一、正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。我们可以使用grep、sed、awk命令来测试我们的正则表达式。
二、grep、sed、awk文本处理工具
1.grep
- grep概述
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
用法:
-E ##扩展正则表达式
grep root passwd ##模糊过滤root字符
grep -E "\<root" passwd ##模糊过滤以root开头的字符
grep -E "\<root\>" passwd ##精确过滤以root字符
grep -E -i "\<root\>" passwd ##忽略大小写过滤root字符
grep -E -i "^\<root\>" passwd ##忽略大小写过滤以root字符开头的行
grep -E -i "\<root\>$" passwd ##忽略大小写过滤以root字符结尾的行
grep -E "root|ROOT" passwd ##模糊过滤root和ROOT字符
grep ^root passwd ##过滤以root开头的行

vim passwd
grep root$ passwd ##过滤以root结尾的行
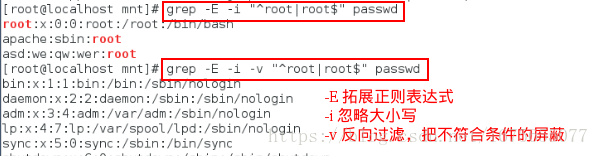
grep -E -i "^root|root$" passwd ##过滤以root开头或者以root结尾的行
grep -E -i -v "^root|root$" passwd ##过滤以root开头或者以root结尾以外的行
grep -E -i -v "^root|root$" passwd | grep root ##过滤root在中间的行
ps:egrep与grep -E 效果相同

grep -E 'x...y' test ##过滤r和t中间有三个任意字符,.表示任意字符出现的次数
grep -E 'xo*y' ##o出现0到任意次
grep -E 'xo\?y' ##o出现0到1次
\+ ##字符出现 [1- 任意次 ]
\{n\} ##字符出现 [n 次 ]
|{m,n\} ##字符出现 [ 最少出现 m 次,最多出现 n 次 ]
\{0,n\} ##字符出现 [0-n 次 ]
\{m,\} ##字符出现 [ 至少 m 次 ]
\(xy\)\{n\}xy ##关键字出现 [n 次 ]
.* ##关键字之间匹配任意字符实验:
vim westos ##编辑测试文件




关键参数:
^ 关键字 ##关键字开头
关键字 $ ##关键字结尾
\<关键字 ##关键字结尾不扩展
关键字\> ##关键字开头不进行扩展
\<关键字\> ##精确匹配关键字[root@localhost mnt]# ifconfig eth0 | grep inet 过滤inet行
inet 172.25.254.168 netmask 255.255.255.0 broadcast 172.25.254.255
inet6 fe80::5054:ff:fedf:3315 prefixlen 64 scopeid 0x20<link>
[root@localhost mnt]# ifconfig eth0 | grep -E "inet\>" 不进行扩展过滤inet
inet 172.25.254.168 netmask 255.255.255.0 broadcast 172.25.254.255
[root@localhost mnt]# ifconfig eth0 | grep -E "inet " 直接加空格过滤
inet 172.25.254.168 netmask 255.255.255.0 broadcast 172.25.254.255编写脚本实现:找出系统中可以登陆的用户
[root@localhost mnt]# cat /etc/shells ##查看shell
[root@localhost mnt]# grep -v nologin /etc/shells ##将nologin行反向过滤掉
[root@localhost mnt]# echo `grep -v nologin /etc/shells` ##将过滤出来结果写为一行
[root@localhost mnt]# echo `grep -v nologin /etc/shells` | sed 's/ /|/g' ##将空格分隔符换为|

[root@localhost mnt]# vim show_loginuser.sh 编写脚本
调用脚本:

2.sed
- sed概述
sed(steam editor)编辑器是一行一行的处理文件内容的。正在处理的内容存放在模式空间(缓冲区)内,处理完成后按照选项的规定进行输出或文件的修改。
行编辑器:用来操作纯ASCII码的文本。
原理:处理时,把当前处理的行存储在“模式空间”(临时缓冲区),
符合模式条件的处理,不符合条件的不处理,处理完成后把缓冲区内
容送往屏幕;接着处理下一行,不断重复,直至文件结束;- P模式(显示模式)语法:
sed -n '/#/p' fstab ##显示文件带#的行
sed -n '/#/p' fstab -i fstab ##将显示结果覆盖掉原文件
cat -n fstab | sed -ne '3p;6p;8p' ##显示文件的3,6,8行
cat -n fstab | sed -ne '1,3!p' ##不显示文件的1-3行 实验:
[root@localhost mnt]# rm -fr *
[root@localhost mnt]# cp /etc/fstab /mnt ##复制fstab到/mnt下
[root@localhost mnt]# sed -n '/^#/p' fstab ##显示以#开头的行
[root@localhost mnt]# sed -n '/^#/!p' fstab ##显示除了以#开头的行
[root@localhost mnt]# sed -n '/0$/p' fstab ##显示以0结尾的行
[root@localhost mnt]# cat -n fstab
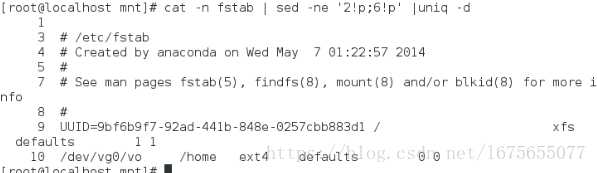
[root@localhost mnt]# cat -n fstab |sed -n '2,6p' ##显示2-6行
[root@localhost mnt]# cat -n fstab |sed -n -e '2p' -e '6p' ##显示第二行和第六行(-e表示多个条件)
[root@localhost mnt]# cat -n fstab |sed -n -e '2p;6p' ##显示第二行和第六行
[root@localhost mnt]# cat -n fstab |sed -ne '2!p;6!p' | uniq -d ##显示除了第二行和第六行

编写脚本:使用文件中的用户名和密码建立新用户

[root@localhost mnt]# vim passfile ##建立用户密码文件
[root@localhost mnt]# vim user_create.sh ##编写脚本
- D模式(删除模式)语法:
sed '1,4d' fstab ##删除文件的1、4行
sed '/^#/d' fstab ##删除文件以#开头的行
sed '/^UUID/!d' fstab ##除了以UUID开头的行都删除实验:
[root@localhost mnt]# sed -e '2d;6d' fstab ##除了2和6行都显示
[root@localhost mnt]# sed -e '/^#/d' fstab ##删除以#开头的行
[root@localhost mnt]# sed -e '/^$/d' fstab ##删除空格行
[root@localhost mnt]# sed -e '/^$/d;/^#/d' fstab ##删除空格行和#开头的行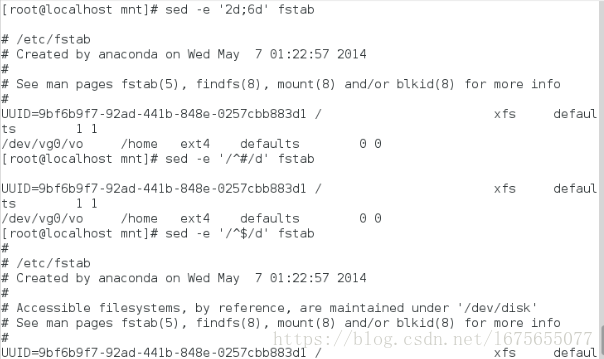

- A模式(添加模式)语法:
sed '/^UUID/a hello' fstab ##在以UUID开头的那一行后插入hello行
sed '/^UUID/a hello\ntest' fstab ##在以UUID开头的那一行后插入hello行和test行

[root@localhost mnt]# vim westos ##写入hello
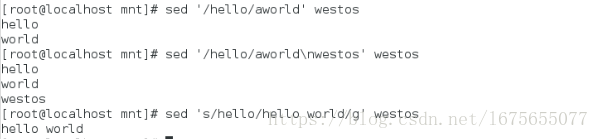
[root@localhost mnt]# sed '/hello/aworld' westos ##在hello后添加world行
[root@localhost mnt]# sed '/hello/aworld\nwestos' westos ##\n在world后面换行添加
[root@localhost mnt]# sed 's/hello/hello world/g' westos ##将hello更换成hello world
- i模式(插入模式)语法:
sed '/^UUID/i hello' fstab ##在以UUID开头的那一行前插入hello行 sed '/hello/iwestos' westos ##在hello前插入一行westos
- c模式(替换模式)语法:
sed '/^UUID/c hello' fstab ##将以UUID开头的那一行替换成hello行实验:
sed '/hello/chello world' westos ##将hello替换成hello world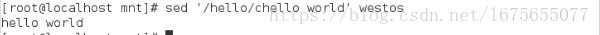
- w模式(写入模式)语法:
sed '/^UUID/w /mnt/test' fstab ##将文件fstab以UUID开头的那一行写入/mnt/test
sed -n '/^UUID/w /mnt/test' fstab ##不输出结果
sed '/^UUID/=' fstab ##将文件fstab以UUID开头的行号输出
sed '1r /mnt/hello' fstab ##将/mnt/hello文件写入fstab的第1行
sed '$r /mnt/hello' fstab ##将/mnt/hello文件写入fstab的最后1行实验:
cp /etc/passwd /mnt[root@localhost mnt]# sed -n '/bash$/p' passwd > file ##将bash结尾的行重定向到文件
[root@localhost mnt]# cat file ##查看文件
[root@localhost mnt]# rm -r file ##删除文件
[root@localhost mnt]# sed -n '/bash$/wfile' passwd ##将bash结尾的行写入到文件
[root@localhost mnt]# cat file ##查看文件
ps:w和>的区别:w做的是一个命令,>做的是两个命令;w的效率要比>高
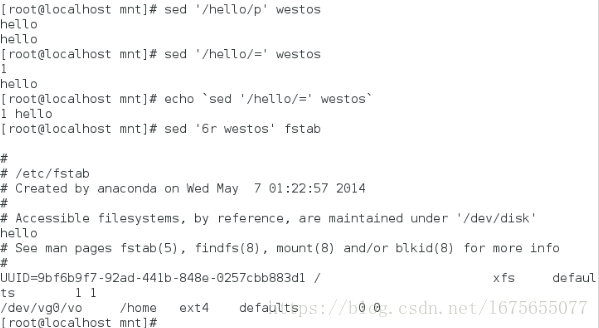
[root@localhost mnt]# sed '/hello/p' westos
[root@localhost mnt]# sed '/hello/=' westos ##输出行号
[root@localhost mnt]# echo `sed '/hello/=' westos` ##将输出结果放到一行
[root@localhost mnt]# sed '6r westos' fstab ##将westos的内容加到fstab文件的第六行下面
- sed其他用法
sed -n -f prctise fstab ##对fstab执行prctise的策略
[root@localhost mnt]# cat prctise
/^UUID/p
\/^UUID/=
sed -n -e '/^UUID/p' fstab -e '/^UUID/=' ##同上
sed 's/s/S/g' fstab ##将fstab全文的s替换成S
sed '1,3s/s/S/g' fstab ##将fstab前3行的s替换成S
sed '/by/,/man/s/S/\#/g' fstab ##将fstab字符by与man之间的S替换成#
sed 's@s@S@g' fstab ##@于/意义相同
sed 'G' hello ##在hello文件的每行后插入空行
sed '$!G' hello ##除了最后1行,每行后插入空行
sed '=' hello ##显示行号实验:
[root@localhost mnt]# sed -n '/^UUID/=' fstab ##只显示行数
[root@localhost mnt]# sed '/^UUID/=' fstab ##显示行数和内容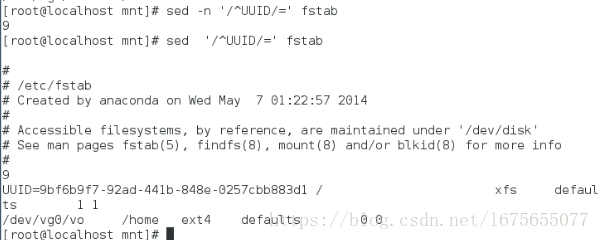
[root@localhost mnt]# sed '=' fstab | sed 'N;s/\n//g' ##在文件前面加行号
[root@localhost mnt]# sed 'G' fstab ##在内容的每一行后面加一个空行
[root@localhost mnt]# sed '$!G' fstab ##在最后一行不加空行
[root@localhost mnt]# sed -n '$p' fstab ##显示最后一行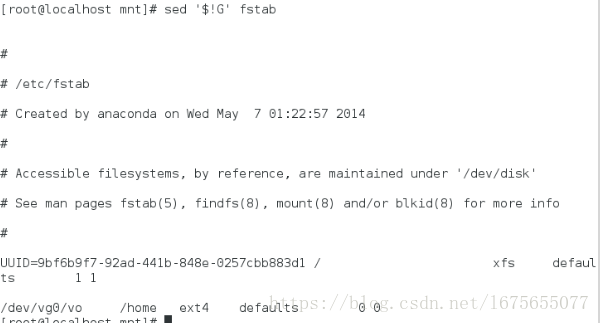

- sed替换用法:
[root@localhost ~]# cd /mnt/
[root@localhost mnt]# rm -fr *
[root@localhost mnt]# cp /etc/passwd .
[root@localhost mnt]# vim passwd ##删除passwd部分行,方便查看
[root@localhost mnt]# sed 's/nologin/westos/g' passwd ##将全文的nologin替换成westos(/g是替换全文)
[root@localhost mnt]# sed '3,5s/nologin/westos/g' passwd ##替换3和5行

利用文件进行替换:
[root@localhost mnt]# vim file ##编辑替换文件
s/sbin/westos/g
s/nologin/linux/g
[root@localhost mnt]# sed -f file passwd ##执行file里的替换命令
[root@localhost mnt]# cat passwd ##所有的替换都不会改变原文件
[root@localhost mnt]# sed -f file -i passwd ##将原文件改变,-i表示改变源文件
[root@localhost mnt]# cat passwd ##查看文件已经改变
编写脚本:自动安装apache并且配置指定端口
vim install_apache.sh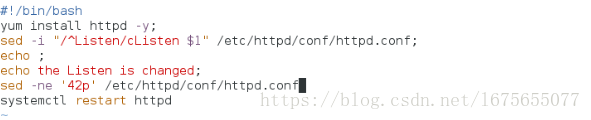
调用脚本:

3.awk
- awk(报告生成器)概述
简单地说, AWK 是一种用于处理文本的编程语言工具。 任何awk语句都是由模式和动作组成,一个awk脚本可以有多个语句。模式决定动作语句的触发条件和触发时间。
awk的参数:
awk -F : 'BEGIN{print "NAME"}{print $1}' passwd
以:为分隔符,处理前打印 NAME ,打印第1列
awk -F : 'BEGIN{print "NAME"}{print $1}END{print NR}' passwd
以:为分隔符,处理前打印 NAME ,打印第1列,处理后打印行数(NF列)
awk -F : '/bash$/{print $7}' passwd
以:为分隔符,打印以bash结尾行的第7列
awk -F : '/bash$/' passwd
以:为分隔符,打印以bash结尾行
awk -F : 'NR==3' passwd
以:为分隔符,打印第3行
awk -F : 'BEGIN{print "NAME"}NR<=3&&NR>=2{print $1}' passwd
以:为分隔符,处理前打印 NAME ,打印2-3行的第1个字符实验:
[root@localhost mnt]# awk -F ":" '{print $1}' passwd ##打印第一列
[root@localhost mnt]# awk -F ":" 'BEGIN{print "NAME"}{print $1}' passwd ##以:为分隔符,处理前打印NAME,打印第1列

[root@localhost mnt]# awk ":" '/bash$/{print}' passwd ##打印bash结尾的行
[root@localhost mnt]# awk -F ":" 'BEGIN{N=0}/bash$/{N++}END{print N}' ##passwd 从零开始统计bash结尾的行数
[root@localhost mnt]# awk '/^a|nologin$/{print}' passwd ##打印a开头的同时nologin结尾的行
[root@localhost mnt]# awk -F ":" '$1~/^r/{print}' passwd ##打印以r开头的行
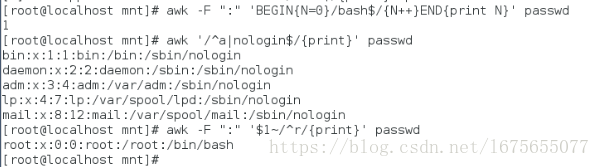
[root@localhost mnt]# awk -F ":" '$1!~/^r/{print}' passwd ##打印不是以r开头的行
[root@localhost mnt]# awk -F ":" '$7!~/bash$/{print}' passwd ##打印不是bash结尾的行
[root@localhost mnt]# awk -F ":" '{print NR,$0}' passwd ##打印行数,0代表所有
[root@localhost mnt]# awk -F ":" '{print NR,$1}' passwd ##1代表第一列依次类推
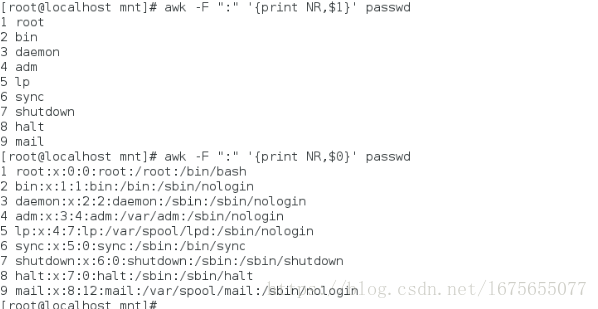
[root@localhost mnt]# awk -F ":" '$6!~/^\/home/&&/bash$/{print $1}' /etc/passwd ##以:为分隔符,打印家目录下不是bash结尾的,打印第一列
[root@localhost mnt]# awk -F ":" 'BEGINA{n=0}$6!~/^\/home/&&/bash$/{n++}END{print n}' /etc/passwd ##统计个数

4.脚本练习
- 打印能登陆系统且家目录不是/home的用户个数

- 打印eth0的ip

或:

- 打印能登陆系统的用户

- 利用awk显示文件的行数

