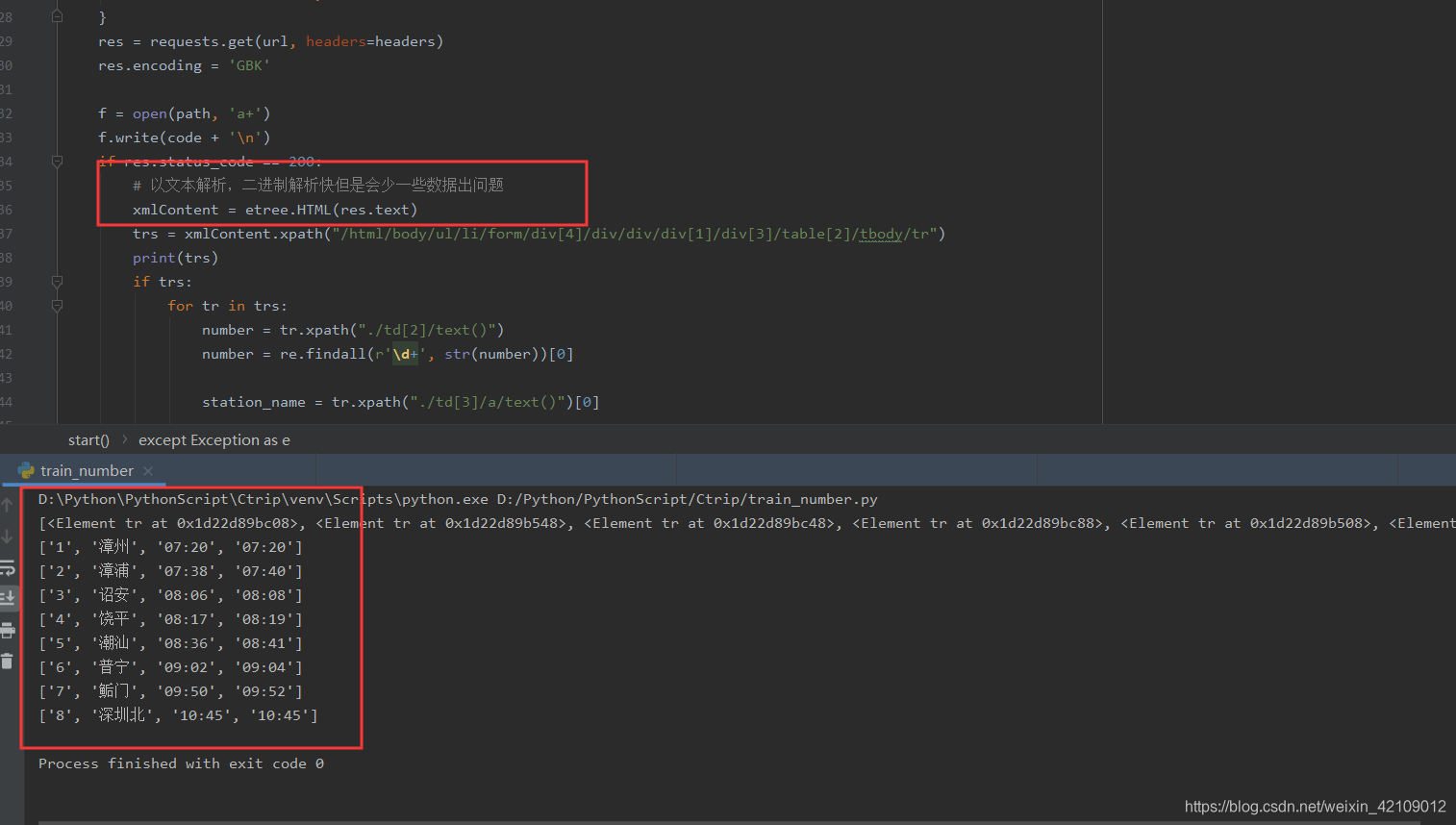
最后无意将HTML加载格式改了一下,竟然问题解决了,原来我习惯以二进制解析 res.content ,解析速度快,无意改成文本解 res.text 析问题解决了,可能是解析长度问题吧。
总结
声明这个不是解析不出来,而是解析不完整。
在解决这个问题查找了很久,也遇到很多类似的问题
xpath解析不到数据
(1)可能是路径出问题了
(2)如果用谷歌直接提取 full xpath,可能是浏览器渲染问题,浏览器会给表格添加一个 tbody ,本来没有的,所以需要去掉
(3)其实最好根据下载下来的 HTML,一步一步的查看,不过麻烦。(出问题了在这样,平时提取一般没问题)
代码
# !/usr/bin/python
# -*- coding: utf-8 -*-
# @Time : 2019/11/1 17:55
# @Author : ljf
# @File : train_number.py
import random
import time
import re
import requests
from lxml import etree
import mysql
def TrainNumber(code, path):
"""
Args:
code: 修改车次
path: 保存路径
Returns: 无
"""
url = "https://trains.ctrip.com/trainbooking/TrainSchedule/{}/".format(code)
headers = {
"Host": "trains.ctrip.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0",
"Referer": "https://trains.ctrip.com/trainbooking/TrainSchedule",
"Connection": "close",
}
res = requests.get(url, headers=headers)
res.encoding = 'GBK'
f = open(path, 'a+')
f.write(code + '\n')
if res.status_code == 200:
# 以文本解析,二进制解析快但是会少一些数据出问题
xmlContent = etree.HTML(res.text)
trs = xmlContent.xpath("/html/body/ul/li/form/div[4]/div/div/div[1]/div[3]/table[2]/tbody/tr")
if trs:
for tr in trs:
number = tr.xpath("./td[2]/text()")
number = re.findall(r'\d+', str(number))[0]
station_name = tr.xpath("./td[3]/a/text()")[0]
arrival_time = tr.xpath("td[4]/text()")
arrival_time = re.findall('[0-9]{2}:[0-9]{2}', str(arrival_time))
if arrival_time:
arrival_time = arrival_time[0]
else:
arrival_time = ""
depart_time = tr.xpath("td[5]/text()")
depart_time = re.findall('[0-9]{2}:[0-9]{2}', str(depart_time))[0]
info = [number, station_name, arrival_time, depart_time]
f.write(str(info) + '\n')
print(info)
f.write('\n')
f.close()
def start():
"""
条件准备
"""
number_path = "./Train_NumberInfo.txt"
sql = "SELECT code FROM t_number"
codes = mysql.mysql_select_12306(sql)
num = len(codes)
for i in range(0, num):
code = codes[i][0]
try:
TrainNumber(code, number_path)
print("{} 车次下载完毕!".format(codes[i][0]))
except Exception as e:
print(e)
finally:
# 随机延时4~8秒
time.sleep(random.randint(4, 8))
if __name__ == "__main__":
start()
