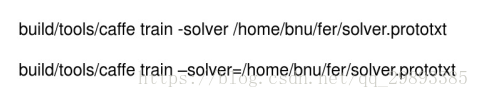一、准备数据
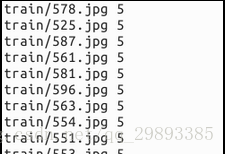
1.得到文件列表清单

2.转换成Lmdb格式
在caffe中经常使用的数据类型是lmdb或leveldb,因此需要将原始图片文件转化为能够运行的db文件。在caffe中存在convert_imageset.cpp,存放在根目录下的tools文件夹下。编译之后,生成对应的可执行文件放在 buile/tools/ 下面,这个文件的作用就是用于将图片文件转换成caffe框架中能直接使用的db文件。
命令调用格式:
convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME需要带四个参数:
FLAGS: 图片参数组,后面详细介绍
ROOTFOLDER/: 图片存放的绝对路径,从linux系统根目录开始
LISTFILE: 图片文件列表清单,一般为一个txt文件,一行一张图片
DB_NAME: 最终生成的db文件存放目录
完整流程如下:
首先创建sh脚本文件
sudo gedit examples/images/create_lmdb.sh输入下面代码并保存
#!/usr/bin/en sh
DATA=examples/images
rm -rf $DATA/img_train_lmdb
build/tools/convert_imageset --shuffle \
--resize_height=256 --resize_width=256 \
/home/xxx/caffe/examples/images/ $DATA/train.txt $DATA/img_train_lmdb设置参数-shuffle,打乱图片顺序。设置参数-resize_height和-resize_width将所有图片尺寸都变为256*256.
/home/xxx/caffe/examples/images/ 为图片保存的绝对路径。
最后,运行这个脚本文件
sudo sh examples/images/create_lmdb.sh就会在examples/images/ 目录下生成一个名为 img_train_lmdb的文件夹,里面的文件就是我们需要的db文件了。
3.计算图片数据的均值
图片减去均值后,再进行训练和测试,会提高速度和精度。因此,一般在各种模型中都会有这个操作。
caffe中使用的均值数据格式是binaryproto。 caffe提供了一个计算均值的文件compute_image_mean.cpp,放在caffe根目录下的tools文件夹里面。编译后的可执行文件放在 build/tools/ 下面,直接调用即可。
sudo build/tools/compute_image_mean examples/mnist/mnist_train_lmdb examples/mnist/mean.binaryproto带两个参数:
第一个参数:examples/mnist/mnist_train_lmdb, 表示需要计算均值的数据,格式为lmdb的训练数据。
第二个参数:examples/mnist/mean.binaryproto, 计算出来的结果保存文件。
二、构建网络模型
要运行caffe,需要先创建一个模型(model),如比较常用的Lenet,Alex等, 而一个模型由多个屋(layer)构成,每一屋又由许多参数组成。所有的参数都定义在caffe.proto这个文件中。要熟练使用caffe,最重要的就是学会配置文件(prototxt)的编写。
层有很多种类型,比如Data,Convolution,Pooling等,层之间的数据流动是以Blobs的方式进行。
以LeNet为例进行说明
<span style="font-size:18px;">name: "LeNet"
layer {
name: "mnist" // name制定层的名称,不能有重复
type: "Data" // type指定层的类型
top: "data"
top: "label"
include { //include用于指定是训练阶段还是测试阶段
phase: TRAIN // 训练阶段
}
transform_param { //数据装换参数:
scale: 0.00390625 //对所有的图片归一化到0~1之间,也就是对输入数据全部乘以scale,0.0039= 1/256 //缩放
}
data_param {
source: "examples/mnist/mnist_train_lmdb" //lmdb数据来源
batch_size: 64 //批处理尺寸,每次训练采用的图片64张,min-batch
backend: LMDB //数据源格式
}
}
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST //测试阶段
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_test_lmdb" //测试数据图片路径
batch_size: 100
backend: LMDB
}
}
layer {
name: "conv1" //卷积神经网络的第一层,卷积层
type: "Convolution" //这层操作为卷积
bottom: "data" //这一层的前一层是data层
top: "conv1" //
param {
lr_mult: 1 //第一个表示权值学习率
}
param {
lr_mult: 2 //偏置项学习率
}
convolution_param {
num_output: 20 //定义输出特征图个数
kernel_size: 5 //定义卷积核(过滤器)大小
stride: 1 //指定滑动步长S
weight_filler { //权值初始化为xavier
type: "xavier"
}
bias_filler { //初始化偏置项为常数0
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling" //池化层,这一层的操作为池化
bottom: "conv1" //这一层的前面一层名字为:conv1
top: "pool1"
pooling_param {
pool: MAX //采用最大值池化
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "ip1" //全连接层
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1" //激活层
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "accuracy" //输出分类精确度
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss" //Loss层,输出残差
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}</span>三、编写配置文件
solver算是caffe的核心的核心,它协调着整个模型的运作。caffe程序运行必带的一个参数就是solver配置文件。
实例如下:
net: "examples/mnist/lenet_train_test.prototxt" //指定网络结构文件
test_iter: 100 //验证迭代次数
test_interval: 500 //验证间隔
base_lr: 0.01 //基础学习率
momentum: 0.9 //动量
type: SGD //solver优化方法
weight_decay: 0.0005 //权值衰减系数
lr_policy: "inv" // 学习率变化规则
gamma: 0.0001 //学习率变化系数
power: 0.75 //学习率变化系数
display: 100 //屏幕显示间隔
max_iter: 20000 //最大迭代次数
snapshot: 5000 //快照,即Model保存间隔
snapshot_prefix: "examples/mnist/lenet" //Model名字前缀
solver_mode: CPU //硬件配置注意:以上的所有参数都是可选参数,都有默认值。根据solver方法(type)的不同,还有一些其它的参数,在此不一一列举。
四、训练模型
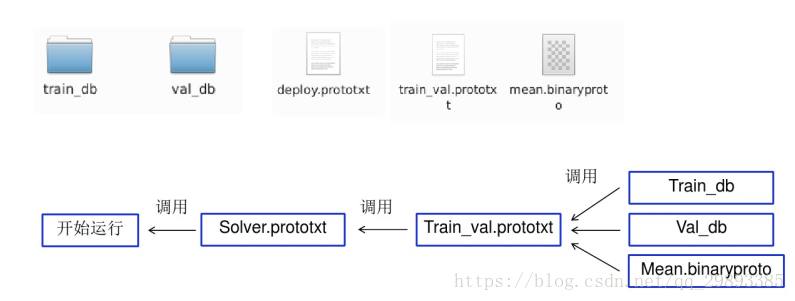
caffe的运行提供三种接口:c++接口(命令行)、python接口和matlab接口。
caffe的c++主程序(caffe.cpp)放在根目录下的tools文件夹内, 当然还有一些其它的功能文件,如:convert_imageset.cpp, train_net.cpp, test_net.cpp等也放在这个文件夹内。经过编译后,这些文件都被编译成了可执行文件,放在了 ./build/tools/ 文件夹内。因此我们要执行caffe程序,都需要加 ./build/tools/ 前缀。
caffe程序的命令行执行格式如下:
caffe <command> <args>| 其中的<command>有这样4种 train----训练或finetune模型(model), test-----测试模型 device_query---显示gpu信息 time-----显示程序执行时间 其中的<args>参数有: |
|
例如: