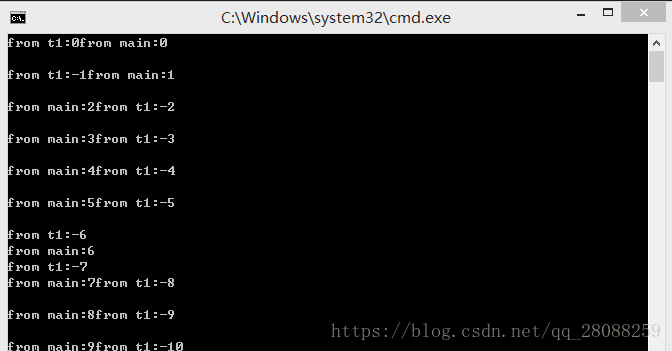
数据竞争和互斥
输出的结果毫无规律,因为有两个线程在运行,t1进程和主进程都在为同一个资源cout进行竞争。
#include <iostream>
#include <string>
#include <thread>
using namespace std;
void function_1(){
for (int i = 0; i > -100; i--)
cout << "from t1:" << i << endl;
}
int main(){
thread t1(function_1);
for (int i = 0; i <100; i++)
cout << "from main:" << i << endl;
t1.join(); //该行代码确保t1执行完成
return 0;
}
需要同步资源 ,这里是cout。采用了mutex互斥对象 lock() unlock()函数后,输出就非常有序了。
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
using namespace std;
//创建互斥对象
mutex mu;
//创建函数
void shared_print(string msg, int id){
mu.lock(); //加一把锁,当一个线程在打印时,另一个线程会等待
cout << msg << id << endl;
mu.unlock(); //再打印完之后,需要解锁
//cout资源通过互斥对象mu实现了同步,两个线程同时使用cout的现象不会发生
}
void function_1(){
for (int i = 0; i > -100; i--)
shared_print( "from t1:" ,i);
}
int main(){
thread t1(function_1);
for (int i = 0; i <100; i++)
shared_print( "from main:" ,i );
t1.join(); //该行代码确保t1执行完成
return 0;
}
上述代码存在问题:若
void shared_print(string msg, int id){
mu.lock(); //加一把锁,当一个线程在打印时,另一个线程会等待
cout << msg << id << endl;
mu.unlock(); //再打印完之后,需要解锁
//cout资源通过互斥对象mu实现了同步,两个线程同时使用cout的现象不会发生
}中的
cout << msg << id << endl;这行代码抛出异常怎么办,这样的话mu将会被永远地锁住。因此,不推荐lock unlock
可用lock_guard<mutex> guard(mu);
完全保护COUT对象,采用下法:另外,这种方式将输出f和mutex完全绑定了!!
这样的话,资源f就完全在互斥对象mutex的保护之下了,没有任何线程可以在不使用LofFile类的情况下访问资源f,注意不能破坏f的保护等级,不能输出f,后者不能将f作为函数的参数传递出去。
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
#include <fstream> //文件流
using namespace std;
//创建类
class LofFile{
private:
mutex m_mutex; //互斥对象
ofstream f; //输出文件流
public:
LofFile(){ //构造函数
f.open("log.txt");
}
void shared_print(string id, int value){
lock_guard<mutex> locker(m_mutex);
f << "from" << id << ":" << value << endl;
}
};
void function_1(LofFile& log){ //实参为引用
for (int i = 0; i > -100; i--)
log.shared_print( "from t1:" ,i);
}
int main(){
LofFile log; //声明对象
thread t1(function_1,ref(log)); //传入引用,注意是ref() 比如thread的方法传递引用的时候,必须外层用ref来进行引用传递,否则就是浅拷贝。
for (int i = 0; i <100; i++)
log.shared_print( "from main:" ,i );
t1.join(); //该行代码确保t1执行完成
return 0;
}
死锁
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
#include <fstream> //文件流
using namespace std;
//创建类
class LofFile{
private:
mutex m_mutex; //互斥对象
mutex m_mutex2; //互斥对象2
ofstream f; //输出文件流
public:
LofFile(){ //构造函数
f.open("log.txt");
}
void shared_print(string id, int value){
lock_guard<mutex> locker(m_mutex);
lock_guard<mutex> locker2(m_mutex2);
cout << "from" << id << ":" << value << endl;
}
void shared_print2(string id, int value){
lock_guard<mutex> locker2(m_mutex2); //第二个shared_print函数,互换m_mutex的位置
lock_guard<mutex> locker(m_mutex);
cout << "from" << id << ":" << value << endl;
}
};
void function_1(LofFile& log){ //实参为引用
for (int i = 0; i > -100; i--)
log.shared_print( "from t1:" ,i); //这里子线程调用shared_print函数
}
int main(){
LofFile log; //声明对象
thread t1(function_1,ref(log)); //传入引用,注意是ref() 比如thread的方法传递引用的时候,必须外层用ref来进行引用传递,否则就是浅拷贝。
for (int i = 0; i <100; i++)
log.shared_print2( "from main:" ,i ); //这里主线程调用shared_print2函数
t1.join(); //该行代码确保t1执行完成
return 0;
}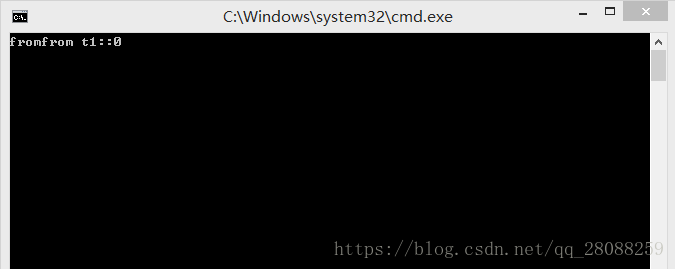
出现了死锁的现象,原因在于:
主线程锁住了m_mutex2 等待子线程释放m_mutex
子线程锁住了m_mutex 等待主线程释放m_mutex2
这样就形成了死锁,两个线程均无法往下走了。
避免死锁,解决如下:
1.确保locker顺序相同
2.lock(m_mutex, m_mutex); adopt
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
#include <fstream> //文件流
using namespace std;
//创建类
class LofFile{
private:
mutex m_mutex; //互斥对象
mutex m_mutex2; //互斥对象2
ofstream f; //输出文件流
public:
LofFile(){ //构造函数
f.open("log.txt");
}
void shared_print(string id, int value){
lock(m_mutex, m_mutex2);
lock_guard<mutex> locker(m_mutex, adopt_lock);
lock_guard<mutex> locker2(m_mutex2,adopt_lock);
cout << "from" << id << ":" << value << endl;
}
void shared_print2(string id, int value){
lock(m_mutex, m_mutex2);
lock_guard<mutex> locker2(m_mutex2, adopt_lock); //第二个shared_print函数,互换m_mutex的位置
lock_guard<mutex> locker(m_mutex, adopt_lock);
cout << "from" << id << ":" << value << endl;
}
};
void function_1(LofFile& log){ //实参为引用
for (int i = 0; i > -100; i--)
log.shared_print( "from t1:" ,i); //这里子线程调用shared_print函数
}
int main(){
LofFile log; //声明对象
thread t1(function_1,ref(log)); //传入引用,注意是ref() 比如thread的方法传递引用的时候,必须外层用ref来进行引用传递,否则就是浅拷贝。
for (int i = 0; i <100; i++)
log.shared_print2( "from main:" ,i ); //这里主线程调用shared_print2函数
t1.join(); //该行代码确保t1执行完成
return 0;
}
unique_lock lazy initialization
unique_lock 与 lock_guard相比,提供更多的弹性。
unique_lock 与 lock_guard都不可以被复制,且lock_guard不能被移动,而unique_lock 可以被移动。
unique_lock所提供的弹性并消耗计算机性能。
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
#include <fstream> //文件流
using namespace std;
//创建类
class LofFile{
private:
mutex m_mutex; //互斥对象
once_flag m_flag; //lazy initialization
ofstream f; //输出文件流
public:
LofFile(){ //构造函数
//f.open("log.txt");
}
void shared_print(string id, int value){
//lazy initialization
call_once(m_flag, [&](){f.open("log.txt"); }); //不需要每一次构建LofFile都打开文件,只有在调用shared_print函数时打开lambda,
lock_guard<mutex> locker(m_mutex); //lambda函数只被一个线程调用一次
f << "from" << id << ":" << value << endl;
}
};
void function_1(LofFile& log){ //实参为引用
for (int i = 0; i > -100; i--)
log.shared_print( "from t1:" ,i); //这里子线程调用shared_print函数
}
int main(){
LofFile log; //声明对象
thread t1(function_1,ref(log)); //传入引用,注意是ref() 比如thread的方法传递引用的时候,必须外层用ref来进行引用传递,否则就是浅拷贝。
for (int i = 0; i <100; i++)
log.shared_print( "from main:" ,i ); //这里主线程调用shared_print2函数
t1.join(); //该行代码确保t1执行完成
return 0;
}结果没问题
条件变量
前面的内容是如何在线程之间使用互斥对象去同步访问普通资源。
同步:也就是必须一件一件事做,等前一件做完了才能做下一件事。就想起床要先刷牙、后吃饭,不能同时做
#include <iostream>
#include <thread>
#include <string>
#include <mutex>
#include <fstream> //文件流
#include <deque> //队列
#include <functional> //定义了C++标准中多个用于表示函数对象(function object)的类模板
#include <condition_variable> //条件变量头文件
using namespace std;
deque<int> q; //全局变量,整型队列
mutex mu; //互斥对象 关于q的访问要同步
condition_variable cond; //全局条件变量
void function_1(){ //数据的创造者
int count = 10;
while (count > 0){
unique_lock<mutex> locker(mu); //这里使用的是unique_lock
q.push_front(count);
locker.unlock();
cond.notify_one(); //通知
this_thread::sleep_for(chrono::seconds(1)); //休眠1秒钟
count--;
}
}
//void function_2(){ //数据的使用者 无限循环 消耗计算资源 如何解决呢? 看下面
// int data = 0;
// while (data != 1){
// unique_lock<mutex> locker(mu);
// if (!q.empty()){
// data = q.back();
// q.pop_back();
// locker.unlock();
// cout << "t2 got a value from t1:" << data << endl;
// }
// else{
// locker.unlock();
// }
// }
//}
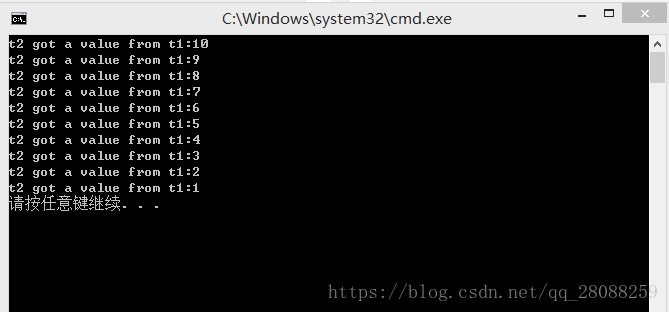
void function_2(){ //使用条件变量
int data = 0;
while (data != 1){
unique_lock<mutex> locker(mu);
cond.wait(locker, [](){return !q.empty(); }); //唤醒 需要传入locker 会自动加解锁
//wait第二个参数为了防止伪激活 ,加入lambda
data = q.back();
q.pop_back();
locker.unlock();
cout << "t2 got a value from t1:" << data << endl;
}
}
int main(){
thread t1(function_1);
thread t2(function_2);
t1.join();
t2.join();
return 0;
}
Future, Promise和async()
线程间的通信
1.主线程从子线程中获取变量
#include <iostream>
#include <thread>
#include <future>
using namespace std;
//阶乘函数
int factorial(int N){
int res = 1;
for (int i = N; i > 1; i--)
res *= i;
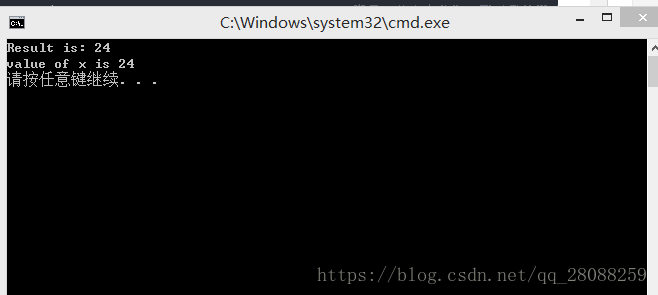
cout << "Result is: " << res << endl;
return res;
}
//主线程从子线程中获取变量,主线程要等子线程计算出结果的值后再给主线程
int main(){
//thread t1(factorial, 4);
//t1.join();
int x;
future<int> fu = async(launch::deferred | launch::async,factorial, 4); //future变量,从未来获取,可以另外开辟一个线程async,也可以不用deferred
x = fu.get();
cout << "value of x is " << x << endl;
return 0;
}
1.子线程从主线程中获取变量
是
#include <iostream>
#include <thread>
#include <future>
using namespace std;
//阶乘函数
int factorial(future<int>& f){
int res = 1;
int N = f.get();
for (int i = N; i > 1; i--)
res *= i;
cout << "Result is: " << res << endl;
return res;
}
//子线程从主线程中获取变量
int main(){
int x;
promise<int> p; //承诺了就必须set_value()
future<int> f = p.get_future();
future<int> fu = async(launch::deferred | launch::async,factorial, ref(f)); //ref(f)是指f的引用
p.set_value(4); //主线程变量的值设定
x = fu.get();
cout << "value of x is " << x << endl;
return 0;
}
注意:
promise future 都是模板 只能move 不能复制 还有shared_future可以创建多个!!!!!