随机森林
1.随机森林原理:
随机森林由Leo Breiman(2001)提出的一种分类算法,它通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取n个样本生成新的训练样本集合训练决策树,然后按以上步骤生成m棵决策树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于独立抽取的样本。
单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样本可以通过每一棵树的分类结果经统计后选择最可能的分类。
随机森林大致过程如下:
1)从样本集中有放回随机采样选出n个样本;
2)从所有特征中随机选择k个特征,对选出的样本利用这些特征建立决策树(一般是CART,也可是别的或混合);
3)重复以上两步m次,即生成m棵决策树,形成随机森林;
4)对于新数据,经过每棵树决策,最后投票确认分到哪一类。
2.随机森林特点:
随机森林有很多优点:
1) 每棵树都选择部分样本及部分特征,一定程度避免过拟合;
2) 每棵树随机选择样本并随机选择特征,使得具有很好的抗噪能力,性能稳定;
3) 能处理很高维度的数据,并且不用做特征选择;
4) 适合并行计算;
5) 实现比较简单;
缺点:
1) 参数较复杂;
2) 模型训练和预测都比较慢。
3.使用:
随机森林算法在大部分数据处理软件中都有实现,使用时可以直接调用,只需指定所需参数。
随机森林模型训练前要设置的参数较多,按PAI平台的实现有如下几个:
o 算法类型:(可选)可供选择的算法类型有id3算法、cart算法、c4.5算法以及默认情况下的将上述三种算法均分的混合算法
o 树的数目:森林中树的个数, 范围(0, 1000]
o 随机属性个数:(可选)单颗树在生成时,每次选择最优特征,随机的特征个数。可供选择的类型有logN,N/3,sqrtN,N四种类型,其中N为属性总数
o 树最大深度:(可选)单颗树的最大深度,范围[1, ∞),-1表示完全生长。
o 叶子节点最少记录数:(可选)叶节点数据的最小个数。最小个数为2
o 叶子节点最少记录百分比:(可选)叶节点数据个数占父节点的最小比例,范围[0,100],-1表示无限制。默认-1
o 每棵树最大记录数:(可选)森林中单颗树输入的随机数据的个数。范围为(1000, 1000000]
4.模型评估:
算法模型建立后需要进行评估,以判断模型的优劣。一般使用训练集 (training set) 建立模型,使用测试集 (test set) 来评估模型。对于分类算法评估指标有分类准确度、召回率、虚警率和精确度等。而这些指标都是基于混淆矩阵 (confusion matrix) 进行计算的。
混淆矩阵用来评价监督式学习模型的精确性,矩阵的每一列代表一个类的实例预测,而每一行表示一个实际的类的实例。以二分类问题为例,如下表所示: 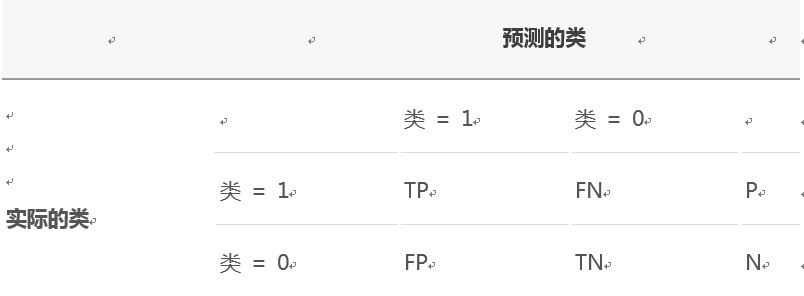
其中
P (Positive Sample):正例的样本数量。
N (Negative Sample):负例的样本数量。
TP (True Positive):正确预测到的正例的数量。
FP (False Positive):把负例预测成正例的数量。
FN (False Negative):把正例预测成负例的数量。
TN (True Negative):正确预测到的负例的数量。
根据混淆矩阵可以得到评价分类模型的指标有以下几种。
分类准确度,就是正负样本分别被正确分类的概率,计算公式为: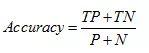
召回率,就是正样本被识别出的概率,计算公式为: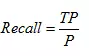
虚警率,就是负样本被错误分为正样本的概率,计算公式为: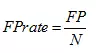
精确度,就是分类结果为正样本的情况真实性程度,计算公式为: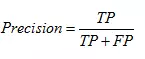
评估方法有保留法、随机二次抽样、交叉验证和自助法等。
保留法 (holdout) 是评估分类模型性能的最基本的一种方法。将被标记的原始数据集分成训练集和检验集两份,训练集用于训练分类模型,检验集用于评估分类模型性能。但此方法不适用样本较小的情况,模型可能高度依赖训练集和检验集的构成。
随机二次抽样 (random subsampling) 是指多次重复使用保留方法来改进分类器评估方法。同样此方法也不适用训练集数量不足的情况,而且也可能造成有些数据未被用于训练集。
交叉验证 (cross-validation) 是指把数据分成数量相同的 k 份,每次使用数据进行分类时,选择其中一份作为检验集,剩下的 k-1 份为训练集,重复 k 次,正好使得每一份数据都被用于一次检验集 k-1 次训练集。该方法的优点是尽可能多的数据作为训练集数据,每一次训练集数据和检验集数据都是相互独立的,并且完全覆盖了整个数据集。也存在一个缺点,就是分类模型运行了 K 次,计算开销较大。
自助法 (bootstrap) 是指在其方法中,训练集数据采用的是有放回的抽样,即已经选取为训练集的数据又被放回原来的数据集中,使得该数据有机会能被再一次抽取。用于样本数不多的情况下,效果很好。
其它类似算法
1.Bagging
Bagging算法与随机森林类似,区别是每棵树都使用所有特征,而不是只选择部分特征。该算法过程如下:
1)从样本集中随机采样选出n个样本;
2)在所有属性上,对这n个样本建立分类器(CART or SVM or …);
3)重复以上两步m次,即生成m个分类器(CART or SVM or …);
4)将数据放在这m个分类器上跑,最后投票确认分到哪一类。
2.GBDT
GBDT(Gradient Boosting Decision Tree)是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终结果。被认为是泛化能力较强的一种算法。
GBDT是一个应用很广泛的算法,可以用来做分类、回归。GBDT还有其他名字,比如MART(Multiple Additive Regression Tree),GBRT(Gradient Boosting Regression Tree),Tree Net等。
GBDT与C4.5等分类树不同,它是回归树。区别在于,回归树的每个结点(不一定是叶子结点)都会得到一个预测值,以年龄为例,该预测值等于属于这个结点的所有人年龄的平均值。分支时穷举每个特征找到最好的一个进行分支,但衡量最好的标准不再是信息增益,而是最小化均方差,如 (每个人的年龄 – 预测年龄)^2的总和 / N。也就是被预测出错的人数越多,错的越离谱,均方差就越大,通过最小化均方差能够找到最可靠的分支依据。分支直到每个叶子结点上人的年龄都唯一或者达到预设的终止条件(如叶子个数上限)。若最终叶子结点上人的年龄不唯一,则以结点上所有人的平均年龄做为该叶子结点的预测年龄。
梯度迭代(Gradient Boosting),即通过迭代多棵树来共同决策。GBDT的核心就在于,每棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能等到真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12 岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子结点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学习。
GBDT具体实现请自行查阅。
sklearn实现随机森林
# coding: utf-8
from sklearn.ensemble import RandomForestClassifier
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
class RF:
def __init__(self):
# 对参数 n 进行寻参,这里的参数范围是根据实际情况定义的
self.n_estimators_options = [100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200]
self.best_n_estimators = 0
self.best_acc = 0
def train(self, mall_id, X, shop_ids, TEST, row_ids):
# 处理标签
lbl = preprocessing.LabelEncoder()
lbl.fit(shop_ids)
y = lbl.transform(shop_ids)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 寻参
for n_estimators_size in self.n_estimators_options:
alg = RandomForestClassifier(n_jobs=-1, n_estimators=n_estimators_size)
alg.fit(X_train, y_train)
predict = alg.predict(X_test)
acc = (y_test == predict).mean()
# 更新最优参数和 acc
if acc >= self.best_acc:
self.best_acc = acc
self.best_n_estimators = n_estimators_size
print('[n_estimators, acc]:', n_estimators_size, acc)
# 用最优参数进行训练
rf = RandomForestClassifier(n_jobs=-1, n_estimators=self.n_estimators)
rf.fit(X, y)
# 预测标签
predict = rf.predict(TEST)
# 预测概率
# predict_prob = rf.predict_prob(TEST)
# 转换为预测标签为真实标签
predict = [lbl.inverse_transform(int(x)) for x in predict]