导入依赖包
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split准备数据
# 鸢尾花数据共 150 组
# 取 120 组数据用作训练
# 另外 30 组数据用于测试
iris = load_iris()
train_x, test_x, train_y, test_y = train_test_split(iris.data, iris.target, test_size=0.2)训练模型
# 训练随机森林分类器
clf = RandomForestClassifier(n_estimators=10)
clf = clf.fit(train_x, train_y)校验模型
# 测试训练效果
res = clf.predict(test_x)
plt.rcParams['font.sans-serif']=['SimHei']
plt.title('训练效果校验')
plt.xlabel('校验数据集索引')
plt.ylabel('分类')
plt.plot(range(30), test_y, label='标准结果')
plt.plot(range(30), res, label='测试结果')
plt.legend('best')
plt.grid()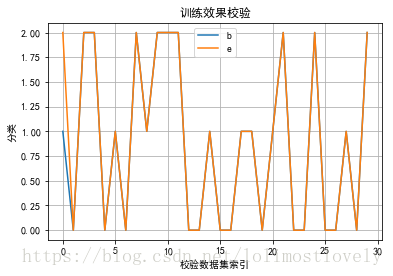
(b 表示标准结果, e 表示预测结果)