先上代码:
import requests
from lxml import html
url='http://www.shuge.net/html/111/111781/6593021.html' #需要爬数据的网址
page=requests.Session().get(url)
tree=html.fromstring(page.text)
result=tree.xpath('//div[@class="box_con"]//div/text()') #获取需要的数据
print(result) #打印爬取结果
fo=open('1.txt','w') #将数据写入文件
for ip in result:
fo.write(ip)
fo.write('\n')
fo.close()
print("1")爬取结果展示:

爬取内容为目标网页中的小说:
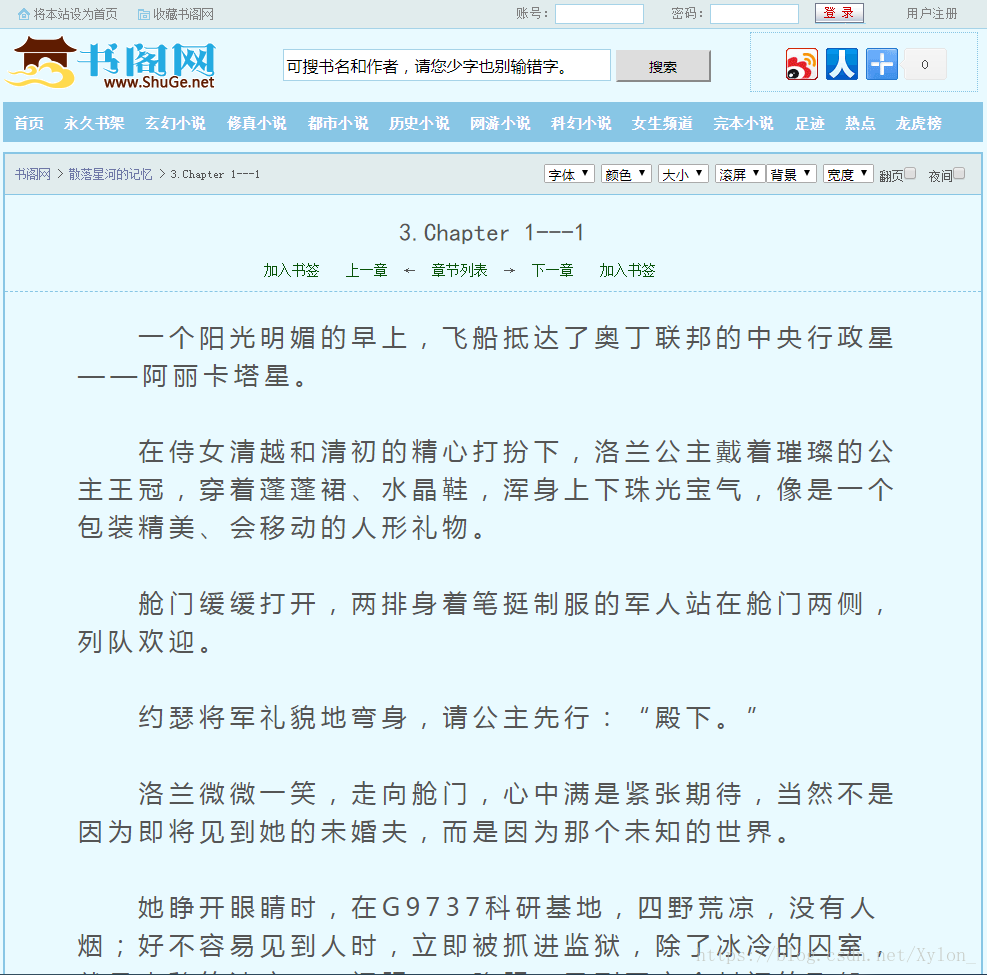
爬虫讲解:
首先要安装两个爬虫必备模块:
import requests
from lxml import html
request模块,用于向HTTP发送请求;如果没有安装可在终端执行“pip install requests”命令进行安装。
lxml模块同理,执行“pip install lxml”命令即可安装。
接下来要做的,就是寻找“猎物”,以一个小说网站为例:
对将要爬取的内容点击鼠标右键-检查

可以看到我们将要获取的内容在一个div里,接着往上寻找其上级标签,也就是这个:
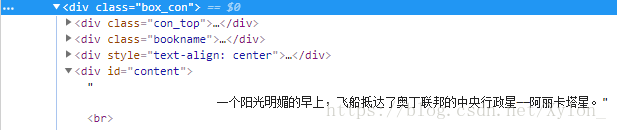
将其标签及其class内容写入代码
result=tree.xpath('//div[@class="box_con"]//div/text()')
第一个div及为上级标签,后面是class内容,第二个div即为包含我们将要爬取内容的标签,text()即为该标签内的文字信息,格式根据爬取不同网页时的情况而定;
result会获取该网页所有<div class="box_con">标签下的div的文字的内容;
接着要做的就是将result里的内容写入txt文件,由于result获取到的是一个list,因此在写入是可以这样写:
fo=open('1.txt','w') #将数据写入文件
for ip in result:
fo.write(ip)
fo.write('\n')
fo.close()
写入结果即为文章第二章图片显示。
再来试一下爬取热门小说排行榜吧!
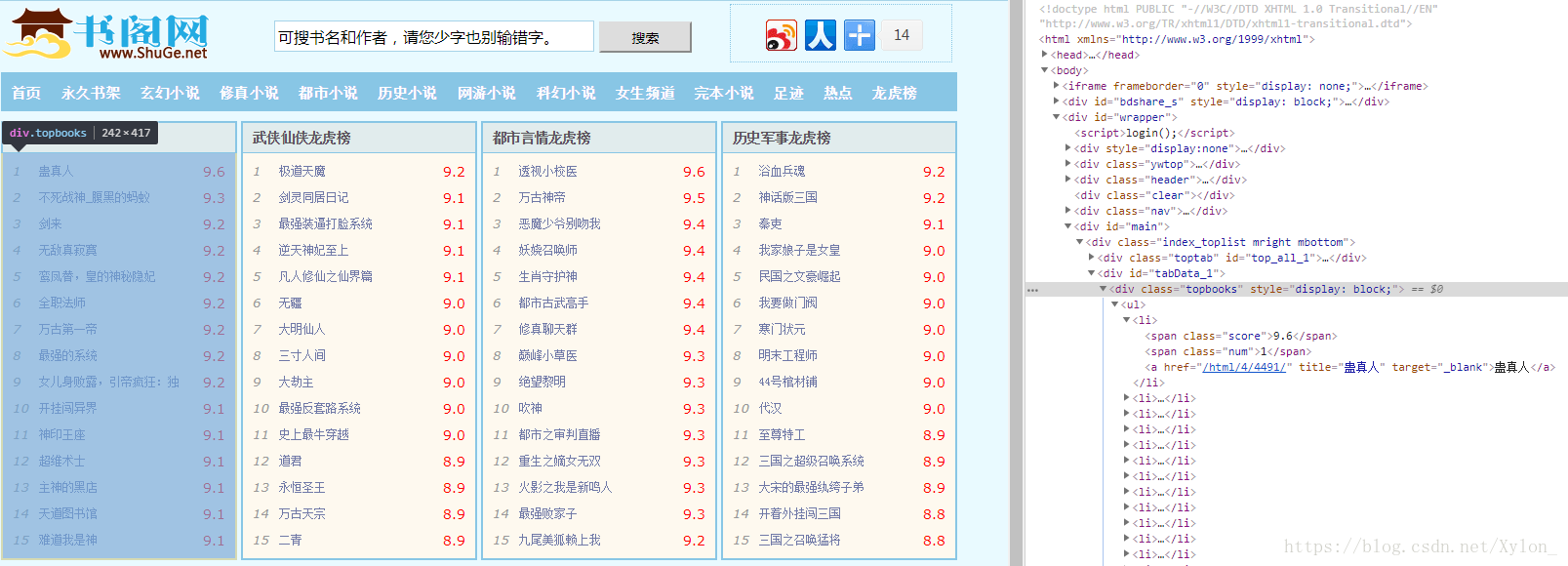
这次的爬取内容是在<div class="topbooks">下的标签<a >里,那么我们其中两行代码这样写:
url='http://www.shuge.net/longhubang/'result=tree.xpath('//div[@class="topbooks"]//a/text()')
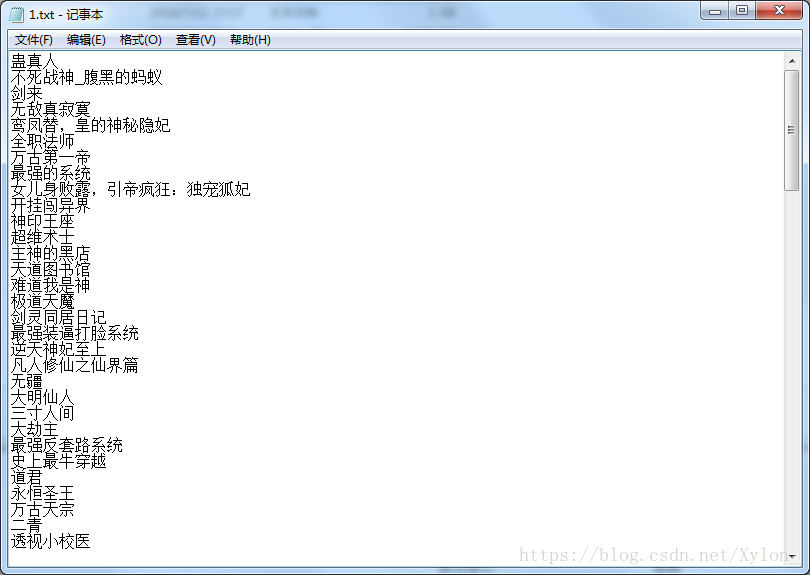
爬取结果:
怎么样,是不是很简单呢?
但现实中爬虫会遇到很多问题,比如:
1. 页面规则不统一;
2. 爬下来的数据处理;
3. 反爬虫机制。
这些都需要一步一步地学习和摸索,坚持下去,总有一天你会成为爬虫大神的哟~
感谢观看
文章借鉴于博主@a_achengsong