shell脚本三大文本处理工具:
- grep 文本过滤命令
- sed 行编辑器
- awk 报告生成器
常用的正则表达式如下:
| 元字符 |
功能 |
示例 |
| ^ |
行首定位符 |
/^my/ 匹配所有以my开头的行 |
| $ |
行尾定位符 |
/my$/ 匹配所有以my结尾的行 |
| . |
匹配除换行符以外的单个字符 |
/m..y/ 匹配包含字母m,后跟两个任意字符,再跟字母y的行 |
| * |
匹配零个或多个前导字符 |
/my*/ 匹配包含字母m,后跟零个或多个y字母的行 |
| [] |
匹配指定字符组内的任一字符 |
/[Mm]y/ 匹配包含My或my的行 |
| [^] |
匹配不在指定字符组内的任一字符 |
/[^Mm]y/ 匹配包含y,但y之前的那个字符不是M或m的行 |
| .. |
保存已匹配的字符 |
1,20s/youself/\1r/ 标记元字符之间的模式,并将其保存为标签1,之后可以使用\1来引用它。最多可以定义9个标签,从左边开始编号,最左边的是第一个。此例中,对第1到第20行进行处理,you被保存为标签1,如果发现youself,则替换为your。 |
| & |
保存查找串以便在替换串中引用 |
s/my/**&**/ 符号&代表查找串。my将被替换为**my** |
| \< |
词首定位符 |
/\<my/ 匹配包含以my开头的单词的行 |
| \> |
词尾定位符 |
/my\>/ 匹配包含以my结尾的单词的行 |
| x\{m\} |
连续m个x |
/9\{5\}/匹配包含连续5个9的行 |
| x\{m,\} |
至少m个x |
/9\{5,\}/ 匹配包含至少连续5个9的行 |
| x\{m,n\} |
至少m个,但不超过n个x |
/9\{5,7\}/ 匹配包含连续5到7个9的行 |
一、grep命令
grep(Global search regular expression and print out the line)全面搜索研究正则表达式并显示出来。
grep可以根据用户指定的“模式”对目标文件进行匹配检查,打印匹配到的行,由正则表达式或者字符及基本文本字符所编写的过滤条件。它是一种强大的文本搜索工具,与正则表达式结合使用。
grep支持多文件查询如grep pattern a.txt b.txt,grep指定多个文件时可以使用通配如grep pattern ?.txt,查找a.txt、b.txt等单个字符开头的txt文件。
grep格式:grep [选项] [模式] [文件...],它在一个或多个文件中搜索满足模式的文本行,grep的选项如下:
常用的grep选项有:
-c 只输出匹配行的计数。
![]()
-i 不区分大小写(只适用于单字符)。

-h 查询多文件时不显示文件名。

-l 查询多文件时只输出包含匹配字符的文件名。

-n 显示匹配行及行号。

-s 不显示不存在或无匹配文本的错误信息。
-v 显示不包含匹配文本的所有行。

-q 静默,无任何输出
![]()
grep命令的模式可以是字符串、变量或正则表达式,
grep与正则表达式结合
(1)基本元字符匹配
元字符"^"匹配行首,"$"匹配行尾,"^$"表空白行
"^"匹配行首:
![]()
"$"匹配行尾:
[root@server script]# grep -m10 '/sbin/nologin$' /etc/passwd ##在/etc/passwd的文件中匹配以/sbin/nologin为行尾的前10行内容

"^$"匹配空白行
![]()
"."匹配非空的任意字符

添加-v参数匹配空行
![]()
过滤/etc/passwd文件中root在中间的行:
[root@server script]# grep -v -i -E "^root|root$" /etc/passwd | grep -i root
operator:x:11:0:operator:/root:/sbin/nologin
grep中…的使用:
[root@server script]# grep 'r....t' char ##中间有几个点就匹配中间有几个字符的行

[root@server script]# grep '..t' char ##匹配以..t结尾的行

[root@server script]# grep 'r..' char ##匹配以r..开头的行

(2)匹配重复字符
* 字符出现0-任意次
[root@server script]# grep -E 'o*t' char ##匹配t前面有任意个o或者没有o的行

[root@server script]# grep -E 'ro*t' char ##匹配r和t之间有任意个o或者没有o的行

\? 字符出现0-1次(转义符,需要用egrep命令或者grep -E)
[root@server script]# grep -E 'o?t' char ##匹配t前面有一个o或者没有o的行
[root@server script]# grep -E 'o(t)?' char ##等同于上面的语句


[root@server script]# grep -E 'ro?t' char ##匹配r和t之间有1个o或者没有o的行
[root@server script]# grep -E 'r(o)?t' char ##等同于上面的语句


\+ 字符出现1-任意次
[root@server script]# grep -E 'o+t' char ##匹配t前面出现1-任意个o的行

[root@server script]# grep -E 'ro+t' char ##匹配r和t之间出现1-任意个o的行

\{n\} 字符出现 n 次
[root@server script]# grep -E 'ro{3}t' char ##r和t之间出现3个o
![]()
[root@server script]# grep -E 'ro{1,3}t' char ##r和t之间出现1~3个o

[root@server script]# grep -E 'ro{1,}t' char ##r和t之间至少出现1个o

[root@server script]# egrep '(root){2,}' char ##匹配至少有两个连续"root"的行

[root@server script]# egrep '(root){1,3}' char ##匹配有1~3个"root"的行

[root@server script]# egrep '(root)[a m]' char ##匹配有字符"roota" "rootm"的行
[root@server script]# egrep '(root)[am]' char ##匹配有字符"roota" "rootm"的行
[root@server script]# egrep '(root)[a,m]' char ##匹配有字符"roota" "rootm"的行
以上三条语句作用等价

[root@server script]# egrep '[A-Z]' char ##匹配有A~Z中其中任何一个字符的行 [ ]匹配指定字符组内的任一字符

egrep和fgrep
(1)grep命令族:grep(支持基本正则表达式)、egrep(等价grep -E)(扩展grep命令,支持基本和扩展正则表达式)、fgrep(等价grep -F)(快速grep命令,不支持正则表达式,按字符串的字面意思进行匹配)。
(2)egrep "^-+B" a.txt,查找以"-"开头且至少重复一次然后加B字符的字符串,"+"至少重复一次,"*"重复0次或无数次。
(3)grep命令功能十分强大,以代替egrep和fgrep命令。
二、sed行编译器
sed 是一种在线编辑器,它一次处理一行内容。sed是非交互式的编辑器。它不会修改文件,除非使用shell重定向来保存结果。默认情况下,所有的输出行都被打印到屏幕上。
sed(Stream EDitor),是一种行编辑工具,用来操作纯ASCLL码的文本 ,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,可以指定仅仅处理那些行。sed符合模式条件的处理,不符合的不处理,处理完成之后把缓冲区的内容送往屏幕,接着处理下一行,这样不断重复,知道文件末尾,不对原文件内容作修改。
前面说到sed不会修改文件,那么现在我们可以知道是为什么了?是因为sed把每一行都存在临时缓冲区中,对这个副本进行编辑,所以不会修改原文件。
在使用sed的过程中,我们经常会听到“定址”,那么什么是“定址”呢?
定址用于决定对哪些行进行编辑。地址的形式可以是数字、正则表达式、或二者的结合。如果没有指定地址,sed将处理输入文件的所有行。
1、地址是一个数字,则表示行号;是“$"符号,则表示最后一行。
[root@server script]# sed -n '3p' char ##只打印第三行 -n:取消默认打印设置(打印全部行),p:打印
rooooot[root@server script]# sed -n '$p' char ##只打印最后一行
rootam
地址是逗号分隔的,那么需要处理的地址是这两行之间的范围(包括这两行在内)。范围可以用数字、正则表达式、或二者的组合表示。
例如:
[root@server script]# sed -n '2,4p' char ##打印2~4行,包括第2行与第4行

[root@server script]# sed -n '/^root/,/am$/p' char ##打印以"root"为行首的行到以"am"为行尾的行

sed命令和参数
sed命令
| a\ | 在当前行后添加一行或多行 |
| c\ | 用新文本替换当前行中的文本 |
| d | 删除行 |
| i\ | 在当前行之前插入文本 |
| h | 把模式空间的内容复制到暂存缓冲区 |
| H | 把模式空间的内容添加到缓冲区 |
| g | 取出暂存缓冲区的内容,将其复制到模式缓冲区 |
| G | 取出暂存缓冲区的内容,将其追加到模式缓冲区 |
| l | 列出非打印字符 |
| p | 打印行 |
| n | 读入下一行输入,并从下一条而不是第一条命令对其处理 |
| q | 结束或退出sed |
| r | 从文件中读取输入行 |
| ! | 对所选行以外的行应用所有命令 |
| s | 用一个字符串替换另外一个字符串 |
sed参数
| 选项 |
功能 |
| -e |
进行多项编辑,即对输入行应用多条sed命令时使用 |
| -i |
直接在原文件上进行操作 |
| -n |
取消默认的输出 |
| -f |
指定sed脚本的文件名 |
<1>p(显示)命令:
命令p用于显示模式空间的内容。默认情况下,sed把输入行打印在屏幕上,选项-n用于取消默认的打印操作。当选项-n和命令p同时出现时,sed可打印选定的内容。
[root@server script]# sed '/\:/p' /etc/fstab #默认情况下,sed把所有输入行都打印在标准输出上。如果某行匹配模式":"命令将把该行另外打印一遍(即匹配行紧挨着打印两遍)。

[root@server script]# sed -n '/\:/p' /etc/fstab #选项-n取消sed默认的打印,p命令把匹配模式":"的行打印一遍。 ![]()
[root@server script]# sed -n '/^#/!p' /etc/fstab ##打印除了以#开头的行

[root@server script]# sed -n '2,6p' /etc/fstab ##打印第2到第6行,包括第2行与第6行

<2>d(删除)命令:
[root@server script]# sed '$d' /etc/fstab ##删除最后一行,其余的都被显示

[root@server script]# sed '/^#/d' /etc/fstab ##删除匹配到的行,其余的都被显示

<3>a(追加)命令:
[root@server script]# sed '/hello/aworld' sed ##所追加的文本行位于sed命令的下方另起一行。
hello
world
westos

也可以通过a\进行追加,如果要追加的内容超过一行,则每一行都必须以反斜线结束,最后一行除外。最后一行将以引号和文件名结束。

<4>替换:s命令和全局:g命令
[root@server script]# sed 's/hello/hello world/g' sed #命令末端的g表示在行内进行全局替换,处理匹配行,把行内所有的hello替换为hello world。
hello world
westos
[root@server script]# sed -n '1,20s/nologin$/wwww/gp' /etc/passwd ##取消默认输出,处理1到20行里匹配以nologin结尾的行,把行内所有的login替换为www,并打印到屏幕上。

[root@server script]# sed 's/\//#/g' /etc/fstab ##将文件中的"/"替换为"#"

紧跟在s命令后的字符就是查找串和替换串之间的分隔符。分隔符默认为正斜杠,但可以改变。无论什么字符(换行符、反斜线除外),只要紧跟s命令,就成了新的串分隔符。
[root@server script]# sed 's#hello#happy#g' sed ##修改串分割符为#,将文件中的hello替换为happy
happy
westos
<5>i 命令(插入文本)
i命令是在当前行的前面插入新的文本。
[root@server script]# sed '/hello/iworld\nbeauty' sed
world
beauty
hello
westos

也可以通过i\插入:
[root@server script]# sed '/hello/i\
world\nbeauty
> ' sed
world
beauty
hello
westos

<6>c命令(替换文本)
sed使用此符号后的新文本替换当前行中的文本。
[root@server script]# sed '/hello/chelloworld' sed
helloworld
westos
sed命令典型练习题:
http://www.cnblogs.com/wangcp-2014/p/6756377.html
sed选项
-e:
-e是编辑命令,用于sed执行多个编辑任务的情况下。在下一行开始编辑前,所有的编辑动作将应用到模式缓冲区中的行上。
[root@server script]# sed -e '1,3d' -e 's/\//#/g' /etc/fstab
#选项-e用于进行多重编辑。第一重编辑删除第1-3行。第二重编辑将出现的所有"/"替换为"#"。因为是逐行进行这两项编辑(即这两个命令都在模式空间的当前行上执行),所以编辑命令的顺序会影响结果。
-i:直接在原文件上进行操作
练习:
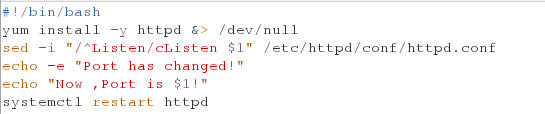
脚本编写:安装appache,并且改变它的端口;
[root@server script]# vim duankou.sh
#!/bin/bash
yum install -y httpd &> /dev/null
sed -i "/^Listen/cListen $1" /etc/httpd/conf/httpd.conf
echo -e "Port has changed!"
echo "Now ,Port is $1!"
systemctl restart httpd
执行脚本查看结果:

awk 报告生成器
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。如下所示:
[root@server ~# cat test
this | is | a | file
$1 $2 $3 $4
awk 处理机制:awk 会逐行处理文本,支持在处理第一行之前做一些准备工作,以及在处理完最后以行做一些总结性质的工作,在命令格式上分别体现如下:
BEGIN{}:读入第一行文本之前执行,一般用来初始化操作;
{}:逐行处理,逐行读入文本执行相应的处理,是最常见的编辑指令;
END{}:处理完最后一行文本之后执行,一般用来输出处理结果;
awk命令格式:
awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file
[-F|-f|-v] 大参数,-F指定分隔符,-f调用脚本,-v定义变量 var=value
' ' 引用代码块
BEGIN 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// 匹配代码块,可以是字符串或正则表达式
{} 命令代码块,包含一条或多条命令
; 多条命令使用分号分隔
END 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
awk常用变量:
注意:$0代表整行
| 变量名称 | 代表意义 |
| NF | 每一行($0)拥有字段总数 |
| NR | 目前awk处理的第几行 |
| FS | 目前分隔符,默认是空白, BEGIN时定义分隔符 |
| FILENAME | 文件名 |
[root@server script]# awk '{print $0}' test1.sh ##输出文件整行的内容

[root@server script]# awk '{print $1}' test1.sh ##以空格文分隔符,输出每行的第一个字段

[root@server script]# awk '{print $1,$4}' test1.sh ##以空格为分隔符,输出每行的第一个和第四个字段

[root@server script]# awk -F ":" '{print $1,$3}' /etc/passwd ##指定":"为分隔符,输出每行的第一个和第三个字段

[root@server script]# awk '{print FILENAME,NR}' test1.sh ####输出文件名,和当前操作的行号

[root@server script]# awk '{print NR,NF}' test1.sh ####输出每次处理的行号,以及当前处理行以" "为分隔符的字段个数

[root@server script]# awk '{print "第"NR"行","有"NF"列"}' test1.sh

awk的逻辑运算:
| 运算单元 | 代表意义 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| == | 等于 |
| != | 不等于 |
值得注意的是那个“ == ”的符号,因为:
- 逻辑运算上面亦即所谓的大于、小于、等于等判断式上面,习惯上是以“ == ”来表示;
- 如果是直接给予一个值,例如变量设置时,就直接使用 = 而已。
awk 基本用法练习:
[root@server script]# awk 'BEGIN { a=34;print a+10 }' ##只有BEGIN代码块时,命令依然可以执行
44
![]()
[root@server script]# awk -F ":" 'BEGIN{print "Redhat"} {print NR;print } END{print "Westos"}' test1.sh
##文件开头加Redhat,末尾加Westos,打印行号和内容

[root@server script]# awk -F: '/bash$/{print}' /etc/passwd ##输出以bash结尾的行

[root@server script]# awk 'NR==3 {print }' /etc/passwd ##输出第三行的内容
![]()
[root@server script]# awk 'NR%2==1 {print NR; print}' test1.sh ##输出奇数行行号以及内容

[root@server script]# awk 'NR >=3 && NR <=5 {print }' test1.sh ##输出3~5行的内容

[root@server script]# awk 'BEGIN{i=0} {i+=NF} END{print i} ' test1.sh ##统计文本总字段数(默认以" "为字段分隔符)
![]()
awk中的条件语句
awk中的条件语句是从C语言中借鉴来的,必须用在{}中,且比较内容用()扩起来
<1>if单分支语句
[root@server script]# awk -F: '{if($7~/bash$/) print}' /etc/passwd ##输出字段7匹配以bash结尾的行

练习:
统计登录shell为bash的用户个数
[root@server script]# awk -F: 'BEGIN{i=0} {if($7~/bash$/) {i++;print}} END{print "登录shell为bash的用户个数为"i}' /etc/passwd

<2>if双分支语句
练习:
分别统计uid小于等于500和大于500的用户个数
[root@server script]# awk -F: 'BEGIN{i=0;j=0} {if($3<=500) {i++} else {j++}} END{print i,j}' /etc/passwd

awk中的循环语句
<1>for循环
[root@server script]# awk 'BEGIN{for(i=1;i<=5;i++){print i}}'

<2>while循环
[root@server script]# awk -F: 'BEGIN{i=1} {while(i<NF) {print NF,$i,i++}}' /etc/passwd
