在Python 面向对象详解中我们主要介绍了类,对象,面向对象三大特性如封装,继承,多态
本文介绍面向对象的一些高级语法特性 类的成员、成员修饰符、类的特殊成员。
一,类的成员
类的成员可以分为三大类:字段、方法和属性
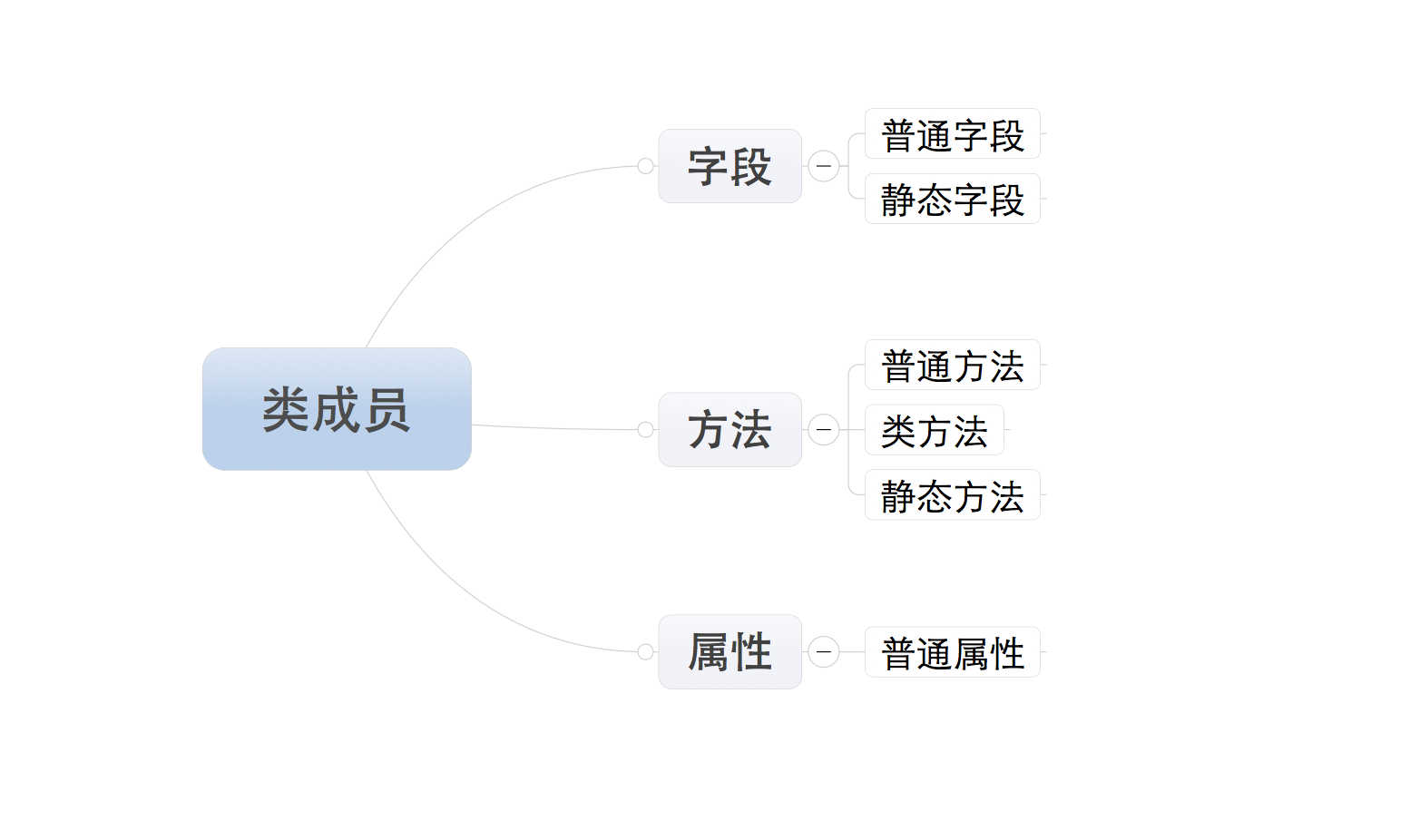
注:所有成员中,只有普通字段的内容保存对象中,即:根据此类创建了多少对象,在内存中就有多少个普通字段。而其他的成员,则都是保存在类中,即:无论对象的多少,在内存中只创建一份。
1、字段
字段包括:普通字段和静态字段,他们在定义和使用中有所区别,而最本质的区别是内存中保存的位置不同,
- 普通字段属于对象
- 静态字段属于类


class Province:
# 静态字段
country = '中国'
def __init__(self, name):
# 普通字段
self.name = name
# 直接访问普通字段
obj = Province('河北省')
print(obj.name)
# 直接访问静态字段
Province.country
由上述代码可以看出【普通字段需要通过对象来访问】【静态字段通过类访问】,在使用上可以看出普通字段和静态字段的归属是不同的。其在内存的存储方式类似如下图:

由上图可是:
- 静态字段在内存中只保存一份
- 普通字段在每个对象中都要保存一份
应用场景: 通过类创建对象时,如果每个对象都具有相同的字段,那么就使用静态字段
2、方法
方法包括:普通方法、静态方法和类方法,三种方法在内存中都归属于类,区别在于调用方式不同。
- 普通方法:由对象调用;至少一个self参数;执行普通方法时,自动将调用该方法的对象赋值给self;
- 类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类复制给cls;
- 静态方法:由类调用;无默认参数;
 方法的定义和使用
方法的定义和使用
class Movie(object): count = 1 def __init__(self,name,length): self.name = name self.length = length #实例方法 def print_name(self): self.aaa = '123' print '电影的名称是:%s' % (self.name,) #类方法 @classmethod def print_len(cls): print '电影的长度是:%d' % (cls.count,) #静态方法 @staticmethod def print_info(str): print '传入的信息是:%s' % (str,)movie1 = Movie('大圣归来',90)movie1.print_name() #通过实例调用实例方法Movie.print_name(movie1) #如果通过类调用实例方法,必须手动传入实例Movie.print_len() #通过类调用类方法movie1.print_len() #通过实例调用类方法Movie.print_info('哈哈') #通过类调用静态方法movie1.print_info('哈哈') #通过实例调用静态方法

相同点:对于所有的方法而言,均属于类(非对象)中,所以,在内存中也只保存一份。
不同点:方法调用者不同、调用方法时自动传入的参数不同。
2.1、普通方法(实例方法)
实例方法可以被类实例调用,通过实例.方法的形式进行调用,这个我们都不陌生了,上面例子中的print_name方法就是实例方法,使用实例方法是传入的参数方法声明时的参数少一个,因为第一个参数self是不用提供的。除此之外实例方法还可以被类调用,形式是类名.方法名(self),必须手动添加self变量,也就是类的实例。
2.2、类方法
类方法可以被类和类实例调用,但是类方法无法访问实例变量,只能访问类变量,声明时在方法前面加上@classmethod,并且方法中的第一个参数是cls而不是self,和实例方法一样,使用时第一个参数不用传递,python的编译器会自动的加上。类方法更像java中的static方法。
|
|
执行报错如下,说Dog没有name属性,因为name是个实例变量,类方法是不能访问实例变量的
| 1 2 3 4 5 6 |
|
此时可以定义一个类变量,也叫name,看下执行效果
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
2.3、静态方法
静态方法可以被类和类实例调用,无法访问实例变量和类变量,只能方法传入进来的参数,声明时在方法前面加上@staticmethod,静态方法没有默认的参数,静态方法有点像函数工具库的作用。
通过@staticmethod装饰器即可把其装饰的方法变为一个静态方法,普通的方法,可以在实例化后直接调用,并且在方法里可以通过self.调用实例变量或类变量,但静态方法是不可以访问实例变量或类变量的,一个不能访问实例变量和类变量的方法,其实相当于跟类本身已经没什么关系了,它与类唯一的关联就是需要通过类名来调用这个方法
| 1 2 3 4 5 6 7 8 9 |
|
上面的调用会出以下错误,说是eat需要一个self参数,但调用时却没有传递,没错,当eat变成静态方法后,再通过实例调用时就不会自动把实例本身当作一个参数传给self了。
| 1 2 3 4 |
|
想让上面的代码可以正常工作有两种办法
1. 调用时主动传递实例本身给eat方法,即d.eat(d)
2. 在eat方法中去掉self参数,但这也意味着,在eat中不能通过self.调用实例中的其它变量了
1 class Dog(object):
3 def __init__(self,name):
4 self.name = name
6 @staticmethod
7 def eat():
8 print(" is eating")
12 d = Dog("ChenRonghua")
13 d.eat()3、属性
3.1、属性的基本使用
class Foo:
def func(self):
print("普通方法")
# 定义属性
@property
def prop(self):
return "属性方法"
foo_obj = Foo()
foo_obj.func()
foo_obj.prop #调用属性由属性的定义和调用要注意一下几点:
- 定义时,在普通方法的基础上添加 @property 装饰器;
- 定义时,属性仅有一个self参数
- 调用时,无需括号 方法:foo_obj.func() 属性:foo_obj.prop
注意:属性存在意义是:访问属性时可以制造出和访问字段完全相同的假象
属性由方法变种而来,如果Python中没有属性,方法完全可以代替其功能。
|
|
调用会出以下错误, 说NoneType is not callable, 因为eat此时已经变成一个静态属性了, 不是方法了, 想调用已经不需要加()号了,直接d.eat就可以了
| 1 2 3 4 5 |
|
正常调用如下
| 1 2 3 4 |
|
3.2、属性的两种定义方式
属性的定义有两种方式:
- 装饰器 即:在方法上应用装饰器:通过@property把一个方法变成一个静态属性
- 静态字段 即:在类中定义值为property对象的静态字段
3.2.1装饰器方式:在类的普通方法上应用@property装饰器
我们知道Python中的类有经典类和新式类,新式类的属性比经典类的属性丰富。( 如果类继承object,那么该类是新式类 )
经典类,具有一种@property装饰器(如上一步实例)已经不推荐使用class Goods: @property def price(self): return "wupeiqi" # ############### 调用 ############### obj = Goods() result = obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值新式类,具有三种@property装饰器
# ############### 定义 ############### class Goods(object): @property def price(self): print '@property' @price.setter def price(self, value): print '@price.setter' @price.deleter def price(self): print '@price.deleter' # ############### 调用 ############### obj = Goods() obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值 obj.price = 123 # 自动执行 @price.setter 修饰的 price 方法,并将 123 赋值给方法的参数 del obj.price # 自动执行 @price.deleter 修饰的 price 方法注:经典类中的属性只有一种访问方式,其对应被 @property 修饰的方法
新式类中的属性有三种访问方式,并分别对应了三个被@property、@方法名.setter、@方法名.deleter修饰的方法由于新式类中具有三种访问方式,我们可以根据他们几个属性的访问特点,分别将三个方法定义为对同一个属性:获取、修改、删除
3.2.2静态字段方式,创建值为property对象的静态字段
当使用静态字段的方式创建属性时,经典类和新式类无区别
class Foo: def get_bar(self): return 'wupeiqi' BAR = property(get_bar) obj = Foo() reuslt = obj.BAR # 自动调用get_bar方法,并获取方法的返回值 print reusltproperty的构造方法中有个四个参数
- 第一个参数是方法名,调用
对象.属性时自动触发执行方法- 第二个参数是方法名,调用
对象.属性 = XXX时自动触发执行方法- 第三个参数是方法名,调用
del 对象.属性时自动触发执行方法- 第四个参数是字符串,调用
对象.属性.__doc__,此参数是该属性的描述信息
class Foo:
def get_bar(self):
return 'wupeiqi'
# *必须两个参数
def set_bar(self, value):
return return 'set value' + value
def del_bar(self):
return 'wupeiqi'
BAR = property(get_bar, set_bar, del_bar, 'description...')
obj = Foo()
obj.BAR # 自动调用第一个参数中定义的方法:get_bar
obj.BAR = "alex" # 自动调用第二个参数中定义的方法:set_bar方法,并将“alex”当作参数传入
del Foo.BAR # 自动调用第三个参数中定义的方法:del_bar方法
obj.BAE.__doc__ # 自动获取第四个参数中设置的值:description...由于静态字段方式创建属性具有三种访问方式,我们可以根据他们几个属性的访问特点,分别将三个方法定义为对同一个属性:获取、修改、删除
class Goods(object):
def __init__(self):
self.original_price = 100# 原价
self.discount = 0.8# 折扣
def get_price(self):
# 实际价格 = 原价 * 折扣
new_price = self.original_price * self.discount
return new_price
def set_price(self, value):
self.original_price = value
def del_price(self, value):
del self.original_price
PRICE = property(get_price, set_price, del_price, '价格属性描述...')
obj = Goods()
obj.PRICE # 获取商品价格
obj.PRICE = 200 # 修改商品原价
del obj.PRICE # 删除商品原价注意:Python WEB框架 Django 的视图中 request.POST 就是使用的静态字段的方式创建的属性
class WSGIRequest(http.HttpRequest):
def __init__(self, environ):
script_name = get_script_name(environ)
path_info = get_path_info(environ)
if not path_info:
# Sometimes PATH_INFO exists, but is empty (e.g. accessing
# the SCRIPT_NAME URL without a trailing slash). We really need to
# operate as if they'd requested '/'. Not amazingly nice to force
# the path like this, but should be harmless.
path_info = '/'
self.environ = environ
self.path_info = path_info
self.path = '%s/%s' % (script_name.rstrip('/'), path_info.lstrip('/'))
self.META = environ
self.META['PATH_INFO'] = path_info
self.META['SCRIPT_NAME'] = script_name
self.method = environ['REQUEST_METHOD'].upper()
_, content_params = cgi.parse_header(environ.get('CONTENT_TYPE', ''))
if 'charset' in content_params:
try:
codecs.lookup(content_params['charset'])
except LookupError:
pass
else:
self.encoding = content_params['charset']
self._post_parse_error = False
try:
content_length = int(environ.get('CONTENT_LENGTH'))
except (ValueError, TypeError):
content_length = 0
self._stream = LimitedStream(self.environ['wsgi.input'], content_length)
self._read_started = False
self.resolver_match = None
def _get_scheme(self):
return self.environ.get('wsgi.url_scheme')
def _get_request(self):
warnings.warn('`request.REQUEST` is deprecated, use `request.GET` or '
'`request.POST` instead.', RemovedInDjango19Warning, 2)
if not hasattr(self, '_request'):
self._request = datastructures.MergeDict(self.POST, self.GET)
return self._request
@cached_property
def GET(self):
# The WSGI spec says 'QUERY_STRING' may be absent.
raw_query_string = get_bytes_from_wsgi(self.environ, 'QUERY_STRING', '')
return http.QueryDict(raw_query_string, encoding=self._encoding)
# ############### 看这里看这里 ###############
def _get_post(self):
if not hasattr(self, '_post'):
self._load_post_and_files()
return self._post
# ############### 看这里看这里 ###############
def _set_post(self, post):
self._post = post
@cached_property
def COOKIES(self):
raw_cookie = get_str_from_wsgi(self.environ, 'HTTP_COOKIE', '')
return http.parse_cookie(raw_cookie)
def _get_files(self):
if not hasattr(self, '_files'):
self._load_post_and_files()
return self._files
# ############### 看这里看这里 ###############
POST = property(_get_post, _set_post)
FILES = property(_get_files)
REQUEST = property(_get_request)3.3为什么要用属性方法
将一个类的函数定义成特性以后,对象再去使用的时候obj.name,根本无法察觉自己的name是执行了一个函数然后计算出来的,这种特性的使用方式遵循了统一访问的原则
想要静态变量,为什么不直接定义成一个静态变量,由于很多场景是不能简单通过定义静态属性来实现的, 比如 ,你想知道一个航班当前的状态,是到达了、延迟了、取消了、还是已经飞走了, 想知道这种状态你必须经历以下几步:
1. 连接航空公司API查询
2. 对查询结果进行解析
3. 返回结果给你的用户
因此这个status属性的值是一系列动作后才得到的结果,所以你每次调用时,其实它都要经过一系列的动作才返回你结果,但这些动作过程不需要用户关心, 用户只需要调用这个属性就可以
实例:
class Flight(object):
def __init__(self,name):
self.flight_name = name
def checking_status(self):
print("checking flight %s status " % self.flight_name)
return 1
@property
def flight_status(self):
status = self.checking_status()
if status == 0 :
print("flight got canceled...")
elif status == 1 :
print("flight is arrived...")
elif status == 2:
print("flight has departured already...")
else:
print("cannot confirm the flight status...,please check later")
f = Flight("CA980")
f.flight_status那现在我只能查询航班状态, 既然这个flight_status已经是个属性了, 如果我们给它赋值会显示无法更改这个属性
| 1 2 3 |
|
| 1 2 3 4 5 6 |
|
如果我们需要修改这个属性,那么需要通过@proerty.setter装饰器再装饰一下,此时 你需要在上面Flight类中写一个新方法,对这个flight_status进行更改。
@flight_status.setter #修改
def flight_status(self,status):
status_dic = {
0 : "canceled",
1 :"arrived",
2 : "departured"
}
print("\033[31;1mHas changed the flight status to \033[0m",status_dic.get(status) )
@flight_status.deleter #删除
def flight_status(self):
print("status got removed...")
f = Flight("CA980")
f.flight_status
f.flight_status = 2 #触发@flight_status.setter
del f.flight_status #触发@flight_status.deleter 注意以上代码里还写了一个@flight_status.deleter, 是允许可以将这个属性删除
ps:面向对象的封装有三种方式:
【public】
这种其实就是不封装,是对外公开的
【protected】
这种封装方式对外不公开,但对朋友(friend)或者子类(形象的说法是“儿子”,但我不知道为什么大家 不说“女儿”,就像“parent”本来是“父母”的意思,但中文都是叫“父类”)公开
【private】
这种封装对谁都不公开python并没有在语法上把它们三个内建到自己的class机制中,在Java等语言里一般会将所有的所有的数据都设置为私有的,然后提供set和get方法(接口)去设置和获取,在python中通过property方法可以实现,如上例
二,类成员的修饰符
类的所有成员在上一步骤中已经做了详细的介绍,对于每一个类的成员而言都有两种形式:
默认情况下,Python中的成员函数和成员变量都是公开的(public),在python中没有类似public,private等关键词来修饰成员函数和成员变量。
- 公有成员,在任何地方都能访问
- 私有成员,只有在类的内部才能方法
私有成员和公有成员的定义不同:私有成员命名时,只需要在变量名或函数名前加上 ”__“两个下划线。(特殊成员除外,例如:__init__、__call__、__dict__等)
| 1 2 3 4 5 |
|
私有成员和公有成员的访问限制不同:
静态字段
- 公有静态字段:类可以访问;类内部可以访问;派生类中可以访问
- 私有静态字段:仅类内部可以访问;
class C:
name = "公有静态字段"
def func(self):
print C.name
class D(C):
def show(self):
print C.name
C.name # 类访问
obj = C()
obj.func() # 类内部可以访问
obj_son = D()
obj_son.show() # 派生类中可以访问class C:
__name = "公有静态字段"
def func(self):
print C.__name
class D(C):
def show(self):
print C.__name
C.__name # 类访问 ==> 错误
obj = C()
obj.func() # 类内部可以访问 ==> 正确
obj_son = D()
obj_son.show() # 派生类中可以访问 ==> 错误普通字段
- 公有普通字段:对象可以访问;类内部可以访问;派生类中可以访问
- 私有普通字段:仅类内部可以访问;
ps:如果想要强制访问私有字段,可以通过 【对象._类名__私有字段明 】访问(如:obj._C__foo),不建议强制访问私有成员。
class C:
def __init__(self):
self.foo = "公有字段"
def func(self):
print self.foo # 类内部访问
class D(C):
def show(self):
print self.foo # 派生类中访问
obj = C()
obj.foo # 通过对象访问
obj.func() # 类内部访问
obj_son = D();
obj_son.show() # 派生类中访问class C:
def __init__(self):
self.__foo = "私有字段"
def func(self):
print self.foo # 类内部访问
class D(C):
def show(self):
print self.foo # 派生类中访问
obj = C()
obj.__foo # 通过对象访问 ==> 错误
obj.func() # 类内部访问 ==> 正确
obj_son = D();
obj_son.show() # 派生类中访问 ==> 错误方法、属性的访问于上述方式相似,即:私有成员只能在类内部使用
实现机制:
在内部,python使用一种 name mangling 技术,将 __membername替换成 _classname__membername,也就是说,类的内部定义中,所有以双下划线开始的名字都被"翻译"成前面加上单下划线和类名的形式。
例如:为了保证不能在class之外访问私有变量,Python会在类的内部自动的把我们定义的__spam私有变量的名字替换成为
_classname__spam(注意,classname前面是一个下划线,spam前是两个下划线),因此,用户在外部访问__spam的时候就会
提示找不到相应的变量。 python中的私有变量和私有方法仍然是可以访问的;访问方法如下:
私有变量:实例._类名__变量名
私有方法:实例._类名__方法名()
• 私有函数不可以从它们的模块外面被调用
• 私有类方法不能够从它们的类外面被调用
• 私有属性不能够从它们的类外面被访问
其实,Python并没有真正的私有化支持,但可用下划线得到伪私有。 尽量避免定义以下划线开头的变量!
(1)_xxx "单下划线 " 开始的成员变量叫做保护变量,意思是只有类实例和子类实例能访问到这些变量,
需通过类提供的接口进行访问;不能用'from module import *'导入
(2)__xxx 类中的私有变量/方法名 (Python的函数也是对象,所以成员方法称为成员变量也行得通。),
" 双下划线 " 开始的是私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据。
(3)__xxx__ 系统定义名字,前后均有一个“双下划线” 代表python里特殊方法专用的标识,如 __init__()代表类的构造函数。
私有变量
#其实这仅仅这是一种变形操作
#类中所有双下划线开头的名称如__x都会自动变形成:_类名__x的形式:
class A:
__N=0 #类的数据属性就应该是共享的,但是语法上是可以把类的数据属性设置成私有的如__N,会变形为_A__N
def __init__(self):
self.__X=10 #变形为self._A__X
def __foo(self): #变形为_A__foo
print('from A')
def bar(self):
self.__foo() #只有在类内部才可以通过__foo的形式访问到.
#A._A__N是可以访问到的,即这种操作并不是严格意义上的限制外部访问,仅仅只是一种语法意义上的变形这种自动变形的特点:
1.类中定义的__x只能在内部使用,如self.__x,引用的就是变形的结果。
2.这种变形其实正是针对外部的变形,在外部是无法通过__x这个名字访问到的。
3.在子类定义的__x不会覆盖在父类定义的__x,因为子类中变形成了:_子类名__x,而父类中变形成了:_父类名__x,即双下滑线开头的属性在继承给子类时,子类是无法覆盖的。
这种变形需要注意的问题是:
1.这种机制也并没有真正意义上限制我们从外部直接访问属性,知道了类名和属性名就可以拼出名字:_类名__属性,然后就可以访问了,如a._A__N
2.变形的过程只在类的内部生效,在定义后的赋值操作,不会变形

私有方法
在继承中,父类如果不想让子类覆盖自己的方法,可以将方法定义为私有的
#正常情况
>>> class A:
... def fa(self):
... print('from A')
... def test(self):
... self.fa()
...
>>> class B(A):
... def fa(self):
... print('from B')
...
>>> b=B()
>>> b.test()
from B
#把fa定义成私有的,即__fa
>>> class A:
... def __fa(self): #在定义时就变形为_A__fa
... print('from A')
... def test(self):
... self.__fa() #只会与自己所在的类为准,即调用_A__fa
...
>>> class B(A):
... def __fa(self):
... print('from B')
...
>>> b=B()
>>> b.test()
from A小结
分别有静态字段、静态方法、类方法、特性、普通字段、普通方法、
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
|
成员小节:
- 自己去访问自己的成员,除了类中的方法
-
通过类访问的有:静态字段、静态方法、类方法
-
通过对象访问:普通字段、普通方法 、特性
静态字段:存在类中 ,静态字段存在的意:把对象里面重复的数据只在类里保存一份 静态方法 :没有self 可以传参数,调用的时候也需要传入参数 ,存在的意义:不需要创建对象,就可以访问此方法 ,为类而生 类方法:必须要有个cls参数:自动传入类名 特性 对象调用 、不能加参数,执行不用加括号 普通字段,存放在对象中 普通方法 存在的意义:普通方法如果要想被调用就需要创建self ,为对象而生
四、成员修饰符
公有成员:任何地方都能访问
私有成员:只有在类的内部才能访问,定义方式为命名时,前两个字符为下划线,如 "__test"
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
小节:私有成员只能在类内部使用,其他的都不能使用包括继承的子类,也不是绝对 也可以通过访问,但是不推荐
对象._类名__字段名
类的特殊成员:
| 1 2 3 4 5 6 7 8 9 10 |
|
下面我们看几个例子:【1】
- class A(object):
- def __init__(self):
- self.__data=[] #翻译成 self._A__data=[]
- def add(self,item):
- self.__data.append(item) #翻译成 self._A__data.append(item)
- def printData(self):
- print self.__data #翻译成 self._A__data
- a=A()
- a.add('hello')
- a.add('python')
- a.printData()
- #print a.__data #外界不能访问私有变量 AttributeError: 'A' object has no attribute '__data'
- print a._A__data #通过这种方式,在外面也能够访问“私有”变量;这一点在调试中是比较有用的!
运行结果是:
['hello', 'python']
['hello', 'python']
【2】获取实例的所有属性 print a.__dict__
获取实例的所有属性和方法 print dir(a)
- class A():
- def __init__(self):
- self.__name='python' #私有变量,翻译成 self._A__name='python'
- def __say(self): #私有方法,翻译成 def _A__say(self)
- print self.__name #翻译成 self._A__name
- a=A()
- #print a.__name #访问私有属性,报错!AttributeError: A instance has no attribute '__name'
- print a.__dict__ #查询出实例a的属性的集合
- print a._A__name #这样,就可以访问私有变量了
- #a.__say()#调用私有方法,报错。AttributeError: A instance has no attribute '__say'
- print dir(a)#获取实例的所有属性和方法
- a._A__say() #这样,就可以调用私有方法了
运行结果:
{'_A__name': 'python'}
python
['_A__name', '_A__say', '__doc__', '__init__', '__module__']
python
从上面看来,python还是非常的灵活,它的oop没有做到真正的不能访问,只是一种约定让大家去遵守,
比如大家都用self来代表类里的当前对象,其实,我们也可以用其它的,只是大家习惯了用self 。
【3】小漏洞:派生类和基类取相同的名字就可以使用基类的私有变量
- class A():
- def __init__(self):
- self.__name='python' #翻译成self._A__name='python'
- class B(A):
- def func(self):
- print self.__name #翻译成print self._B__name
- instance=B()
- #instance.func()#报错:AttributeError: B instance has no attribute '_B__name'
- print instance.__dict__
- print instance._A__name
运行结果:
{'_A__name': 'python'}
python
- class A():
- def __init__(self):
- self.__name='python' #翻译成self._A__name='python'
- class A(A): #派生类和基类取相同的名字就可以使用基类的私有变量。
- def func(self):
- print self.__name #翻译成print self._A__name
- instance=A()
- instance.func()
运行结果:
python
| 绑定方法与非绑定方法 |
绑定方法的使用:
1、在类内部定义的方法,在没有被任何装饰器修饰的情况下,就是为了绑定到对象给对象 用的,self关键字含有自动传值的过程,不管写不写self关键子。
2、默认情况下,在类内部定义的方法都是绑定到对象的方法。
3、绑定方法绑定到谁的身上,谁就作为第一个参数进行传入。
4、绑定到类的方法给对象使用是没有任何意义的。
非绑定方法:
statimethod不与类或对象绑定,谁都可以调用,没有自动传值效果,python为我们内置了函数staticmethod来把类中的函数定义成静态方法
不与类或对象绑定,类和对象都可以调用,但是没有自动传值那么一说。就是一个普通工具而已
只有绑定方法才存在自动传值的说法。
总结:
绑定到对象的方法,调用的时候会将对象参数自动传入, ===>方法上面什么也不加
绑定到类的方法,调用的时候会将类作为参数自动传入, ===>方法上面加classmethod
非绑定方法不与类或对象绑定,类和对象都可以调用,但是没有自动传值那么一说。===>static
使用场景:
看使用什么调用?类对象or类or什么参数都不需要.
模拟数据库登陆的场景。
(只有类才有实例化的说法)
创建数据库的时候加上一个id属性,指定是哪一个链接。
每次数据库实例话的时候都要赋值一个id。
示例程序1:
#造成id的方式,用hash算法
import time
import hashlib
def create_id():
m = hashlib.md5(str(time.clock()).encode("utf-8"))
return m.hexdigest()
#time.clock()计算的是cpu真实的时间
print(create_id())
print(create_id())
print(create_id())
print(create_id())运行结果:
3a92235c44873cbcf618a132a2781157
aa0968a1f467ba19f1595c70efb2c3ee
abc4e2f842e0283b2186d459c069d301
28e76bcb1724833a847851e8f2286e65
Process finished with exit code 0- 示例程序2:
import settings
import time
import hashlib
class MySQL:
def __init__(self,host, port):
self.id = self.create_id()
self.host = host
self.port = port
print("connecting.....")
def select(self): # 绑定到对象的方法
print(self)
print("select function")
# 绑定到类的方法,从配置文件中获取主机名和端口号,用户默认链接数据库的一种方式
@classmethod
def from_conf(cls):
# 实例话的结果得到了一个类对象
# 通过绑定对象的方法间接的去创建了一个类对象
return cls(settings.HOST, settings.PORT) # 相当于MySQL("127.1.1.1",3306)
#工具包既不依赖于类,也不依赖于对象
#非绑定方法就是类中普通的工具包,不依赖于self和cls的参数
@staticmethod
def create_id():
m = hashlib.md5(str(time.clock()).encode("utf-8"))
return m.hexdigest()
if __name__ == '__main__':
conn = MySQL("192.168.80.100", 3306)
conn.select()
conn2 = MySQL.from_conf()
conn2.select()
print(conn.id)
print(conn2.id)- 运行结果:
connecting.....
<__main__.MySQL object at 0x0000000002584438>
select function
connecting.....
<__main__.MySQL object at 0x0000000002584EB8>
select function
3a92235c44873cbcf618a132a2781157
294e6de59d0e8d4a75717d5bb20f92e0
Process finished with exit code 0-
staticmethod与classmethod的区别
staticmethod与classmethod的区别:前者是非绑定方法,后者是绑定到类的方法
示例程序1:
import settings
import time
import hashlib
class MySQL:
def __init__(self,host, port):
self.host = host
self.port = port
print("connecting.....")
@staticmethod
def from_conf():
return MySQL(settings.HOST,settings.PORT) #相当于MySQL("127.1.1.1",3306)
def __str__(self):
return "父类"
class Mariab(MySQL):
def __str__(self):
return "子类"
if __name__ == '__main__':
conn = MySQL.from_conf()
print(conn.host)
conn1 = Mariab.from_conf()
print(conn1.host)
#本来想获取Mariab的一个对象,但是现在获取的是MySQL的一个对象,这是子类继承的一个问题
print(conn1)运行结果:
connecting.....
127.1.1.1
connecting.....
127.1.1.1
父类
Process finished with exit code 0示例程序2:基于1的改进
#!/usr/bin/python
# -*- coding:utf-8 -*-
import settings
import time
import hashlib
class MySQL:
def __init__(self,host, port):
self.host = host
self.port = port
print("connecting.....")
@classmethod
def from_conf(cls):
return cls(settings.HOST,settings.PORT) #相当于MySQL("127.1.1.1",3306)
def __str__(self):
return "父类"
class Mariab(MySQL):
def __str__(self):
return "子类"
if __name__ == '__main__':
conn = MySQL.from_conf()
print(conn.host)
conn1 = Mariab.from_conf()
print(conn1.host)
#本来想获取Mariab的一个对象,但是现在获取的是MySQL的一个对象,这是子类继承的一个问题
print(conn1)运行结果:
connecting.....
127.1.1.1
connecting.....
127.1.1.1
子类
Process finished with exit code 0| 总和应用的一个小例子 |
要求:
定义MySQL类
1.对象有id、host、port三个属性
2.定义工具create_id,在实例化时为每个对象随机生成id,保证id唯一
3.提供两种实例化方式,方式一:用户传入host和port 方式二:从配置文件中读取host和port进行实例化
4.为对象定制方法,save和get,save能自动将对象序列化到文件中,文件名为id号,文件路径为配置文件中DB_PATH;get方法用来从文件中反序列化出对象。
代码示例:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import time
import hashlib
import settings
import random
import pickle
import os
"""
HOST = "127.1.1.1"
PORT = 3306
DB_PATH = r"D:\Python Work Location\Python 0507\day07\db"
"""
class MySQL:
@staticmethod
def create_id():
m = hashlib.md5(str(time.clock()).encode("utf-8"))
return m.hexdigest()
def __init__(self,host,port):
#为每一个对象创建了一个ID
self.id = self.create_id()
self.host = host
self.port = port
#从配置文件中读取在这里用到了classmethod
@classmethod
def from_conf(cls):
return cls(settings.HOST,settings.PORT)
def save(self):
file_path = r"%s%s%s"%(settings.DB_PATH,os.sep,self.id)
#将这个对象以二进制的形式写到硬盘当中
pickle.dump(self,open(file_path,"wb"))
def get(self):
#在这里面通过id的方式保证了文件的名字是唯一的
file_path = r"%s%s%s" % (settings.DB_PATH, os.sep, self.id)
return pickle.load(open(file_path,"rb"))
#对于Python中的对象json无法进行序列化
if __name__ == '__main__':
conn1 = MySQL("172.1.2.1","3306")
print(conn1.id)
conn1.save()
result = conn1.get()
print(result.id)
#通过os.listdir命令可以浏览某一个目录下面有哪些文件,然后循环的反序列化
print(os.listdir(r"D:\Python Work Location\Python 0507\day07\db"))运行结果:
85b8a467159e14ec4b2d16bff39ed199
85b8a467159e14ec4b2d16bff39ed199
['85b8a467159e14ec4b2d16bff39ed199', 'd0cff574feed705df3655a209c79c7ef']
Process finished with exit code 0五、isinstance和type的区别以及issubclass
issubclass用于判断给定的两个类,前者是否是后者的子类
isinstance和type都可以用于判断对象和指定类间的关系,但是isinstance的判断没有type准确,它无法正确判断子类的对象和其父类的关系
class A:
pass
class B(A):
pass
b=B()
print(isinstance(b,B))
print(isinstance(b,A))
print(type(b) is B)
print(type(b) is A)
--------------------------------------------------------------------------------------
True
True
True
False六,抽象类与接口类
OO开发范式大致为:划分对象→抽象类→将类组织成为层次化结构(继承和合成) →用类与实例进行设计和实现几个阶段。
几个名词
抽象:抽象就是把一类事物的共有特性提取出来。是一个从具体到抽象的过程。抽象是包含的范围越来越大,共性越来越少,定义父类
继承:继承则是把父类的属性拿过来并且还拥有自己的属性,继承则是包含的返回越来越小,共性越来越多,定义子类
派生:子类在父类方法和属性的基础上产生了新的方法和属性抽象/实现
抽象指对现实世界问题和实体的本质表现,行为和特征建模,建立一个相关的子集,可以用于 绘程序结构,从而实现这种模型。抽象不仅包括这种模型的数据属性,还定义了这些数据的接口。
对某种抽象的实现就是对此数据及与之相关接口的现实化(realization)。现实化这个过程对于客户 程序应当是透明而且无关的。
封装/接口
封装描述了对数据/信息进行隐藏的观念,它对数据属性提供接口和访问函数。通过任何客户端直接对数据的访问,无视接口,与封装性都是背道而驰的,除非程序员允许这些操作。作为实现的 一部分,客户端根本就不需要知道在封装之后,数据属性是如何组织的。在Python中,所有的类属性都是公开的,但名字可能被“混淆”了,以阻止未经授权的访问,但仅此而已,再没有其他预防措施了。这就需要在设计时,对数据提供相应的接口,以免客户程序通过不规范的操作来存取封装的数据属性。
注意:封装绝不是等于“把不想让别人看到、以后可能修改的东西用private隐藏起来”
真正的封装是,经过深入的思考,做出良好的抽象,给出“完整且最小”的接口,并使得内部细节可以对外透明
(注意:对外透明的意思是,外部调用者可以顺利的得到自己想要的任何功能,完全意识不到内部细节的存在)
| 6.1抽象类的概念 |
什么是抽象类
与java一样,python也有抽象类的概念但是同样需要借助模块实现,抽象类是一个特殊的类,它的特殊之处在于只能被继承,不能被实例化
为什么要有抽象类
如果说类是从一堆对象中抽取相同的内容而来的,那么抽象类就是从一堆类中抽取相同的内容而来的,内容包括数据属性和函数属性。
比如我们有香蕉的类,有苹果的类,有桃子的类,从这些类抽取相同的内容就是水果这个抽象的类,你吃水果时,要么是吃一个具体的香蕉,要么是吃一个具体的桃子。。。。。。你永远无法吃到一个叫做水果的东西。
从设计角度去看,如果类是从现实对象抽象而来的,那么抽象类就是基于类抽象而来的。
从实现角度来看,抽象类与普通类的不同之处在于:抽象类中有抽象方法,该类不能被实例化,只能被继承,且子类必须实现抽象方法。
抽象类的作用和接口类一样,只是继承它的子类一般存在一些逻辑上的关系,且抽象类中的方法可以去实现,子类在重写时用super函数调用抽象类的方法即可,同时在用抽象类时使用单继承,使用接口类时使用多继
1>Python中抽象方法定义的方式:利用abc模块实现抽象类,在Java当中如果一个方法没有执行体就叫做抽象方法,而在Python中不是以执行体的有无作为标准,而是以一个方法是否有@abc.abstractmethod装饰器作为标准,有则是抽象方法
2>抽象方法通过子类的实现可以变成普通的方法
3>抽象方法不存在所谓重写的问题,却存在着实现的问题
4>含有抽象方法的类一定是抽象类,但是抽象类不一定含有抽象方法,此时也就没有什么意义了
5>抽象类是一个介于类和接口直接的一个概念,同时具备类和接口的部分特性,可以用来实现归一化设计
示例程序:
import abc
class File(metaclass=abc.ABCMeta):
@abc.abstractmethod
def read(self):
pass
#抽象类中可以有普通方法
def write(self):
print("11111")
class B(File):
#如果写pass,也是可以的,此时子类将会覆盖掉父类
def read(self):
pass
if __name__ == '__main__':
bb = B()
bb.read()
bb.write()运行结果:
11111
Process finished with exit code 01.多继承问题
在继承抽象类的过程中,我们应该尽量避免多继承;
而在继承接口的时候,我们反而鼓励你来多继承接口
接口隔离原则:
使用多个专门的接口,而不使用单一的总接口。即客户端不应该依赖那些不需要的接口。2.方法的实现在抽象类中,我们可以对一些抽象方法做出基础实现;而在接口类中,任何方法都只是一种规范,具体的功能需要子类实现
| 6.2接口的概念 |
1、通过接口可以实现不相关类的相同行为,可以起到一个标志的作用.
2、接口提供了不同的类进行相互协作的平台
3、在python中根本就没有一个叫做interface的关键字,如果非要去模仿接口的概念,可以借助第三方模块
4、raise:主动抛出异常,本来没有错,主动抛出错。
raise TypeError(“类型错误”)
示例程序:
#模拟Java中接口的概念
class S1:
def read(self):
raise TypeError("类型错误")
def write(self):
raise TypeError("类型错误")
class S2(S1):
def read(self):
print("from S2")
def write(self):
print("from S2")
class S3(S1):
def read(self):
print("from S3")
def read(self):
print("from S3")
if __name__ == '__main__':
s2 = S2()
s2.read()
s3 = S3()
s3.read()运行结果:
from S2
from S3
Process finished with exit code 0在上面的程序中存在着一个问题,在S2和S3中如果不实现read和write方法,仍然可以实例化,如何解决,看抽象类的概念。
接口类是用于规范子类的方法名定义用的,继承接口类的子类可以不存在任何逻辑上的关系但是都需要实现某些共同的方法,为了让这些子类的方法名能够统一以便之后调用这些方法时不需要关注具体的对象就用接口类规范了这些方法的名字,子类一旦继承了接口类就必须实现接口类中定义的方法,否则在子类实例化的时候就会报错,而接口类本身则不需要实现去实现这些方法。
1 from abc import ABCMeta,abstractmethod
2 class Payment(metaclass=ABCMeta):
3 @abstractmethod
4 def pay(self,money):pass
5
6 class Wechatpay(Payment):
7 def pay(self,money): #子类中必须定义接口类中有的方法,否则实例化会报错
8 pass
9
10 w1=Wechatpay()6.3继承概念的实现方式
主要有2类:实现继承、接口继承。
1,实现继承是指使用基类的属性和方法而并且做出自己的改变或者扩展;(主要用于代码重用)
2,接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力(子类重构爹类方法);
在考虑使用继承时,有一点需要注意,那就是两个类之间的关系应该是“属于”关系。例如,Employee 是一个人,Manager 也是一个人,因此这两个类都可以继承 Person 类。但是 Leg 类却不能继承 Person 类,因为腿并不是一个人。
抽象类仅定义将由子类创建的一般属性和方法。
实践中,实现继承意义并不很大,甚至常常是有害的。因为它使得子类与基类出现强耦合。
我们需要重点关注“接口继承”。
接口继承实质上是要求“做出一个良好的抽象,这个抽象规定了一个兼容接口,使得外部调用者无需关心具体细节,可一视同仁的处理实现了特定接口的所有对象”——这在程序设计上,叫做归一化。
归一化使得高层的外部使用者可以不加区分的处理所有接口兼容的对象集合——就好象linux的泛文件概念一样,所有东西都可以当文件处理,不必关心它是内存、磁盘、网络还是屏幕(当然,对底层设计者,当然也可以区分出“字符设备”和“块设备”,然后做出针对性的设计:细致到什么程度,视需求而定)。
依赖倒置原则:
高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该应该依赖细节;细节应该依赖抽象。换言之,要针对接口编程,而不是针对实现编程在python中根本就没有一个叫做interface的关键字,如果非要去模仿接口的概念,可以借助第三方模块:
http://pypi.python.org/pypi/zope.interface
twisted的twisted\internet\interface.py里使用zope.interface
文档https://zopeinterface.readthedocs.io/en/latest/
设计模式:https://github.com/faif/python-patterns
6.4、父类方法重写
我们把子类有而父类没有的方法叫做子类的派生方法,而父类有子类也有的方法叫做对父类方法的重写,因为按照类方法的搜索顺序一个方法如果在子类中有就不会再从父类中找了,结果就是父类中的方法无法调用了,如果既想执行父类中的方法同时在子类中又能定义新功能,就需要先把父类中的这个方法单独继承过来,在python中只能使用父类名.方法名(self,父类的其他参数)的方式,在python3中可以使用super函数来实现,比如super().父类方法名(除self外的其他参数),其实在super函数中还需要传入子类名和子类对象(在类中用self),但是我们使用时不需要特意去传,除非在类外单独调用父类的方法。注意在继承父类方法时父类的参数除了需要在父类的方法中传递还需要在子类重写的方法中传递
class Animal:
def __init__(self,name,life_value,aggr):
self.name=name
self.life_value=life_value
self.aggr=aggr
def eat(self):
self.life_value+=10
class Person(Animal):
def __init__(self,money,name,life_value,aggr):
super().__init__(name,life_value,aggr)
self.money=money
def attack(self,obj):
obj.life_value-=self.aggr
七,面向对象的软件开发
很多人在学完了python的class机制之后,遇到一个生产中的问题,还是会懵逼,这其实太正常了,因为任何程序的开发都是先设计后编程,python的class机制只不过是一种编程方式,如果你硬要拿着class去和你的问题死磕,变得更加懵逼都是分分钟的事,在以前,软件的开发相对简单,从任务的分析到编写程序,再到程序的调试,可以由一个人或一个小组去完成。但是随着软件规模的迅速增大,软件任意面临的问题十分复杂,需要考虑的因素太多,在一个软件中所产生的错误和隐藏的错误、未知的错误可能达到惊人的程度,这也不是在设计阶段就完全解决的。
所以软件的开发其实一整套规范,我们所学的只是其中的一小部分,一个完整的开发过程,需要明确每个阶段的任务,在保证一个阶段正确的前提下再进行下一个阶段的工作,称之为软件工程
面向对象的软件工程包括下面几个部:
1.面向对象分析(object oriented analysis ,OOA)
软件工程中的系统分析阶段,要求分析员和用户结合在一起,对用户的需求做出精确的分析和明确的表述,从大的方面解析软件系统应该做什么,而不是怎么去做。面向对象的分析要按照面向对象的概念和方法,在对任务的分析中,从客观存在的事物和事物之间的关系,贵南出有关的对象(对象的‘特征’和‘技能’)以及对象之间的联系,并将具有相同属性和行为的对象用一个类class来标识。
建立一个能反映这是工作情况的需求模型,此时的模型是粗略的。
2 面向对象设计(object oriented design,OOD)
根据面向对象分析阶段形成的需求模型,对每一部分分别进行具体的设计。
首先是类的设计,类的设计可能包含多个层次(利用继承与派生机制)。然后以这些类为基础提出程序设计的思路和方法,包括对算法的设计。
在设计阶段并不牵涉任何一门具体的计算机语言,而是用一种更通用的描述工具(如伪代码或流程图)来描述
3 面向对象编程(object oriented programming,OOP)
根据面向对象设计的结果,选择一种计算机语言把它写成程序,可以是python
4 面向对象测试(object oriented test,OOT)
在写好程序后交给用户使用前,必须对程序进行严格的测试,测试的目的是发现程序中的错误并修正它。
面向对的测试是用面向对象的方法进行测试,以类作为测试的基本单元。
5 面向对象维护(object oriendted soft maintenance,OOSM)
正如对任何产品都需要进行售后服务和维护一样,软件在使用时也会出现一些问题,或者软件商想改进软件的性能,这就需要修改程序。
由于使用了面向对象的方法开发程序,使用程序的维护比较容易。
因为对象的封装性,修改一个对象对其他的对象影响很小,利用面向对象的方法维护程序,大大提高了软件维护的效率,可扩展性高。
在面向对象方法中,最早发展的肯定是面向对象编程(OOP),那时OOA和OOD都还没有发展起来,因此程序设计者为了写出面向对象的程序,还必须深入到分析和设计领域,尤其是设计领域,那时的OOP实际上包含了现在的OOD和OOP两个阶段,这对程序设计者要求比较高,许多人感到很难掌握。
现在设计一个大的软件,是严格按照面向对象软件工程的5个阶段进行的,这个5个阶段的工作不是由一个人从头到尾完成的,而是由不同的人分别完成,这样OOP阶段的任务就比较简单了。程序编写者只需要根据OOd提出的思路,用面向对象语言编写出程序既可。
在一个大型软件开发过程中,OOP只是很小的一个部分。
对于全栈开发的你来说,这五个阶段都有了,对于简单的问题,不必严格按照这个5个阶段进行,往往由程序设计者按照面向对象的方法进行程序设计,包括类的设计和程序的设计
八,类的特殊成员方法
1. __doc__ 表示类的描述信息
| 1 2 3 4 5 6 |
|
2. __module__ 和 __class__
__module__ 表示当前操作的对象在那个模块
__class__ 表示当前操作的对象的类是什么
class C:
def __init__(self):
self.name = 'wupeiqi'from lib.aa import C
obj = C()
print obj.__module__ # 输出 lib.aa,即:输出模块
print obj.__class__ # 输出 lib.aa.C,即:输出类3. __init__ 构造方法,通过类创建对象时,自动触发执行。
4.__del__
析构方法,当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以,析构函数的调用是由解释器在进行垃圾回收时自动触发执行的
5. __call__ 对象后面加括号,触发执行。
注:构造方法的执行是由创建对象触发的,即:对象 = 类名() ;而对于 __call__ 方法的执行是由对象后加括号触发的,即:对象() 或者 类()()
| 1 2 3 4 5 6 7 8 |
|
6. __dict__ 查看类或对象中的所有成员
| 1 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
7.__str__ 如果一个类中定义了__str__方法,那么在打印 对象 时,默认输出该方法的返回值。
| 1 2 3 4 5 6 |
|
8.__getitem__、__setitem__、__delitem__
用于索引操作,如字典。以上分别表示获取、设置、删除数据
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
9. __new__ \ __metaclass__
| 1 2 3 4 |
|
上述代码中,obj 是通过 Foo 类实例化的对象,其实,不仅 obj 是一个对象,Foo类本身也是一个对象,因为在Python中一切事物都是对象。
如果按照一切事物都是对象的理论:obj对象是通过执行Foo类的构造方法创建,那么Foo类对象应该也是通过执行某个类的 构造方法 创建。
| 1 2 |
|
所以,f对象是Foo类的一个实例,Foo类对象是 type 类的一个实例,即:Foo类对象 是通过type类的构造方法创建。
那么,创建类就可以有两种方式:
a). 普通方式
| 1 2 3 4 |
|
b). 特殊方式
| 1 2 3 4 5 6 7 |
|
def func(self):
print("hello %s"%self.name)
def __init__(self,name,age):
self.name = name
self.age = age
Foo = type('Foo',(object,),{'func':func,'__init__':__init__})
f = Foo("jack",22)
f.func()
九,元类
type()
动态语言和静态语言最大的不同,就是函数和类的定义,不是编译时定义的,而是运行时动态创建的。
比方说我们要定义一个Hello的class,就写一个hello.py模块:
class Hello(object):
def hello(self, name='world'):
print('Hello, %s.' % name)
当Python解释器载入hello模块时,就会依次执行该模块的所有语句,执行结果就是动态创建出一个Hello的class对象,测试如下:
>>> from hello import Hello
>>> h = Hello()
>>> h.hello()
Hello, world.
>>> print(type(Hello))
<class 'type'>
>>> print(type(h))
<class 'hello.Hello'>
type()函数可以查看一个类型或变量的类型,Hello是一个class,它的类型就是type,而h是一个实例,它的类型就是class Hello。
我们说class的定义是运行时动态创建的,而创建class的方法就是使用type()函数。
type()函数既可以返回一个对象的类型,又可以创建出新的类型,比如,我们可以通过type()函数创建出Hello类,而无需通过class Hello(object)...的定义:
>>> def fn(self, name='world'): # 先定义函数
... print('Hello, %s.' % name)
...
>>> Hello = type('Hello', (object,), dict(hello=fn)) # 创建Hello class
>>> h = Hello()
>>> h.hello()
Hello, world.
>>> print(type(Hello))
<class 'type'>
>>> print(type(h))
<class '__main__.Hello'>
要创建一个class对象,type()函数依次传入3个参数:
- class的名称;
- 继承的父类集合,注意Python支持多重继承,如果只有一个父类,别忘了tuple的单元素写法;
- class的方法名称与函数绑定,这里我们把函数
fn绑定到方法名hello上。
通过type()函数创建的类和直接写class是完全一样的,因为Python解释器遇到class定义时,仅仅是扫描一下class定义的语法,然后调用type()函数创建出class。
正常情况下,我们都用class Xxx...来定义类,但是,type()函数也允许我们动态创建出类来,也就是说,动态语言本身支持运行期动态创建类,这和静态语言有非常大的不同,要在静态语言运行期创建类,必须构造源代码字符串再调用编译器,或者借助一些工具生成字节码实现,本质上都是动态编译,会非常复杂。
metaclass
除了使用type()动态创建类以外,要控制类的创建行为,还可以使用metaclass。
metaclass,直译为元类,简单的解释就是:
当我们定义了类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。
但是如果我们想创建出类呢?那就必须根据metaclass创建出类,所以:先定义metaclass,然后创建类。
连接起来就是:先定义metaclass,就可以创建类,最后创建实例。
所以,metaclass允许你创建类或者修改类。换句话说,你可以把类看成是metaclass创建出来的“实例”。
metaclass是Python面向对象里最难理解,也是最难使用的魔术代码。正常情况下,你不会碰到需要使用metaclass的情况,所以,以下内容看不懂也没关系,因为基本上你不会用到。
我们先看一个简单的例子,这个metaclass可以给我们自定义的MyList增加一个add方法:
定义ListMetaclass,按照默认习惯,metaclass的类名总是以Metaclass结尾,以便清楚地表示这是一个metaclass:
# metaclass是类的模板,所以必须从`type`类型派生:
class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs['add'] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attrs)
有了ListMetaclass,我们在定义类的时候还要指示使用ListMetaclass来定制类,传入关键字参数metaclass:
class MyList(list, metaclass=ListMetaclass):
pass
当我们传入关键字参数metaclass时,魔术就生效了,它指示Python解释器在创建MyList时,要通过ListMetaclass.__new__()来创建,在此,我们可以修改类的定义,比如,加上新的方法,然后,返回修改后的定义。
__new__()方法接收到的参数依次是:
-
当前准备创建的类的对象;
-
类的名字;
-
类继承的父类集合;
-
类的方法集合。
测试一下MyList是否可以调用add()方法:
>>> L = MyList()
>>> L.add(1)
>> L
[1]
而普通的list没有add()方法:
>>> L2 = list()
>>> L2.add(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute 'add'
动态修改有什么意义?直接在MyList定义中写上add()方法不是更简单吗?正常情况下,确实应该直接写,通过metaclass修改纯属变态。
但是,总会遇到需要通过metaclass修改类定义的。ORM就是一个典型的例子。
ORM全称“Object Relational Mapping”,即对象-关系映射,就是把关系数据库的一行映射为一个对象,也就是一个类对应一个表,这样,写代码更简单,不用直接操作SQL语句。
要编写一个ORM框架,所有的类都只能动态定义,因为只有使用者才能根据表的结构定义出对应的类来。
让我们来尝试编写一个ORM框架。
编写底层模块的第一步,就是先把调用接口写出来。比如,使用者如果使用这个ORM框架,想定义一个User类来操作对应的数据库表User,我们期待他写出这样的代码:
class User(Model):
# 定义类的属性到列的映射:
id = IntegerField('id')
name = StringField('username')
email = StringField('email')
password = StringField('password')
# 创建一个实例:
u = User(id=12345, name='Michael', email='[email protected]', password='my-pwd')
# 保存到数据库:
u.save()
其中,父类Model和属性类型StringField、IntegerField是由ORM框架提供的,剩下的魔术方法比如save()全部由metaclass自动完成。虽然metaclass的编写会比较复杂,但ORM的使用者用起来却异常简单。
现在,我们就按上面的接口来实现该ORM。
首先来定义Field类,它负责保存数据库表的字段名和字段类型:
class Field(object):
def __init__(self, name, column_type):
self.name = name
self.column_type = column_type
def __str__(self):
return '<%s:%s>' % (self.__class__.__name__, self.name)
在Field的基础上,进一步定义各种类型的Field,比如StringField,IntegerField等等:
class StringField(Field):
def __init__(self, name):
super(StringField, self).__init__(name, 'varchar(100)')
class IntegerField(Field):
def __init__(self, name):
super(IntegerField, self).__init__(name, 'bigint')
下一步,就是编写最复杂的ModelMetaclass了:
class ModelMetaclass(type):
def __new__(cls, name, bases, attrs):
if name=='Model':
return type.__new__(cls, name, bases, attrs)
print('Found model: %s' % name)
mappings = dict()
for k, v in attrs.items():
if isinstance(v, Field):
print('Found mapping: %s ==> %s' % (k, v))
mappings[k] = v
for k in mappings.keys():
attrs.pop(k)
attrs['__mappings__'] = mappings # 保存属性和列的映射关系
attrs['__table__'] = name # 假设表名和类名一致
return type.__new__(cls, name, bases, attrs)
以及基类Model:
class Model(dict, metaclass=ModelMetaclass):
def __init__(self, **kw):
super(Model, self).__init__(**kw)
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Model' object has no attribute '%s'" % key)
def __setattr__(self, key, value):
self[key] = value
def save(self):
fields = []
params = []
args = []
for k, v in self.__mappings__.items():
fields.append(v.name)
params.append('?')
args.append(getattr(self, k, None))
sql = 'insert into %s (%s) values (%s)' % (self.__table__, ','.join(fields), ','.join(params))
print('SQL: %s' % sql)
print('ARGS: %s' % str(args))
当用户定义一个class User(Model)时,Python解释器首先在当前类User的定义中查找metaclass,如果没有找到,就继续在父类Model中查找metaclass,找到了,就使用Model中定义的metaclass的ModelMetaclass来创建User类,也就是说,metaclass可以隐式地继承到子类,但子类自己却感觉不到。
在ModelMetaclass中,一共做了几件事情:
-
排除掉对
Model类的修改; -
在当前类(比如
User)中查找定义的类的所有属性,如果找到一个Field属性,就把它保存到一个__mappings__的dict中,同时从类属性中删除该Field属性,否则,容易造成运行时错误(实例的属性会遮盖类的同名属性); -
把表名保存到
__table__中,这里简化为表名默认为类名。
在Model类中,就可以定义各种操作数据库的方法,比如save(),delete(),find(),update等等。
我们实现了save()方法,把一个实例保存到数据库中。因为有表名,属性到字段的映射和属性值的集合,就可以构造出INSERT语句。
编写代码试试:
u = User(id=12345, name='Michael', email='[email protected]', password='my-pwd')
u.save()
输出如下:
Found model: User
Found mapping: email ==> <StringField:email>
Found mapping: password ==> <StringField:password>
Found mapping: id ==> <IntegerField:uid>
Found mapping: name ==> <StringField:username>
SQL: insert into User (password,email,username,id) values (?,?,?,?)
ARGS: ['my-pwd', '[email protected]', 'Michael', 12345]
可以看到,save()方法已经打印出了可执行的SQL语句,以及参数列表,只需要真正连接到数据库,执行该SQL语句,就可以完成真正的功能。
不到100行代码,我们就通过metaclass实现了一个精简的ORM框架
类默认是由 type 类实例化产生,type类中如何实现的创建类?类又是如何创建对象?
答:类中有一个属性 __metaclass__,其用来表示该类由 谁 来实例化创建,所以,我们可以为 __metaclass__ 设置一个type类的派生类,从而查看 类 创建的过程。
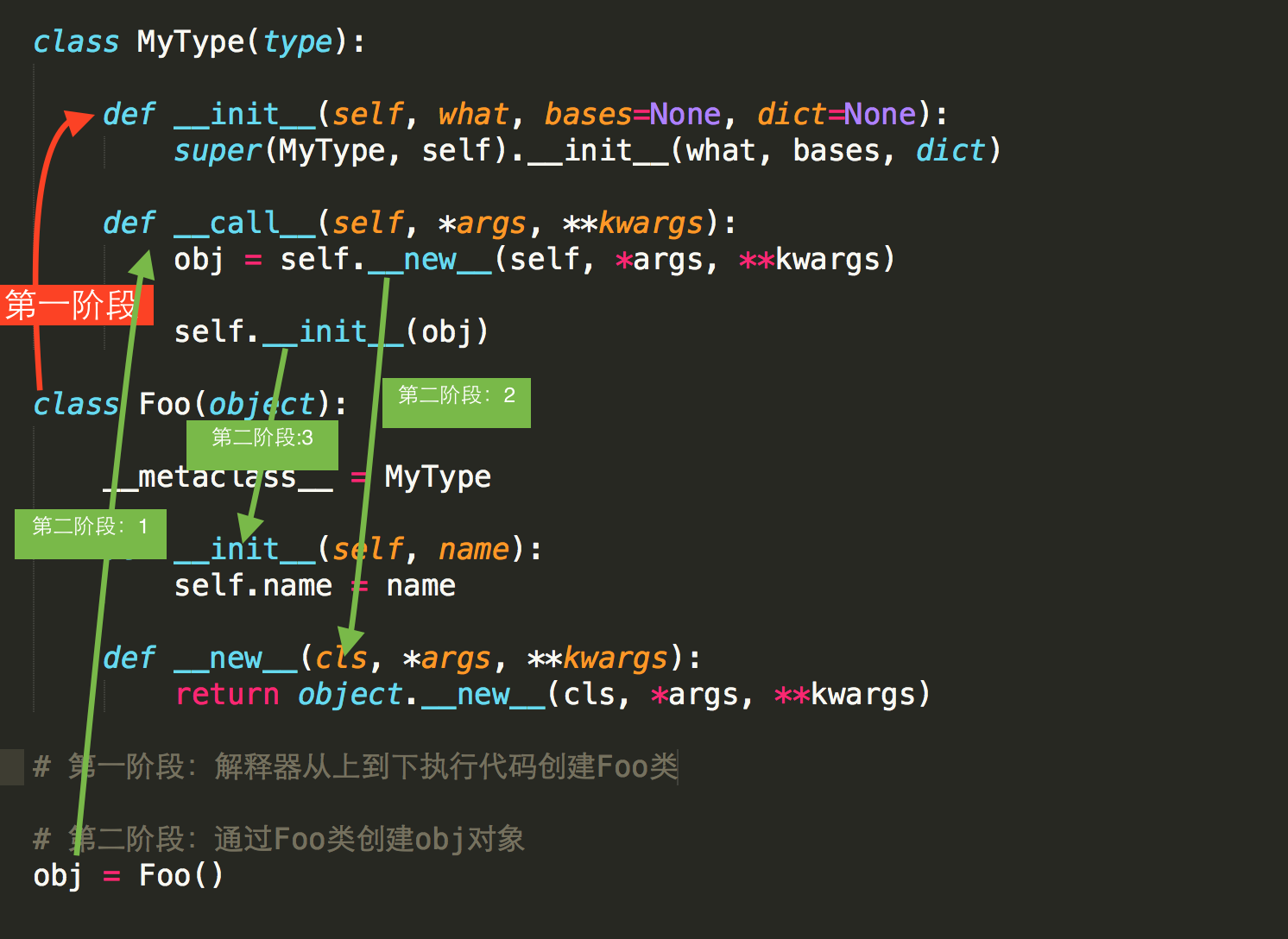
1 class MyType(type):
2 def __init__(self,*args,**kwargs):
3
4 print("Mytype __init__",*args,**kwargs)
5
6 def __call__(self, *args, **kwargs):
7 print("Mytype __call__", *args, **kwargs)
8 obj = self.__new__(self)
9 print("obj ",obj,*args, **kwargs)
10 print(self)
11 self.__init__(obj,*args, **kwargs)
12 return obj
13
14 def __new__(cls, *args, **kwargs):
15 print("Mytype __new__",*args,**kwargs)
16 return type.__new__(cls, *args, **kwargs)
17
18 print('here...')
19 class Foo(object,metaclass=MyType):
20
21
22 def __init__(self,name):
23 self.name = name
24
25 print("Foo __init__")
26
27 def __new__(cls, *args, **kwargs):
28 print("Foo __new__",cls, *args, **kwargs)
29 return object.__new__(cls)
30
31 f = Foo("Alex")
32 print("f",f)
33 print("fname",f.name)
类的生成 调用 顺序依次是 __new__ --> __init__ --> __call__
metaclass 详解文章:http://stackoverflow.com/questions/100003/what-is-a-metaclass-in-python 得票最高那个答案写的非常好
Classes as objects
Before understanding metaclasses, you need to master classes in Python. And Python has a very peculiar idea of what classes are, borrowed from the Smalltalk language.
In most languages, classes are just pieces of code that describe how to produce an object. That's kinda true in Python too:
>>> class ObjectCreator(object):
... pass
...
>>> my_object = ObjectCreator()
>>> print(my_object)
<__main__.ObjectCreator object at 0x8974f2c>But classes are more than that in Python. Classes are objects too.
Yes, objects.
As soon as you use the keyword class, Python executes it and creates an OBJECT. The instruction
>>> class ObjectCreator(object):
... pass
...creates in memory an object with the name "ObjectCreator".
This object (the class) is itself capable of creating objects (the instances), and this is why it's a class.
But still, it's an object, and therefore:
- you can assign it to a variable
- you can copy it
- you can add attributes to it
- you can pass it as a function parameter
e.g.:
>>> print(ObjectCreator) # you can print a class because it's an object
<class '__main__.ObjectCreator'>
>>> def echo(o):
... print(o)
...
>>> echo(ObjectCreator) # you can pass a class as a parameter
<class '__main__.ObjectCreator'>
>>> print(hasattr(ObjectCreator, 'new_attribute'))
False
>>> ObjectCreator.new_attribute = 'foo' # you can add attributes to a class
>>> print(hasattr(ObjectCreator, 'new_attribute'))
True
>>> print(ObjectCreator.new_attribute)
foo
>>> ObjectCreatorMirror = ObjectCreator # you can assign a class to a variable
>>> print(ObjectCreatorMirror.new_attribute)
foo
>>> print(ObjectCreatorMirror())
<__main__.ObjectCreator object at 0x8997b4c>Creating classes dynamically
Since classes are objects, you can create them on the fly, like any object.
First, you can create a class in a function using class:
>>> def choose_class(name):
... if name == 'foo':
... class Foo(object):
... pass
... return Foo # return the class, not an instance
... else:
... class Bar(object):
... pass
... return Bar
...
>>> MyClass = choose_class('foo')
>>> print(MyClass) # the function returns a class, not an instance
<class '__main__.Foo'>
>>> print(MyClass()) # you can create an object from this class
<__main__.Foo object at 0x89c6d4c>But it's not so dynamic, since you still have to write the whole class yourself.
Since classes are objects, they must be generated by something.
When you use the class keyword, Python creates this object automatically. But as with most things in Python, it gives you a way to do it manually.
Remember the function type? The good old function that lets you know what type an object is:
>>> print(type(1))
<type 'int'>
>>> print(type("1"))
<type 'str'>
>>> print(type(ObjectCreator))
<type 'type'>
>>> print(type(ObjectCreator()))
<class '__main__.ObjectCreator'>Well, type has a completely different ability, it can also create classes on the fly. type can take the description of a class as parameters, and return a class.
(I know, it's silly that the same function can have two completely different uses according to the parameters you pass to it. It's an issue due to backwards compatibility in Python)
type works this way:
type(name of the class,
tuple of the parent class (for inheritance, can be empty),
dictionary containing attributes names and values)e.g.:
>>> class MyShinyClass(object):
... passcan be created manually this way:
>>> MyShinyClass = type('MyShinyClass', (), {}) # returns a class object
>>> print(MyShinyClass)
<class '__main__.MyShinyClass'>
>>> print(MyShinyClass()) # create an instance with the class
<__main__.MyShinyClass object at 0x8997cec>You'll notice that we use "MyShinyClass" as the name of the class and as the variable to hold the class reference. They can be different, but there is no reason to complicate things.
type accepts a dictionary to define the attributes of the class. So:
>>> class Foo(object):
... bar = TrueCan be translated to:
>>> Foo = type('Foo', (), {'bar':True})And used as a normal class:
>>> print(Foo)
<class '__main__.Foo'>
>>> print(Foo.bar)
True
>>> f = Foo()
>>> print(f)
<__main__.Foo object at 0x8a9b84c>
>>> print(f.bar)
TrueAnd of course, you can inherit from it, so:
>>> class FooChild(Foo):
... passwould be:
>>> FooChild = type('FooChild', (Foo,), {})
>>> print(FooChild)
<class '__main__.FooChild'>
>>> print(FooChild.bar) # bar is inherited from Foo
TrueEventually you'll want to add methods to your class. Just define a function with the proper signature and assign it as an attribute.
>>> def echo_bar(self):
... print(self.bar)
...
>>> FooChild = type('FooChild', (Foo,), {'echo_bar': echo_bar})
>>> hasattr(Foo, 'echo_bar')
False
>>> hasattr(FooChild, 'echo_bar')
True
>>> my_foo = FooChild()
>>> my_foo.echo_bar()
TrueAnd you can add even more methods after you dynamically create the class, just like adding methods to a normally created class object.
>>> def echo_bar_more(self):
... print('yet another method')
...
>>> FooChild.echo_bar_more = echo_bar_more
>>> hasattr(FooChild, 'echo_bar_more')
TrueYou see where we are going: in Python, classes are objects, and you can create a class on the fly, dynamically.
This is what Python does when you use the keyword class, and it does so by using a metaclass.
What are metaclasses (finally)
Metaclasses are the 'stuff' that creates classes.
You define classes in order to create objects, right?
But we learned that Python classes are objects.
Well, metaclasses are what create these objects. They are the classes' classes, you can picture them this way:
MyClass = MetaClass()
my_object = MyClass()You've seen that type lets you do something like this:
MyClass = type('MyClass', (), {})It's because the function type is in fact a metaclass. type is the metaclass Python uses to create all classes behind the scenes.
Now you wonder why the heck is it written in lowercase, and not Type?
Well, I guess it's a matter of consistency with str, the class that creates strings objects, and int the class that creates integer objects. type is just the class that creates class objects.
You see that by checking the __class__ attribute.
Everything, and I mean everything, is an object in Python. That includes ints, strings, functions and classes. All of them are objects. And all of them have been created from a class:
>>> age = 35
>>> age.__class__
<type 'int'>
>>> name = 'bob'
>>> name.__class__
<type 'str'>
>>> def foo(): pass
>>> foo.__class__
<type 'function'>
>>> class Bar(object): pass
>>> b = Bar()
>>> b.__class__
<class '__main__.Bar'>Now, what is the __class__ of any __class__ ?
>>> age.__class__.__class__
<type 'type'>
>>> name.__class__.__class__
<type 'type'>
>>> foo.__class__.__class__
<type 'type'>
>>> b.__class__.__class__
<type 'type'>So, a metaclass is just the stuff that creates class objects.
You can call it a 'class factory' if you wish.
type is the built-in metaclass Python uses, but of course, you can create your own metaclass.
The __metaclass__ attribute
You can add a __metaclass__ attribute when you write a class:
class Foo(object):
__metaclass__ = something...
[...]If you do so, Python will use the metaclass to create the class Foo.
Careful, it's tricky.
You write class Foo(object) first, but the class object Foo is not created in memory yet.
Python will look for __metaclass__ in the class definition. If it finds it, it will use it to create the object class Foo. If it doesn't, it will use type to create the class.
Read that several times.
When you do:
class Foo(Bar):
passPython does the following:
Is there a __metaclass__ attribute in Foo?
If yes, create in memory a class object (I said a class object, stay with me here), with the name Foo by using what is in __metaclass__.
If Python can't find __metaclass__, it will look for a __metaclass__ at the MODULE level, and try to do the same (but only for classes that don't inherit anything, basically old-style classes).
Then if it can't find any __metaclass__ at all, it will use the Bar's (the first parent) own metaclass (which might be the default type) to create the class object.
Be careful here that the __metaclass__ attribute will not be inherited, the metaclass of the parent (Bar.__class__) will be. If Bar used a __metaclass__ attribute that created Bar with type() (and not type.__new__()), the subclasses will not inherit that behavior.
Now the big question is, what can you put in __metaclass__ ?
The answer is: something that can create a class.
And what can create a class? type, or anything that subclasses or uses it.
Custom metaclasses
The main purpose of a metaclass is to change the class automatically, when it's created.
You usually do this for APIs, where you want to create classes matching the current context.
Imagine a stupid example, where you decide that all classes in your module should have their attributes written in uppercase. There are several ways to do this, but one way is to set __metaclass__ at the module level.
This way, all classes of this module will be created using this metaclass, and we just have to tell the metaclass to turn all attributes to uppercase.
Luckily, __metaclass__ can actually be any callable, it doesn't need to be a formal class (I know, something with 'class' in its name doesn't need to be a class, go figure... but it's helpful).
So we will start with a simple example, by using a function.
# the metaclass will automatically get passed the same argument
# that you usually pass to `type`
def upper_attr(future_class_name, future_class_parents, future_class_attr):
"""
Return a class object, with the list of its attribute turned
into uppercase.
"""
# pick up any attribute that doesn't start with '__' and uppercase it
uppercase_attr = {}
for name, val in future_class_attr.items():
if not name.startswith('__'):
uppercase_attr[name.upper()] = val
else:
uppercase_attr[name] = val
# let `type` do the class creation
return type(future_class_name, future_class_parents, uppercase_attr)
__metaclass__ = upper_attr # this will affect all classes in the module
class Foo(): # global __metaclass__ won't work with "object" though
# but we can define __metaclass__ here instead to affect only this class
# and this will work with "object" children
bar = 'bip'
print(hasattr(Foo, 'bar'))
# Out: False
print(hasattr(Foo, 'BAR'))
# Out: True
f = Foo()
print(f.BAR)
# Out: 'bip'Now, let's do exactly the same, but using a real class for a metaclass:
# remember that `type` is actually a class like `str` and `int`
# so you can inherit from it
class UpperAttrMetaclass(type):
# __new__ is the method called before __init__
# it's the method that creates the object and returns it
# while __init__ just initializes the object passed as parameter
# you rarely use __new__, except when you want to control how the object
# is created.
# here the created object is the class, and we want to customize it
# so we override __new__
# you can do some stuff in __init__ too if you wish
# some advanced use involves overriding __call__ as well, but we won't
# see this
def __new__(upperattr_metaclass, future_class_name,
future_class_parents, future_class_attr):
uppercase_attr = {}
for name, val in future_class_attr.items():
if not name.startswith('__'):
uppercase_attr[name.upper()] = val
else:
uppercase_attr[name] = val
return type(future_class_name, future_class_parents, uppercase_attr)But this is not really OOP. We call type directly and we don't override or call the parent __new__. Let's do it:
class UpperAttrMetaclass(type):
def __new__(upperattr_metaclass, future_class_name,
future_class_parents, future_class_attr):
uppercase_attr = {}
for name, val in future_class_attr.items():
if not name.startswith('__'):
uppercase_attr[name.upper()] = val
else:
uppercase_attr[name] = val
# reuse the type.__new__ method
# this is basic OOP, nothing magic in there
return type.__new__(upperattr_metaclass, future_class_name,
future_class_parents, uppercase_attr)You may have noticed the extra argument upperattr_metaclass. There is nothing special about it: __new__ always receives the class it's defined in, as first parameter. Just like you have self for ordinary methods which receive the instance as first parameter, or the defining class for class methods.
Of course, the names I used here are long for the sake of clarity, but like for self, all the arguments have conventional names. So a real production metaclass would look like this:
class UpperAttrMetaclass(type):
def __new__(cls, clsname, bases, dct):
uppercase_attr = {}
for name, val in dct.items():
if not name.startswith('__'):
uppercase_attr[name.upper()] = val
else:
uppercase_attr[name] = val
return type.__new__(cls, clsname, bases, uppercase_attr)We can make it even cleaner by using super, which will ease inheritance (because yes, you can have metaclasses, inheriting from metaclasses, inheriting from type):
class UpperAttrMetaclass(type):
def __new__(cls, clsname, bases, dct):
uppercase_attr = {}
for name, val in dct.items():
if not name.startswith('__'):
uppercase_attr[name.upper()] = val
else:
uppercase_attr[name] = val
return super(UpperAttrMetaclass, cls).__new__(cls, clsname, bases, uppercase_attr)That's it. There is really nothing more about metaclasses.
The reason behind the complexity of the code using metaclasses is not because of metaclasses, it's because you usually use metaclasses to do twisted stuff relying on introspection, manipulating inheritance, vars such as __dict__, etc.
Indeed, metaclasses are especially useful to do black magic, and therefore complicated stuff. But by themselves, they are simple:
- intercept a class creation
- modify the class
- return the modified class
Why would you use metaclasses classes instead of functions?
Since __metaclass__ can accept any callable, why would you use a class since it's obviously more complicated?
There are several reasons to do so:
- The intention is clear. When you read
UpperAttrMetaclass(type), you know what's going to follow - You can use OOP. Metaclass can inherit from metaclass, override parent methods. Metaclasses can even use metaclasses.
- Subclasses of a class will be instances of its metaclass if you specified a metaclass-class, but not with a metaclass-function.
- You can structure your code better. You never use metaclasses for something as trivial as the above example. It's usually for something complicated. Having the ability to make several methods and group them in one class is very useful to make the code easier to read.
- You can hook on
__new__,__init__and__call__. Which will allow you to do different stuff. Even if usually you can do it all in__new__, some people are just more comfortable using__init__. - These are called metaclasses, damn it! It must mean something!
Why would you use metaclasses?
Now the big question. Why would you use some obscure error prone feature?
Well, usually you don't:
Metaclasses are deeper magic that 99% of users should never worry about. If you wonder whether you need them, you don't (the people who actually need them know with certainty that they need them, and don't need an explanation about why).
Python Guru Tim Peters
The main use case for a metaclass is creating an API. A typical example of this is the Django ORM.
It allows you to define something like this:
class Person(models.Model):
name = models.CharField(max_length=30)
age = models.IntegerField()But if you do this:
guy = Person(name='bob', age='35')
print(guy.age)It won't return an IntegerField object. It will return an int, and can even take it directly from the database.
This is possible because models.Model defines __metaclass__ and it uses some magic that will turn the Person you just defined with simple statements into a complex hook to a database field.
Django makes something complex look simple by exposing a simple API and using metaclasses, recreating code from this API to do the real job behind the scenes.
The last word
First, you know that classes are objects that can create instances.
Well in fact, classes are themselves instances. Of metaclasses.
>>> class Foo(object): pass
>>> id(Foo)
142630324Everything is an object in Python, and they are all either instances of classes or instances of metaclasses.
Except for type.
type is actually its own metaclass. This is not something you could reproduce in pure Python, and is done by cheating a little bit at the implementation level.
Secondly, metaclasses are complicated. You may not want to use them for very simple class alterations. You can change classes by using two different techniques:
- monkey patching
- class decorators
99% of the time you need class alteration, you are better off using these.
But 98% of the time, you don't need class alteration at all.