一,引子
编程范式
编程是程序员用特定的语法+数据结构+算法组成的代码来告诉计算机如何执行任务的过程 , 一个程序是程序员为了得到一个任务结果而编写的一组指令的集合,正所谓条条大路通罗马,实现一个任务的方式有很多种不同的方式, 对这些不同的编程方式的特点进行归纳总结得出来的编程方式类别,即为编程范式。
不同的编程范式本质上代表对各种类型的任务采取的不同的解决问题的思路, 大多数语言只支持一种编程范式,当然也有些语言可以同时支持多种编程范式。 两种最重要的编程范式分别是面向过程编程和面向对象编程。还有一种为函数式编程本文不做介绍。
1,面向过程编程(Procedural Programming)
Procedural programming uses a list of instructions to tell the computer what to do step-by-step.
面向过程又被称为top-down languages, 就是程序从上到下一步步执行,一步步从上到下,从头到尾的解决问题 。基本设计思路就是程序一开始是要着手解决一个大的问题,然后把一个大问题分解成很多个小问题或子过程,这些子过程再执行的过程再继续分解直到小问题足够简单到可以在一个小步骤范围内解决。
过程化编程的步骤是:
首先,我们必须将待解问题的解决方案抽象为一系列概念化的步骤。然后通过编程的方式将这些步骤转化为程序指令集(算法),而这些指令按照一定的顺序排列,用来说明如何执行一个任务或解决一个问题。这就意味着,程序员必须要知道程序要完成什么,并且告诉计算机如何来进行所需的计算工作,包括每个细节操作。简言之,就是将计算机看作一个善始善终服从命令的装置。
过程化语言特别适合解决线性(或者说按部就班)的算法问题,趋向于开发运行较快且对系统资源利用率较高的程序。过程化语言非常的灵活并强大,同时有许多经典应用范例,这使得程序员可以用它来解决多种问题。
过程化语言的不足之处就是它不适合某些种类问题的解决,例如那些非结构化的具有复杂算法的问题。问题出现在,过程化语言必须对一个算法加以详尽的说明,并且其中还要包括执行这些指令或语句的顺序。实际上,给那些非结构化的具有复杂算法的问题给出详尽的算法是极其困难的。
广泛引起争议和讨论的地方是:无条件分支,或goto语句,它是大多数过程式编程语言的组成部分,反对者声称:goto语句可能被无限地滥用;它给程序设计提供了制造混 乱的机会。目前达成的共识是将它保留在大多数语言中,对于它所具有的危险性,应该通过程序设计的规定将其最小化。 2,事件驱动编程
其实,基于事件驱动的程序设计在图形用户界面(GUI)出现很久前就已经被应用于程序设计中,可是只有当图形用户界面广泛流行时,它才逐渐形演变为一种广泛使用的程序设计模式。
在过程式的程序设计中,代码本身就给出了程序执行的顺序,尽管执行顺序可能会受到程序输入数据的影响。
在事件驱动的程序设计中,程序中的许多部分可能在完全不可预料的时刻被执行。往往这些程序的执行是由用户与正在执行的程序的互动激发所致。
- 事件。就是通知某个特定的事情已经发生(事件发生具有随机性)。
- 事件与轮询。轮询的行为是不断地观察和判断,是一种无休止的行为方式。而事件是静静地等待事情的发生。事实上,在Windows出现之前,采用鼠标输入字符模式的PC应用程序必须进行串行轮询,并以这种方式来查询和响应不同的用户操做。
- 事件处理器。是对事件做出响应时所执行的一段程序代码。事件处理器使得程序能够对于用户的行为做出反映。
事件驱动常常用于用户与程序的交互,通过图形用户接口(鼠标、键盘、触摸板)进行交互式的互动。当然,也可以用于异常的处理和响应用户自定义的事件等等。
事件的异常处理比用户交互更复杂。
事件驱动不仅仅局限在GUI编程应用。但是实现事件驱动我们还需要考虑更多的实际问题,如:事件定义、事件触发、事件转化、事件合并、事件排队、事件分派、事件处理、事 件连带等等。
其实,到目前为止,我们还没有找到有关纯事件驱动编程的语言和类似的开发环境。所有关于事件驱动的资料都是基于GUI事件的。
属于事件驱动的编程语言有:VB、C#、Java(Java Swing的GUI)等。它们所涉及的事件绝大多数都是GUI事件。
| 3,面向过程与面向对象的对比 |
面向过程的程序设计的核心是过程(流水线式思维),过程即解决问题的步骤,面向过程的设计就好比精心设计好一条流水线,考虑周全什么时候处理什么东西。
优点是:极大的降低了程序的复杂度
缺点是:一套流水线或者流程就是用来解决一个问题,生产汽水的流水线无法生产汽车,即便是能,也得是大改,改一个组件,牵一发而动全身。
应用场景:一旦完成基本很少改变的场景,著名的例子有Linux內核,git,以及Apache HTTP Server等。
面向对象的程序设计的核心是对象(上帝式思维),要理解对象为何物,必须把自己当成上帝,上帝眼里世间存在的万物皆为对象,不存在的也可以创造出来。对象是特征和技能的结合,其中特征和技能分别对应对象的数据属性和方法属性。
优点是:解决了程序的扩展性。对某一个对象单独修改,会立刻反映到整个体系中,如对游戏中一个人物参数的特征和技能修改都很容易。
缺点:可控性差,无法向面向过程的程序设计流水线式的可以很精准的预测问题的处理流程与结果,面向对象的程序一旦开始就由对象之间的交互解决问题,即便是上帝也无法预测最终结果。于是我们经常看到一个游戏人某一参数的修改极有可能导致阴霸的技能出现,一刀砍死3个人,这个游戏就失去平衡。
应用场景:需求经常变化的软件,一般需求的变化都集中在用户层,互联网应用,企业内部软件,游戏等都是面向对象的程序设计大显身手的好地方。
二,面向对象编程(Object-Oriented Programming )
OOP编程是利用“类”和“对象”来创建各种模型来实现对真实世界的描述,使用面向对象编程的原因一方面是因为它可以使程序的维护和扩展变得更简单,并且可以大大提高程序开发效率 ,另外,基于面向对象的程序可以使它人更加容易理解你的代码逻辑,从而使团队开发变得更从容。
1,类和对象基本概念
1,Class 类
类即是对一类拥有相同静态属性和动态可执行的操作方法的概念,在类中定义了其共同具备的属性(variables(data))、共同的方法
2,Object 对象
一个对象即是一个类的实例化后实例个体,一个类必须经过实例化后方可在程序中调用,一个类可以实例化多个对象,每个对象亦可以有不同的属性,就像人类是指所有人,每个人是指具体的对象,人与人之前有共性,亦有不同
3>对象是特征与技能的结合体,其中特征和技能分别对应对象的数据属性和方法属性
4>对象(实例)本身只有数据属性,但是python的class机制会将类的函数绑定到对象上,称为对象的方法,或者叫绑定方法,绑定方法唯一绑定一个对象,同一个类的方法绑定到不同的对象上,属于不同的方法,内存地址都不会一样
在类内部定义的属性属于类本身的,由操作系统只分配一块内存空间,大家公用这一块内存空间
5>创建一个类就会创建一个类的名称空间,用来存储类中定义的所有名字,这些名字称为类的属性:而类中有两种属性:数据属性和函数属性,其中类的数据属性是共享给所有对象的,而类的函数属性是绑定到所有对象的。
6>创建一个对象(实例)就会创建一个对象(实例)的名称空间,存放对象(实例)的名字,称为对象(实例)的属性
7>在obj.name会先从obj自己的名称空间里找name,找不到则去类中找,类也找不到就找父类…最后都找不到就抛出异常。
8>类的相关方法:
类的相关方法(定义一个类,也会产生自己的名称空间)
类名.__name__ # 类的名字(字符串)
类名.__doc__ # 类的文档字符串
类名.__base__ # 类的第一个父类(在讲继承时会讲)
类名.__bases__ # 类所有父类构成的元组(在讲继承时会讲)
类名.__dict__ # 类的字典属性、名称空间
类名.__module__ # 类定义所在的模块
类名.__class__ # 实例对应的类(仅新式类中)9>其余概念:
1.创建出类会产生名称空间,实例化对象也会产生名称空间。
2.用户自己定义的一个类,实际上就是定义了一个类型,类型与类是统一的。
3.用户先是从自己的命名空间找,如果找不大,在从类的命名空间找。
student1.langage = "1111"
print(student1.__dict__) ===>先是从自己的命名空间找
print(Student.__dict__) ===>然后在从类的命名空间找
4.通过类来访问,访问的是函数,通过对象来访问,访问的是方法,在类内部定义的方式实际上是绑定到对象的身上来用的。
<function Student.fun at 0x000000000267DAE8>
<bound method Student.fun of <__main__.Student object at 0x0000000002684128>>
<function Student.fun at 0x00000000025CDAE8>
<bound method Student.fun of <__main__.Student object at 0x00000000025D4160>>
<bound method Student.fun of <__main__.Student object at 0x00000000025D4198>>
5.总结:类的数据属性是大家共有的,而且大家的内部地址是一样的,用的就是一个
类的函数属性是绑定到大家身上的,内部地址不一样,绑定方法指的是绑定到对象身上。
绑定方法:绑定到谁的身上,就是给谁用的,谁来调用就会自动把自己当做第一个参数传入。
**定义在类内部的变量,是所有对象共有的,id全一样,
**定义在类内部的函数,是绑定到所有对象的,是给对象来用的,obj.fun()会把obj本身当做
一个参数来传递。
6.在类内部定义的函数虽然可以由类来调用,但是并不是为了给类用的,在类内部定义的函数的目的就是为了绑定到对象身上的。
7.在类的内部来说,__init__是类的函数属性,但是对于对象来说,就是绑定方法。
8.命名空间的问题:先从对象的命名空间找,随后在从类的命名空间找,随后在从父类的命名
空间找。
print(student1.x)
9.在定义类的时候,可以想到什么先写什么。
| 2,初始化构造函数__init__的作用 |
所谓初始化构造函数就是在构造对象的同时被对象自动调用,完成对事物的初始化,一个类只要生成一个类对象,它一定会调用初始化构造函数.
特点:
1>一个类中只能有一个初始化构造函数
2>不能有返回值
3>可以用它来为每个实例定制自己的特征
示例程序:
class Student():
def __init__(self,name,age):
self.name = name
self.age = age
print(self.name,self.age)
if __name__ == '__main__':
#在构造对象的时候会自动调用初始化构造函数
student = Student("Alex",100)运行结果:
Alex 100
Process finished with exit code 0| 3、self关键字的用法 |
为了辨别此时此刻正在处理哪个对象,self指针变量指向当前时刻正在处理的对象,即构造出来的对象
在构造方法中self代表的是:self指针变量指向当前时刻正在创建的对象
构造函数中self.name = name 的含义:将局部变量name的数值发送给当前时刻正在创建的对象中的name成员
示例程序:
class Student():
def __init__(self):
print("当前对象的地址是:%s"%self)
if __name__ == '__main__':
student1 = Student()
student2 = Student()运行结果:
class Student():
def __init__(self):
print("当前对象的地址是:%s"%self)
if __name__ == '__main__':
student1 = Student()
print(student1)
student2 = Student()
print(student2)运行结果:
当前对象的地址是:<__main__.Student object at 0x00000000025ACF28>
<__main__.Student object at 0x00000000025ACF28>
当前对象的地址是:<__main__.Student object at 0x00000000025D4048>
<__main__.Student object at 0x00000000025D4048>
Process finished with exit code 0在上面的程序中,student1、student2、self实际上都是指针变量,存放的是地址,指定当前时刻正在调用的那个对象。
4,面向对象的三大 特性4.1Encapsulation 封装
在类中对数据的赋值、内部调用对外部用户是透明的,这使类变成了一个胶囊或容器,里面包含着类的数据和方法。也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
析构函数: 在实例释放、销毁的时候自动执行的,通常用于做一些收尾工作, 如关闭一些数据库连接,关闭打开的临时文件
1、在面向对象中,所有的类通常情况下很少让外部类直接访问类内部的属性和方法,而是向外部类提供一些按钮,对其内部的成员进行访问,以保证程序的安全性,这就是封装
2、在python中用双下划线的方式实现隐藏属性,即实现封装
3、访问控制符的用法___包括两种:在类的内部与在类的外部
1>在一个类的内部,所有的成员之间彼此之间都可以进行相互访问,访问控制符__是透明的,失效的
2>在一个类的外部,通过_类名_对象的方式才可以访问到对象中的_成员
综上:内部之间可以直接访问,在类的外部必须换一种语法方式进行访问
4、在python当中如何实现一个隐藏的效果呢?答案:在Python里面没有真正意义上的隐藏,只能
从语法级别去实现这件事。
5、在子类定义的__x不会覆盖在父类定义的__x,因为子类中变形成了:子类名__x,而父类中变形成了:父类名__x,即双下滑线开头的属性在继承给子类时,子类是无法覆盖的
示例程序1:
class Student:
def __init__(self,name,age):
self.__name = name
self.__age = age
def setter(self,name,age):
if not isinstance(name,str):
raise TypeError("名字必须是字符串类型")
if not isinstance(age,int):
raise TypeError("年龄必须是整数类型")
self.__name = name
self.__age = age
def tell(self):
print("学生的信息是:%s\t%s"%(self.__name,self.__age))
if __name__ == '__main__':
student = Student("Alex",25)
student.tell()
student.setter("Alex_sb",40)
student.tell()运行结果:
学生的信息是:Alex 25
学生的信息是:Alex_sb 40
Process finished with exit code 04.2Inheritance 继承
继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。
通过继承创建的新类称为“子类”或“派生类”。被继承的类称为“基类”、“父类”或“超类”。继承的过程,就是从一般到特殊的过程。
要实现继承,可以通过“继承”(Inheritance)和“组合”(Composition)来实现。
| 继承的概念 |
1、一个类从已有的类那里获得其已有的属性与方法,这种现象叫做类的继承
2、方法重写指在子类中重新定义父类中已有的方法,这中现象叫做方法的重写
3、若A类继承了B类,则aa对象既是A,又是B,继承反映的是一种谁是谁的关系,只有在谁是谁的情况下,才能用继承解决代码冗余的问题。
4、寻找属性和方法的顺序问题:先从对象自己的命名空间中找,然后在自己的类中,最后在从父类当中去找
5、在python3当中,所有的类都是新式,所有的类都直接或者间接的继承了Object
6、在python中,新建的类可以继承一个或多个父类
| 组合的概念 |
1、一个类的属性可以是一个类对象,通常情况下在一个类里面很少定义一个对象就是它本身,实际意义很少
2、将另外一个对象作为自己的属性成员(自己的一个属性来自于另外一个对象),这就是组合
3、组合也可以解决代码冗余的问题,但是组合反应的是一种什么是什么的关系。
示例代码1:
class Date:
def __init__(self,year,month,day):
self.year = year
self.month = month
self.day = day
def tell(self):
print("%s--%s--%s"%(self.year,self.month,self.day))
class People:
def __init__(self,name,age):
self.name = name
self.age = age
class Student(People):
def __init__(self,name,age,sex,year,month,day):
People.__init__(self,name,age)
self.sex = sex
#下面这一步骤就是组合
self.birth = Date(year,month,day)
if __name__ == '__main__':
student = Student("alex",25,"man",2015,12,31)
print("student的birth成员指向了一个Date对象!")
print("%s"%student.birth)
student.birth.tell()- 运行结果:
student的birth成员指向了一个Date对象!
<__main__.Date object at 0x0000000002604358>
2015--12--31
Process finished with exit code 0在某些 OOP 语言中,一个子类可以继承多个基类Python。但是一般情况下,一个子类只能有一个基类Java,C#,要实现多重继承,可以通过多级继承来实现。
| 多继承的概念 |
py2 经典类是按深度优先来继承的,新式类是按广度优先来继承的 py3 经典类和新式类都是统一按广度优先来继承的
新式类,推荐写法
class D(object): def bar(self): print 'D.bar' class C(D): def bar(self): print 'C.bar' class B(D): def bar(self): print 'B.bar' class A(B, C): def bar(self): print 'A.bar' a = A() # 执行bar方法时 # 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中没有,则继续去C类中找,如果C类中没有,则继续去D类中找,如果还是未找到,则报错 # 所以,查找顺序:A --> B --> C --> D # 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了 a.bar()
如果是经典类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错
新式类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错
注意:在上述查找过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
| 属性与方法的遍历问题(MRO列表) |
python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表,例如下面例子中:
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1.子类会先于父类被检查
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,选择第一个父类
示例程序:
class A(object):
def fun(self):
print("aaaa")
class B(A):
def fun(self):
print("bbbb")
class C:
def fun(self):
print("cccc")
class D(C):
def fun(self):
print("dddd")
class F(B,D):
def fun(self):
print("ffff")
if __name__ == '__main__':
print(F.mro())
#F==>B==>A==>D==>C===>Object
ff = F()
ff.fun()运行结果:
[<class '__main__.F'>, <class '__main__.B'>, <class '__main__.A'>, <class '__main__.D'>, <class '__main__.C'>, <class 'object'>]
ffff
Process finished with exit code 0| super关键字的使用 |
1、super关键字产生的原因:在子类当中可以通过使用super关键字来调用父类的中相应的方法,简化代码。
2、使用super调用的所有属性,都是从MRO列表当前的位置往后找,千万不要通过看代码去找继承关系,一定要看MRO列表。
示例代码:
class Foo:
def test(self):
print("from foo")
class Bar(Foo):
def test(self):
#Foo.test(self)
super().test()
print("bar")
if __name__ == '__main__':
bb = Bar()
bb.test()运行结果:
from foo
bar
Process finished with exit code 0|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
class
SchoolMember(
object
):#新式类
members
=
0
#初始学校人数为0
def
__init__(
self
,name,age):
self
.name
=
name
self
.age
=
age
def
tell(
self
):
pass
def
enroll(
self
):
'''注册'''
SchoolMember.members
+
=
1
print
(
"\033[32;1mnew member [%s] is enrolled,now there are [%s] members.\033[0m "
%
(
self
.name,SchoolMember.members))
def
__del__(
self
):
'''析构方法'''
print
(
"\033[31;1mmember [%s] is dead!\033[0m"
%
self
.name)
class ExecuteMember(object):#行政人员,介绍多继承
def Manage(self,obj):
class
Teacher(SchoolMember):
def
__init__(
self
,name,age,course,salary):
#SchoolMember.__init__(self,name,age) #与下一行同意义,但下一行更高效,减少耦合
super
(Teacher,
self
).__init__(name,age)
self
.course
=
course
self
.salary
=
salary
self
.enroll()
def
teaching(
self
):
'''讲课方法'''
print
(
"Teacher [%s] is teaching [%s] for class [%s]"
%
(
self
.name,
self
.course,
's12'
))
def
tell(
self
):
'''自我介绍方法'''
msg
=
'''Hi, my name is [%s], works for [%s] as a [%s] teacher !'''
%
(
self
.name,'Oldboy',
self
.course)
print
(msg)
class
Student(SchoolMember):
def
__init__(
self
, name,age,grade,sid):
super
(Student,
self
).__init__(name,age)
self
.grade
=
grade
self
.sid
=
sid
self
.enroll()
def
tell(
self
):
'''自我介绍方法'''
msg
=
'''Hi, my name is [%s], I'm studying [%s] in [%s]!'''
%
(
self
.name,
self
.grade,'Oldboy')
print
(msg)
#多继承
class StudentUnit(SchoolMember,ExecuteMember)
if
__name__
=
=
'__main__'
:
t1
=
Teacher(
"Alex"
,
22
,
'Python'
,
20000
)
t2
=
Teacher(
"TengLan"
,
29
,
'Linux'
,
3000
)
s1
=
Student(
"Qinghua"
,
24
,
"Python S12"
,
1483
)
s2
=
Student(
"SanJiang"
,
26
,
"Python S12"
,
1484
)
t1.teaching()
t2.teaching()
t1.tell()
#实例学生会管理已经实例化出来的学生s1
su1 = StudentUnit("xueshenghuizhuxi",22,s1)
su1.Mange(s1)
|
4.3polymorphic 多态
多态是面向对象的重要特性,简单点说:“一个接口,多种实现”,指一个基类中派生出了不同的子类,且每个子类在继承了同样的方法名的同时又对父类的方法做了不同的实现,这就是同一种事物表现出的多种形态。
1、所谓多态指的是一个父类的引用既可以指向父类的对象,也可以指向子类的对象,它可以根据当前时刻指向的不同,自动调用不同对象的方法,这就是多态的概念。(当然,Python中的多态没必要理解的这么复杂,因为Python自带多态的性能)
2、多态性依赖于同一种事物的不同种形态
3、Python是一门弱类型的语言,所谓弱类型语言指的是对参数没有类型限制,而这是我们可以随意传入对象的根本原因
多态允许将子类的对象当作父类的对象使用,某父类型的引用指向其子类型的对象,调用的方法是该子类型的方法。这里引用和调用方法的代码编译前就已经决定了,而引用所指向的对象可以在运行期间动态绑定
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class
Animal(
object
):
def
__init__(
self
, name):
# Constructor of the class
self
.name
=
name
def
talk(
self
):
# Abstract method, defined by convention only
raise
NotImplementedError(
"Subclass must implement abstract method"
)
class
Cat(Animal):
def
talk(
self
):
print
(
'%s: 喵喵喵!'
%
self
.name)
class
Dog(Animal):
def
talk(
self
):
print
(
'%s: 汪!汪!汪!'
%
self
.name)
def
func(obj):
#一个接口,多种形态
obj.talk()
c1
=
Cat(
'小晴'
)
d1
=
Dog(
'李磊'
)
func(c1)
func(d1)
|
|
1
2
3
4
5
6
|
class
Dog(
object
):
print
(
"hello,I am a dog!"
)
d
=
Dog()
#实例化这个类,
#此时的d就是类Dog的实例化对象
#实例化,其实就是以Dog类为模版,在内存里开辟一块空间,存上数据,赋值成一个变量名
|
上面的代码其实有问题,想给狗起名字传不进去。
|
1
2
3
4
5
6
7
8
9
|
class
Dog(
object
):
def
__init__(
self
,name,dog_type):
self
.name
=
name
self
.
type
=
dog_type
def
sayhi(
self
):
print
(
"hello,I am a dog, my name is "
,
self
.name)
d
=
Dog(
'LiChuang'
,
"京巴"
)
d.sayhi()
|
为什么有__init__? 为什么有self? 先注释掉这两句
|
1
2
3
|
# d = Dog('LiChuang', "京巴")
# d.sayhi()
print
(Dog)
|
没实例直接打印Dog输出如下
|
1
|
<
class
'__main__.Dog'
>
|
这代表即使不实例化,这个Dog类本身也是已经存在内存里的,那实例化时,会产生什么化学反应呢?
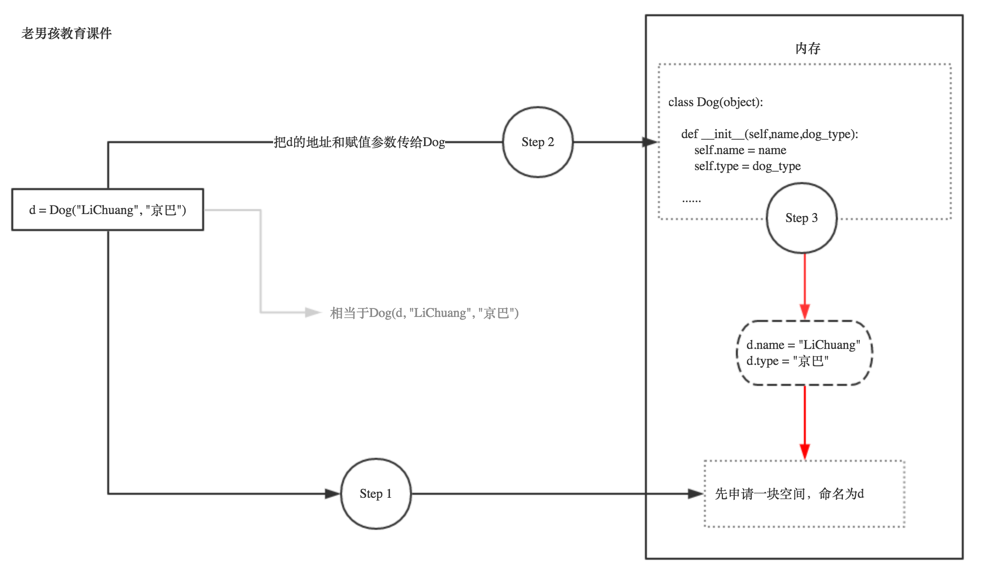
根据上图我们得知,其实self,就是实例本身!你实例化时python会自动把这个实例本身通过self参数传进去。
你说好吧,假装懂了, 但下面这段代码你又不明白了, 为何sayhi(self),要写个self呢?
|
1
2
3
4
|
class
Dog(
object
):
...
def
sayhi(
self
):
print
(
"hello,I am a dog, my name is "
,
self
.name)
|
|
1
2
3
4
5
6
7
|
class
Role(
object
):
#定义一个类, class是定义类的语法,Role是类名,(object)是新式类的写法,必须这样写,以后再讲为什么
def
__init__(
self
,name,role,weapon,life_value
=
100
,money
=
15000
):
#初始化函数,在生成一个角色时要初始化的一些属性就填写在这里
self
.name
=
name
#__init__中的第一个参数self,和这里的self都 是什么意思? 看下面解释
self
.role
=
role
self
.weapon
=
weapon
self
.life_value
=
life_value
self
.money
=
money
|
|
1
2
|
r1
=
Role(
'Alex'
,
'police'
,'AK47’)
#生成一个角色 , 会自动把参数传给Role下面的__init__(...)方法
r2
=
Role(
'Jack'
,
'terrorist'
,'B22’)
#生成一个角色
|
我们看到,上面的创建角色时,我们并没有给__init__传值,程序也没未报错,是因为,类在调用它自己的__init__(…)时自己帮你给self参数赋值了,
|
1
2
|
r1
=
Role(
'Alex'
,
'police'
,
'AK47’) #此时self 相当于 r1 , Role(r1,'
Alex
','
police
','
AK47’)
r2
=
Role(
'Jack'
,
'terrorist'
,
'B22’)#此时self 相当于 r2, Role(r2,'
Jack
','
terrorist
','
B22’)
|
- 在内存中开辟一块空间指向r1这个变量名
- 调用Role这个类并执行其中的__init__(…)方法,相当于Role.__init__(r1,'Alex','police',’AK47’),这么做是为什么呢? 是为了把'Alex','police',’AK47’这3个值跟刚开辟的r1关联起来,是为了把'Alex','police',’AK47’这3个值跟刚开辟的r1关联起来,是为了把'Alex','police',’AK47’这3个值跟刚开辟的r1关联起来,重要的事情说3次, 因为关联起来后,你就可以直接r1.name, r1.weapon 这样来调用啦。所以,为实现这种关联,在调用__init__方法时,就必须把r1这个变量也传进去,否则__init__不知道要把那3个参数跟谁关联呀。
- 所以这个__init__(…)方法里的,self.name = name , self.role = role 等等的意思就是要把这几个值 存到r1的内存空间里。
|
1
2
|
def
buy_gun(
self
,gun_name):
print
(“
%
s has just bought
%
s”
%
(
self
.name,gun_name) )
|
|
1
2
|
r1
=
Role(
'Alex'
,
'police'
,
'AK47'
)
r1.buy_gun(
"B21”) #python 会自动帮你转成 Role.buy_gun(r1,”B21"
)
|
- 上面的这个r1 = Role('Alex','police','AK47’)动作,叫做类的“实例化”, 就是把一个虚拟的抽象的类,通过这个动作,变成了一个具体的对象了, 这个对象就叫做实例
- 刚才定义的这个类体现了面向对象的第一个基本特性,封装,其实就是使用构造方法将内容封装到某个具体对象中,然后通过对象直接或者self间接获取被封装的内容