1. 前言
1.1 Caffe结构简单梳理
在之前的文章(Caffe源码整体结构及介绍)中介绍了Caffe中的一些重要的组件:
1)Blob 主要用来表示网络中的数据,包括训练数据,网络各层自身的参数(包括权值、偏置以及它们的梯度),网络之间传递的数据都是通过 Blob 来实现的,同时 Blob 数据也支持在 CPU 与 GPU 上存储,能够在两者之间做同步。
2)Layer 是对神经网络中各种层的一个抽象,包括我们熟知的卷积层和下采样层,还有全连接层和各种激活函数层等等。同时每种 Layer 都实现了前向传播和反向传播,并通过 Blob 来传递数据。
3)Net 是对整个网络的表示,由各种 Layer 前后连接组合而成,也是我们所构建的网络模型。
4)Solver 定义了针对 Net 网络模型的求解方法,记录网络的训练过程,保存网络模型参数,中断并恢复网络的训练过程。自定义 Solver 能够实现不同的网络求解方式。
通过去看对应模块的代码能够知道每个模块里面是怎么运作的,但是这些模块并不是单独的个体,在训练过程中是相互结合的,这里就以一个网络的训练为例子,看看整个训练的流程是什么样子的,是如何将这些单独的模块串联起来的。
cd $CAFFE_ROOT
./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt
1.2 训练的总体流程
这里主要介绍Caffe中进行训练的流程,下面是调用Caffe中的训练函数之后发生的事情的大体流程:
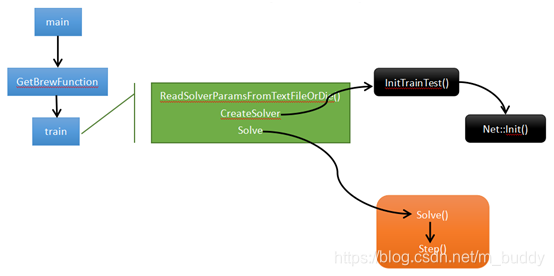
2. 训练流程的初始化
2.1 训练的入口main函数
Caffe中启动训练也是需要调用程序入口main()函数的,下面是经过简略保留关键函数调用GetBrewFunction()的main结构:PS:其中的......代表相关代码的省略
int main(int argc, char** argv) {
......
return GetBrewFunction(caffe::string(argv[1]))();
......
}
上面的GetBrewFunction()函数中是通过指定的命令名称找到对应的函数指针进行回调的,对应的存储结构是std::map类型,变量为g_brew_map,也就是一个注册器。首先对于g_brew_map的定义:
typedef int (*BrewFunction)();
typedef std::map<caffe::string, BrewFunction> BrewMap;
BrewMap g_brew_map;
g_brew_map是一个key为std::string类型,value为BrewFunction类型的一个map类型的全局变量,而BrewFunction是一个函数指针类型,它指向的是参数为空,返回值为int的函数,也就是train、test、time、device_query这四个函数的类型。g_brew_map本质是一个容器。
注册器具体定义为一个宏
#define RegisterBrewFunction(func) \
namespace { \
class __Registerer_##func { \
public: /* NOLINT */ \
__Registerer_##func() {
\
g_brew_map[#func] = &func; \
} \
}; \
__Registerer_##func g_registerer_##func; \
}”
具体g_brew_map实现过程(回调过程),首先通过typedef定义函数指针 typedef int (*BrewFunction)(); 这个是用typedef定义函数指针方法。这个程序定义一个BrewFunction函数指针类型,在caffe.cpp中BrewFunction作为GetBrewFunction()函数的返回类型,可以是train(),test(),device_query(),time()这四个函数指针的其中一个。在train(),test(),中可以调用solver类的函数,从而进入到net,进入到每一层,运行整个Caffe程序。然后对每个函数注册。
下面这几个是原本caffe.cpp文件中注册了的几个函数:
RegisterBrewFunction(train)
RegisterBrewFunction(test)
RegisterBrewFunction(device_query)
RegisterBrewFunction(time)
1)train: 训练或者调整一个模型;
2)test: 在测试集上测试一个模型;
3)device_query: 打印GPU的调试信息;
4)time: 压测一个模型的执行时间,包含前向和后向传播中各层的运行时间;
如果需要,可以增加其他的方式,然后通过RegisterBrewFunction()函数注册一下即可。
GetBrewFunction()函数通过指定参数,传入”train”参数就会通过键值对调用train()函数,train函数中主要有三个方法ReadSolverParamsFromTextFileOrDie、CreateSolver、Solve,分别代表的是从文件加载训练网络的相关参数,创建solver以及求解网络的过程。
// Train / Finetune a model.
int train() {
......
caffe::SolverParameter solver_param;
caffe::ReadSolverParamsFromTextFileOrDie(FLAGS_solver, &solver_param);//从-solver参数读取solver_param
......
shared_ptr<caffe::Solver<float> >
solver(caffe::SolverRegistry<float>::CreateSolver(solver_param));//从参数创建solver,同样采用string到函数指针的映射实现,用到了工厂模式
if (FLAGS_snapshot.size()) {
//迭代snapshot次后保存模型一次
LOG(INFO) << "Resuming from " << FLAGS_snapshot;
solver->Restore(FLAGS_snapshot.c_str());
} else if (FLAGS_weights.size()) {
//若采用finetuning,则拷贝weight到指定模型
CopyLayers(solver.get(), FLAGS_weights);
}
if (gpus.size() > 1) {
caffe::P2PSync<float> sync(solver, NULL, solver->param());
sync.Run(gpus);
} else {
LOG(INFO) << "Starting Optimization";
solver->Solve();//开始训练网络
}
LOG(INFO) << "Optimization Done.";
return 0;
}
其中的调用caffe::ReadSolverParamsFromTextFileOrDie(FLAGS_solver, &solver_param)解析-solver指定的solver.prototxt的文件内容到solver_param中用于后序创建solver。
2.2 SolverParameter的具体解析过程
上面代码中的SolverParameter是通过ReadSolverParamsFromTextFileOrDie()来完成解析的,这个函数的实现在/CAFFE_ROOT/src/caffe/util/upgrade_proto.cpp里,我们来看一下具体的过程:
// Read parameters from a file into a SolverParameter proto message.
void ReadSolverParamsFromTextFileOrDie(const string& param_file,
SolverParameter* param) {
CHECK(ReadProtoFromTextFile(param_file, param))
<< "Failed to parse SolverParameter file: " << param_file;
UpgradeSolverAsNeeded(param_file, param);
}
这里调用了先后调用了两个函数,首先是ReadProtoFromTextFile,这个函数的作用是从param_file这个路径去读取solver的定义,并将文件中的内容解析存到param这个指针指向的对象,具体的实现在/CAFFE_ROOT/src/caffe/util/io.cpp的开始:
bool ReadProtoFromTextFile(const char* filename, Message* proto) {
int fd = open(filename, O_RDONLY);
CHECK_NE(fd, -1) << "File not found: " << filename;
FileInputStream* input = new FileInputStream(fd);
bool success = google::protobuf::TextFormat::Parse(input, proto);
delete input;
close(fd);
return success;
}
这段代码首先是打开了文件,并且读取到了一个FileInputStream的指针中,然后通过protobuf的TextFormat::Parse函数完成了解析。
然后UpgradeSolverAsNeeded完成了新老版本caffe.proto的兼容处理:
// Check for deprecations and upgrade the SolverParameter as needed.
bool UpgradeSolverAsNeeded(const string& param_file, SolverParameter* param) {
bool success = true;
// Try to upgrade old style solver_type enum fields into new string type
if (SolverNeedsTypeUpgrade(*param)) {
LOG(INFO) << "Attempting to upgrade input file specified using deprecated "
<< "'solver_type' field (enum)': " << param_file;
if (!UpgradeSolverType(param)) {
success = false;
LOG(ERROR) << "Warning: had one or more problems upgrading "
<< "SolverType (see above).";
} else {
LOG(INFO) << "Successfully upgraded file specified using deprecated "
<< "'solver_type' field (enum) to 'type' field (string).";
LOG(WARNING) << "Note that future Caffe releases will only support "
<< "'type' field (string) for a solver's type.";
}
}
return success;
}
主要的问题就是在旧版本中Solver的type是enum类型,而新版本的变为了string。
2.3 Solver初始化
在上面train代码函数中使用如下代码进行solver的初始化工作,使用下面的代码用于初始化Solver和Net:
//从参数创建solver,同样采用string到函数指针的映射实现,用到了工厂模式
shared_ptr<caffe::Solver<float> >
solver(caffe::SolverRegistry<float>::CreateSolver(solver_param));
因为在caffe.proto文件中默认的优化type为SGD(Solver也是由工厂模式进行设计的,与Layer的设计具有想通之处),所以上面的代码会实例化一个SGDSolver的对象,SGDSolver类继承于Solver类,在新建SGDSolver对象时会调用其构造函数如下所示:
//sgd_solvers.hpp
explicit SGDSolver(const SolverParameter& param)
: Solver<Dtype>(param) {
PreSolve(); }
通过上面的代码,就掉用了基类Solver的构造函数:
template <typename Dtype>
Solver<Dtype>::Solver(const SolverParameter& param)
: net_(), callbacks_(), requested_early_exit_(false) {
Init(param);
}
在上面的代码中调用void Solver<Dtype>::Init(const SolverParameter& param),该函数内有InitTrainNet()、InitTestNets(),用于初始化训练和测试网络。对于其中过的InitTrainNet()函数(InitTestNets()类似的),在函数的尾部有构造训练网络Net的构造函数:
......
net_.reset(new Net<Dtype>(net_param));
2.4 Net初始化
调用Net类的构造函数,然后执行Init()操作,该函数具体的内容如下源码所示:PS:这部分代码仅供查阅,解析在其后
template <typename Dtype>
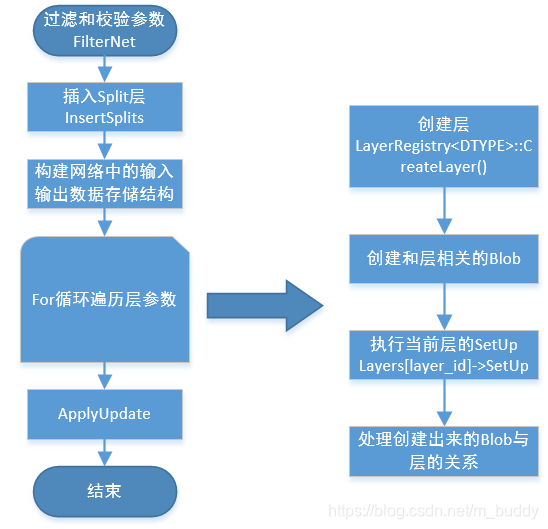
void Net<Dtype>::Init(const NetParameter& in_param) {
//过滤校验参数FilterNet
FilterNet(in_param, &filtered_param);
//插入Splits层
InsertSplits(filtered_param, ¶m);
// 构建网络中输入输出存储结构
bottom_vecs_.resize(param.layer_size());
top_vecs_.resize(param.layer_size());
bottom_id_vecs_.resize(param.layer_size());
param_id_vecs_.resize(param.layer_size());
top_id_vecs_.resize(param.layer_size());
bottom_need_backward_.resize(param.layer_size());
//创建层
for (int layer_id = 0; layer_id < param.layer_size(); ++layer_id) {
layers_.push_back(LayerRegistry<Dtype>::CreateLayer(layer_param));
layer_names_.push_back(layer_param.name());
LOG_IF(INFO, Caffe::root_solver())
<< "Creating Layer " << layer_param.name();
bool need_backward = false;
// Figure out this layer's input and output
for (int bottom_id = 0; bottom_id < layer_param.bottom_size();
++bottom_id) {
const int blob_id = AppendBottom(param, layer_id, bottom_id,
&available_blobs, &blob_name_to_idx);
//创建相关blob
Layer<Dtype>* layer = layers_[layer_id].get();
if (layer->AutoTopBlobs()) {
const int needed_num_top =
std::max(layer->MinTopBlobs(), layer->ExactNumTopBlobs());
for (; num_top < needed_num_top; ++num_top) {
// Add "anonymous" top blobs -- do not modify available_blobs or
// blob_name_to_idx as we don't want these blobs to be usable as input
// to other layers.
AppendTop(param, layer_id, num_top, NULL, NULL);
}
}
//执行SetUp()
// After this layer is connected, set it up.
layers_[layer_id]->SetUp(bottom_vecs_[layer_id], top_vecs_[layer_id]);
LOG_IF(INFO, Caffe::root_solver())
<< "Setting up " << layer_names_[layer_id];
for (int top_id = 0; top_id < top_vecs_[layer_id].size(); ++top_id) {
if (blob_loss_weights_.size() <= top_id_vecs_[layer_id][top_id]) {
blob_loss_weights_.resize(top_id_vecs_[layer_id][top_id] + 1, Dtype(0));
}
blob_loss_weights_[top_id_vecs_[layer_id][top_id]] = layer->loss(top_id);
LOG_IF(INFO, Caffe::root_solver())
<< "Top shape: " << top_vecs_[layer_id][top_id]->shape_string();
if (layer->loss(top_id)) {
LOG_IF(INFO, Caffe::root_solver())
<< " with loss weight " << layer->loss(top_id);
}
memory_used_ += top_vecs_[layer_id][top_id]->count();
}
LOG_IF(INFO, Caffe::root_solver())
<< "Memory required for data: " << memory_used_ * sizeof(Dtype);
const int param_size = layer_param.param_size();
const int num_param_blobs = layers_[layer_id]->blobs().size();
CHECK_LE(param_size, num_param_blobs)
<< "Too many params specified for layer " << layer_param.name();
ParamSpec default_param_spec;
for (int param_id = 0; param_id < num_param_blobs; ++param_id) {
const ParamSpec* param_spec = (param_id < param_size) ?
&layer_param.param(param_id) : &default_param_spec;
const bool param_need_backward = param_spec->lr_mult() != 0;
need_backward |= param_need_backward;
layers_[layer_id]->set_param_propagate_down(param_id,
param_need_backward);
}
for (int param_id = 0; param_id < num_param_blobs; ++param_id) {
AppendParam(param, layer_id, param_id);
}
// Finally, set the backward flag
layer_need_backward_.push_back(need_backward);
if (need_backward) {
for (int top_id = 0; top_id < top_id_vecs_[layer_id].size(); ++top_id) {
blob_need_backward_[top_id_vecs_[layer_id][top_id]] = true;
}
}
} //创建层完毕
//接下来的工作是要指定对于loss相关的blob,不仅要指定top_blob也要指定bottom_blob。
......
上面是net.cpp文件里Init()函数的主要内容(仅仅当做参考),其中LayerRegistry<Dtype>::CreateLayer(layer_param)主要是通过调用LayerRegistry这个类的静态成员函数CreateLayer得到一个指向Layer类的shared_ptr类型指针。并把每一层的指针存放在vector<shared_ptr<Layer<Dtype> > > layers_这个指针容器里。这里相当于根据每层的参数layer_param实例化了对应的各个子类层,比如conv_layer(卷积层)和pooling_layer(池化层)。实例化了各层就会调用每个层的构造函数,但每层的构造函数都没有做什么大的设置。
经过分析在Init()函数中主要由四部分组成:
1)AppendBottom: 设置每一层的输入数据
2)AppendTop: 设置每一层的输出数据
3)layers_[layer_id]->SetUp: 对上面设置的输入输出数据计算分配空间,并设置每层的可学习参数(权值和偏置),下面会详细降到这个函数
4)AppendParam: 对上面申请的可学习参数进行设置,主要包括学习率和正则率等。
//net.cpp Init()
for (int layer_id = 0; layer_id < param.layer_size(); ++layer_id)
{
//param是网络参数,layer_size()返回网络拥有的层数
const LayerParameter& layer_param = param.layer(layer_id);//获取当前layer的参数
layers_.push_back(LayerRegistry<Dtype>::CreateLayer(layer_param));//根据参数实例化layer
//下面的两个for循环将此layer的bottom blob的指针和top blob的指针放入bottom_vecs_和top_vecs_,bottom blob和top blob的实例全都存放在blobs_中。相邻的两层,前一层的top blob是后一层的bottom blob,所以blobs_的同一个blob既可能是bottom blob,也可能使top blob。
for (int bottom_id = 0; bottom_id < layer_param.bottom_size();++bottom_id) {
const int blob_id=AppendBottom(param,layer_id,bottom_id,&available_blobs,&blob_name_to_idx);
}
for (int top_id = 0; top_id < num_top; ++top_id) {
AppendTop(param, layer_id, top_id, &available_blobs, &blob_name_to_idx);
}
// 调用layer类的Setup函数进行初始化,输入参数:每个layer的输入blobs以及输出blobs,为每个blob设置大小
layers_[layer_id]->SetUp(bottom_vecs_[layer_id], top_vecs_[layer_id]);
//接下来的工作是将每层的parameter的指针塞进params_,尤其是learnable_params_。
const int num_param_blobs = layers_[layer_id]->blobs().size();
for (int param_id = 0; param_id < num_param_blobs; ++param_id) {
AppendParam(param, layer_id, param_id);
//AppendParam负责具体的dirtywork
}
}
经过上面的过程,Net类的初始化工作基本就完成了,接着我们具体来看看上面所说的layers_[layer_id]->SetUp对每一具体的层结构进行设置,我们来看看Layer类的Setup()函数,对每一层的设置主要由下面三个函数组成:
1)LayerSetUp(bottom, top):由Layer类派生出的特定类都需要重写这个函数,主要功能是设置权值参数(包括偏置)的空间以及对权值参数经行随机初始化。
2)Reshape(bottom, top):根据输出blob和权值参数计算输出blob的维数,并申请空间。
3)SetLossWeights(top):未涉及到损失更新的top blob设置损失权重。
在每个层创建过程中会调用SetUp()函数,那么SetUp是怎么构建的呢?
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
}
void SetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
InitMutex();
CheckBlobCounts(bottom, top);
LayerSetUp(bottom, top);
Reshape(bottom, top);
SetLossWeights(top);
}
2.5 总结
经过上述过程基本上就完成了初始化的工作,总体的流程大概就是新建一个Solver对象,然后调用Solver类的构造函数,然后在Solver的构造函数中又会新建Net类实例,在Net类的构造函数中又会新建各个Layer的实例,一直具体到设置每个Blob,大概就介绍完了网络初始化的工作,当然里面还有很多具体的细节,但大概的流程就是这样。
3. 网络权值初始化
在train()函数中在初始化完毕solver与net之后,随后完成的是网络中参数的初始化工作。对于有参数权值文件的情况,在函数内部对两个情况进行了判断,见下面的代码:
//caffe.cpp
if (FLAGS_snapshot.size()) {
LOG(INFO) << "Resuming from " << FLAGS_snapshot;
solver->Restore(FLAGS_snapshot.c_str()); //snapshot中恢复
} else if (FLAGS_weights.size()) {
CopyLayers(solver.get(), FLAGS_weights); //其它model中恢复,finetune
}
总的来讲Caffe的参数初始化方式有3中形式,除了上面说到的两种,还有一种就是无参数文件下的 “随机” 初始化方式了。
3.1 从snapshot中恢复
在上面调用Restore()函数会调用到下面的这段代码:
//solver.cpp
template <typename Dtype>
void Solver<Dtype>::Restore(const char* state_file) {
string state_filename(state_file);
if (state_filename.size() >= 3 &&
state_filename.compare(state_filename.size() - 3, 3, ".h5") == 0) {
RestoreSolverStateFromHDF5(state_filename);
} else {
RestoreSolverStateFromBinaryProto(state_filename);
}
}
上面的代码明确指明了支持的snapshot的类型:HDF5文件或是BinaryProto文件。走到这里就会调用两个对应权值加载方式,但是在solver.cpp中这两个函数是纯虚函数:
//solver.cpp
virtual void RestoreSolverStateFromHDF5(const string& state_file) = 0;
virtual void RestoreSolverStateFromBinaryProto(const string& state_file) = 0;
因而,具体的实现需要在后面派生出来的子类中去寻找,比如sgd_solver.cpp中对于BinaryProtobuf文件中参数的加载:
template <typename Dtype>
void SGDSolver<Dtype>::RestoreSolverStateFromBinaryProto(
const string& state_file) {
SolverState state;
ReadProtoFromBinaryFile(state_file, &state);
this->iter_ = state.iter();
if (state.has_learned_net()) {
NetParameter net_param;
ReadNetParamsFromBinaryFileOrDie(state.learned_net().c_str(), &net_param); //读取存储的参数
this->net_->CopyTrainedLayersFrom(net_param); //拷贝到当前网络
}
this->current_step_ = state.current_step();
CHECK_EQ(state.history_size(), history_.size())
<< "Incorrect length of history blobs.";
LOG(INFO) << "SGDSolver: restoring history";
for (int i = 0; i < history_.size(); ++i) {
history_[i]->FromProto(state.history(i));
}
}
3.2 从别的model文件中导入
从已经训练好的model文件中导入参数就没那么复杂了,其实现如下:
//caffe.cpp
void CopyLayers(caffe::Solver<float>* solver, const std::string& model_list) {
std::vector<std::string> model_names;
boost::split(model_names, model_list, boost::is_any_of(",") );
for (int i = 0; i < model_names.size(); ++i) {
LOG(INFO) << "Finetuning from " << model_names[i];
solver->net()->CopyTrainedLayersFrom(model_names[i]);
for (int j = 0; j < solver->test_nets().size(); ++j) {
solver->test_nets()[j]->CopyTrainedLayersFrom(model_names[i]);
}
}
}
它也是支持两种类型的权值文件导入的,传入模型文件名:
//net.cpp
template <typename Dtype>
void Net<Dtype>::CopyTrainedLayersFrom(const string trained_filename) {
if (H5Fis_hdf5(trained_filename.c_str())) {
CopyTrainedLayersFromHDF5(trained_filename);
} else {
CopyTrainedLayersFromBinaryProto(trained_filename);
}
}
3.3 使用设定的初始化方法填充
这里的网络参数初始化并没有使用一个已经有的权值文件,而是将参数使用一个分部去填充,从而开始网络训练。这里以卷积层的参数初始化作为例子进行说明。
在之前谈到的net创建过程中,net中的层是一个个层进行创建的(之前的内容2.4节中共有介绍)。在卷积层创建过程中也会执行LayerSetUp()函数
//base_conv_layer.cpp
template <typename Dtype>
void BaseConvolutionLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top)
在这个函数内部对应的权值初始化是调用如下的代码实现的
// base_conv_layer.cpp
// Initialize and fill the weights:
// output channels x input channels per-group x kernel height x kernel width
this->blobs_[0].reset(new Blob<Dtype>(weight_shape));
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.convolution_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get());
// If necessary, initialize and fill the biases.
if (bias_term_) {
this->blobs_[1].reset(new Blob<Dtype>(bias_shape));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.convolution_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
}
对应的分布如下:
// filter.hpp
template <typename Dtype>
Filler<Dtype>* GetFiller(const FillerParameter& param) {
const std::string& type = param.type();
if (type == "constant") {
return new ConstantFiller<Dtype>(param);
} else if (type == "gaussian") {
return new GaussianFiller<Dtype>(param);
} else if (type == "positive_unitball") {
return new PositiveUnitballFiller<Dtype>(param);
} else if (type == "uniform") {
return new UniformFiller<Dtype>(param);
} else if (type == "xavier") {
return new XavierFiller<Dtype>(param);
} else if (type == "msra") {
return new MSRAFiller<Dtype>(param);
} else if (type == "bilinear") {
return new BilinearFiller<Dtype>(param);
} else {
CHECK(false) << "Unknown filler name: " << param.type();
}
return (Filler<Dtype>*)(NULL);
}
4. 训练解算过程
4.1 解算的前期工作准备
上面介绍了网络初始化的大概流程,如上面所说的网络的初始化就是从下面一行代码新建一个solver指针开始一步一步的调用Solver,Net,Layer,Blob类的构造函数,完成整个网络的初始化。
//caffe.cpp
shared_ptr<caffe::Solver<float> > //初始化
solver(caffe::SolverRegistry<float>::CreateSolver(solver_param));
完成初始化之后,就可以开始对网络经行训练了,开始训练的代码如下所示,指向Solver类的指针solver开始调用Solver类的成员函数Solve()。
// 开始优化
solver->Solve();
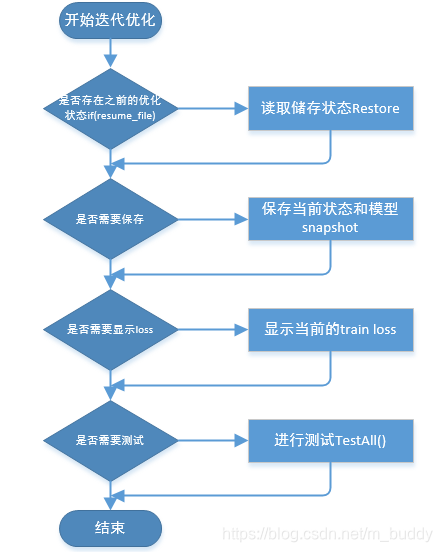
接下来我们来看看Solver类的成员函数Solve(),Solve函数其实主要就是调用了Solver的另一个成员函数Step()来完成实际的迭代训练过程。
//solver.cpp
template <typename Dtype>
void Solver<Dtype>::Solve(const char* resume_file) {
...
int start_iter = iter_;
...
// 然后调用了'Step'函数,这个函数执行了实际的逐步的迭代过程
Step(param_.max_iter() - iter_);
...
LOG(INFO) << "Optimization Done.";
}
下图是Solve()函数中所办事情的梳理为如下流程图:
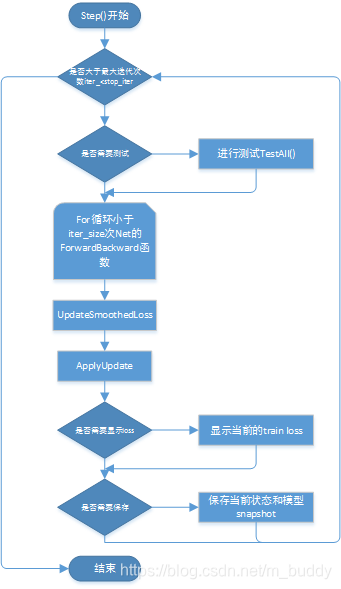
顺着来看看这个Step()函数的主要代码,首先是一个大循环设置了总的迭代次数,在每次迭代中训练iter_size x batch_size个样本,这个设置是为了在GPU的显存不够的时候使用,比如我本来想把batch_size设置为128,iter_size(可以在solver.prototxt里面指定)是默认为1的,但是会out_of_memory,借助这个方法,可以设置batch_size=32,iter_size=4,那实际上每次迭代还是处理了128个数据。
//solver.cpp
template <typename Dtype>
void Solver<Dtype>::Step(int iters) {
...
//迭代
while (iter_ < stop_iter) {
...
// iter_size也是在solver.prototxt里设置,实际上的batch_size=iter_size*网络定义里的batch_size,
// 因此每一次迭代的loss是iter_size次迭代的和,再除以iter_size,这个loss是通过调用`Net::ForwardBackward`函数得到的
// accumulate gradients over `iter_size` x `batch_size` instances
for (int i = 0; i < param_.iter_size(); ++i) {
/*
* 调用了Net中的代码,主要完成了前向后向的计算,
* 前向用于计算模型的最终输出和Loss,后向用于
* 计算每一层网络和参数的梯度。
*/
loss += net_->ForwardBackward();
}
...
/*
* 这个函数主要做Loss的平滑。由于Caffe的训练方式是SGD,我们无法把所有的数据同时
* 放入模型进行训练,那么部分数据产生的Loss就可能会和全样本的平均Loss不同,在必要
* 时候将Loss和历史过程中更新的Loss求平均就可以减少Loss的震荡问题。
*/
UpdateSmoothedLoss(loss, start_iter, average_loss);
...
// 执行梯度的更新,这个函数在基类`Solver`中没有实现,会调用每个子类自己的实现
//,后面具体分析`SGDSolver`的实现
ApplyUpdate();
// 迭代次数加1
++iter_;
...
}
}
上面Step()函数主要分为三部分:前向和反向传播、损失平滑和权值更新,在Step()函数中执行的梳理为下图所示:
4.2 前向和反向传播
loss += net_->ForwardBackward();
这行代码通过Net类的net_指针调用其成员函数ForwardBackward(),其代码如下所示,分别调用了成员函数Forward(&loss)和成员函数Backward()来进行前向传播和反向传播。
// net.hpp
// 进行一次正向传播,一次反向传播
Dtype ForwardBackward() {
Dtype loss;
Forward(&loss);
Backward();
return loss;
}
前面的Forward(&loss)函数最终会执行到下面一段代码,Net类的Forward()函数会对网络中的每一层执行Layer类的成员函数Forward(),而具体的每一层Layer的派生类会重写Forward()函数来实现不同层的前向计算功能。上面的Backward()反向求导函数也和Forward()类似,调用不同层的Backward()函数来计算每层的梯度。
//net.cpp
for (int i = start; i <= end; ++i) {
// 对每一层进行前向计算,返回每层的loss,其实只有最后一层loss不为0
Dtype layer_loss = layers_[i]->Forward(bottom_vecs_[i], top_vecs_[i]);
loss += layer_loss;
if (debug_info_) {
ForwardDebugInfo(i); }
}
4.3 损失平滑
UpdateSmoothedLoss();这个函数主要做Loss的平滑。由于Caffe的训练方式是SGD,我们无法把所有的数据同时放入模型进行训练,那么部分数据产生的Loss就可能会和全样本的平均Loss不同,在必要时候将Loss和历史过程中更新的Loss求平均就可以减少Loss的震荡问题
4.4 权值更新
ApplyUpdate();这个函数是Solver类的纯虚函数,需要派生类来实现,比如SGDSolver类实现的ApplyUpdate();函数如下,主要内容包括:设置参数的学习率;对梯度进行Normalize;对反向求导得到的梯度添加正则项的梯度;最后根据SGD算法计算最终的梯度;最后的最后把计算得到的最终梯度对权值进行更新。
template <typename Dtype>
void SGDSolver<Dtype>::ApplyUpdate() {
CHECK(Caffe::root_solver());
// GetLearningRate根据设置的lr_policy来计算当前迭代的learning rate的值
Dtype rate = GetLearningRate();
// 判断是否需要输出当前的learning rate
if (this->param_.display() && this->iter_ % this->param_.display() == 0) {
LOG(INFO) << "Iteration " << this->iter_ << ", lr = " << rate;
}
// 避免梯度爆炸,如果梯度的二范数超过了某个数值则进行scale操作,将梯度减小
ClipGradients();
// 对所有可更新的网络参数进行操作
for (int param_id = 0; param_id < this->net_->learnable_params().size();
++param_id) {
// 将第param_id个参数的梯度除以iter_size,
// 这一步的作用是保证实际的batch_size=iter_size*设置的batch_size
Normalize(param_id);
// 将正则化部分的梯度降入到每个参数的梯度中
Regularize(param_id);
// 计算SGD算法的梯度(momentum等)
ComputeUpdateValue(param_id, rate);
}
// 调用`Net::Update`更新所有的参数
this->net_->Update();
}
等进行了所有的循环,网络的训练也算是完成了。上面大概说了下使用Caffe进行网络训练时网络初始化以及前向传播、反向传播、梯度更新的过程,其中省略了大量的细节。上面还有很多东西都没提到,比如说Caffe中Layer派生类的注册及各个具体层前向反向的实现、Solver派生类的注册、网络结构的读取、模型的保存等等大量内容。