思路:集成学习概念,个体学习器概念,boosting bagging,结合策略(平均法,投票法,学习法),随机森林思想,随机森林的推广,优缺点,sklearn参数,应用场景。
第一部分:前奏
1,集成学习:bagging、boosting;结合策略(平均法,投票法,学习法等)
对于训练集数据,通过训练若干个个体学习器,通过一定的结合策略,就可以最终形成一个强学习器,以达到博采众长的目的。

1),bagging,boosting
Bagging即套袋法,其算法过程如下:
1、从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
2、每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
3、对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)。
Boosting:
AdaBoosting方式每次使用的是全部的样本,每轮训练改变样本的权重。下一轮训练的目标是找到一个函数f 来拟合上一轮的残差。当残差足够小或者达到设置的最大迭代次数则停止。Boosting会减小在上一轮训练正确的样本的权重,增大错误样本的权重。(对的残差小,错的残差大)
梯度提升的Boosting方式是使用代价函数对上一轮训练出的模型函数f的偏导来拟合残差。
Bagging和Boosting的区别:
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
2),结合策略
优点:
1.提高泛化性能
2.降低进入局部最小点的风险
3.扩大假设空间
平均法:简单平均、加权平均
适用范围:
规模大的集成,学习的权重较多,加权平均法易导致过拟合 ;
个体学习器性能相差较大时宜使用加权平均法,相近用简单平均法。
投票法:
1.绝对多数投票法:某标记超过半数;
2.相对多数投票法:预测为得票最多的标记,若同时有多个标记的票最高,则从中随机选取一个。
3.加权投票法:提供了预测结果,与加权平均法类似。
学习法
Stacking描述:先从初始数据集中训练出初级学习器,然后“生成”一个新数据集用于训练次级学习器。在新数据集中,初级学习器的输出被当做样例输入特征,初始样本的标记仍被当做样例
2,决策树:信息熵,剪枝
特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法)。
决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止声场。
剪枝:决策树容易过拟合,需要剪枝来缩小树的结构和规模(包括预剪枝和后剪枝)。
信息熵:
单调性,发生概率越高的事件,其携带的信息量越低;
非负性,信息熵可以看作为一种广度量,非负性是一种合理的必然;
累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和,这也是广度量的一种体现。
香农从数学上严格证明了满足上述三个条件的随机变量不确定性度量函数具有唯一形式:
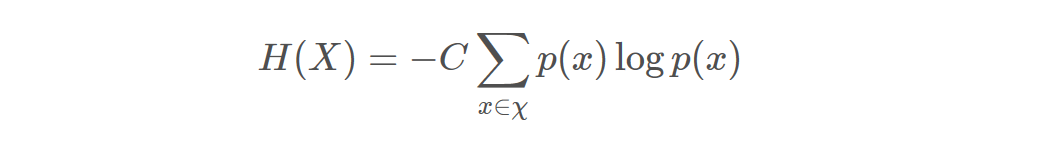
第二部分:随机森林
1,随机森林原理及应用场景:
树模型和线性模型有什么区别呢?其中最重要的是,树形模型是一个一个特征进行处理,之前线性模型是所有特征给予权重相加得到一个新的值。决策树与逻辑回归的分类区别也在于此,逻辑回归是将所有特征变换为概率后,通过大于某一概率阈值的划分为一类,小于某一概率阈值的为另一类;而决策树是对每一个特征做一个划分。另外逻辑回归只能找到线性分割(输入特征x与logit之间是线性的,除非对x进行多维映射),而决策树可以找到非线性分割。
而树形模型更加接近人的思维方式,可以产生可视化的分类规则,产生的模型具有可解释性(可以抽取规则)。树模型拟合出来的函数其实是分区间的阶梯函数。
2,优缺点
尽管有剪枝等等方法,一棵树的生成肯定还是不如多棵树,因此就有了随机森林,解决决策树泛化能力弱的缺点。(可以理解成三个臭皮匠顶过诸葛亮)
而同一批数据,用同样的算法只能产生一棵树,这时Bagging策略可以帮助我们产生不同的数据集。Bagging策略来源于bootstrap aggregation:从样本集(假设样本集N个数据点)中重采样选出Nb个样本(有放回的采样,样本数据点个数仍然不变为N),在所有样本上,对这n个样本建立分类器(ID3\C4.5\CART\SVM\LOGISTIC),重复以上两步m次,获得m个分类器,最后根据这m个分类器的投票结果,决定数据属于哪一类。
随机森林在bagging的基础上更进一步:
-
样本的随机:从样本集中用Bootstrap随机选取n个样本
-
特征的随机:从所有属性中随机选取K个属性,选择最佳分割属性作为节点建立CART决策树(泛化的理解,这里面也可以是其他类型的分类器,比如SVM、Logistics)
-
重复以上两步m次,即建立了m棵CART决策树
-
这m个CART形成随机森林,通过投票表决结果,决定数据属于哪一类(投票机制有一票否决制、少数服从多数、加权多数)
3,随机森林的拓展
第三部分:GBDT
1,提升算法
提升(Boosting)是集成学习方法里的一个重要方法,其主要思想是将弱分类器组装成一个强分类器。在
PAC(概率近似正确)学习框架下,则一定可以将弱分类器组装成一个强分类器。
提升树模型实际采用加法模型(即基函数的线性组合)与前向分步算法,以决策树为基函数的提升方法称为提升树(Boosting
Tree)。
2,GBDT思想及应用场景
GBDT的思想可以用一个通俗的例子解释,假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。
3,Adboost及应用场景
可用于回归,也可用于二分类及多分类问题。
第四部分:随机森林的代码实现

相关模型实现:决策树,GBDT,Adboost