JAVA-HashMap
HashMap是一种特殊的数据结构。既然是数据结构,就一定有应用的场景,不然哪些JDK大牛搞这个干啥。
问题:
Q1 它能干啥?
Q2 有什么特别的?
Q3 有什么优点?
A1: 当我们需要存放key-value pair 键值对的时候,就可以使用这个结构
A2: 名字里面能带hash,说明它和hash有关;而且可以允许存放‘空’的键值对。
A3: 既然是map,说明有快速查询value的优势。
HashMap它很好的解决了存储和查询K-V的问题。
在JDK1.7中,它自身的结构是数组+链表来实现的,数组中的每一个元素都是一个链表。通过计算key的hashcode来把hashcode相同的存放在相同的数组元素中。
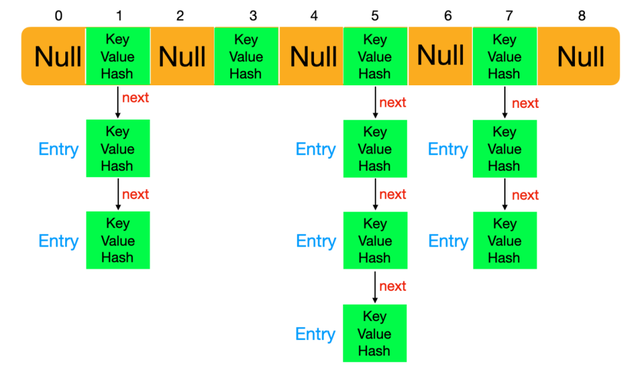
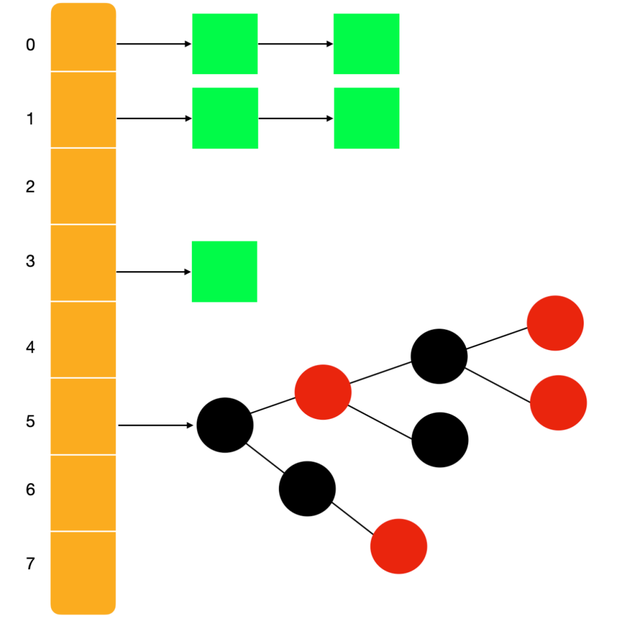
在JDK1.8中,底层结构发生了变化当一个Entry链中大于8个元素时,就会转变为红黑树
结构已经有了初步的认识,怎么用,用的时候关注哪些问题?
容量问题:因为HashCode计算返回int范围高达+-21亿,不算负数,所以数组范围就可以支持那么大。但是超大的容量会带来各种各样的问题,所以HashMap的默认容量是16。
使用中会不会超出容量?
当然有可能超过默认的16,当想hashmap添加超过一定数量的KV,就会触发自动扩容,每次容量增加一倍,即16-32-64……。如果hashmap经常触发扩容的话,会导致性能影响很大,所以尽量设定好容量之后,避免扩容。
HashMap什么时候会扩容,扩容的原则是什么?扩容的规则。
HashMap有一个参数负载因子loadfactor,JDK中默认0.75,如果hashmap中的kv到达容量*负载因子,例如16*0.75=12,到达12个KV就会自动扩容从16扩展到32,而且要重新确定索引位置。当然使用者也可以自己定义负载因子,但是不建议自己定义。因子太大,空间利用率越大,但是查找速度就会变慢,因子太小,空间就会有很多浪费。
源码
类定义

类定义常量

键值对

扩容

put

get

链表转红黑树

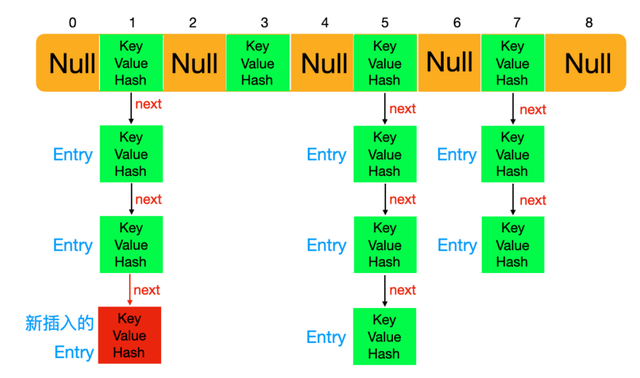
put
首先检查table是不是null,如果为空,就resize初始化table。
如果计算(n - 1) & hash值对应的桶为空就直接插入一个新node。如果已经存在了就要判断hash,k,v,如果hash,key都一样,就会根据条件将之前的v覆盖;如果hash,key不一致就会新插入node(而且会根据节点类型,插入树节点还是链表节点),如果k,v 数量大于阈值,就会触发扩容resize

get
根据key 计算hash,并且去查询HashMap是否存在这个节点。根据hash和key确认(n - 1) & hash和key是否相等,如果有就取出返回,如果没有就没有查到。
一些问题
看完以上,对HashMap基本算是了解了。还有一些比较杂的问题,可能大家都会有一些疑惑,但是并没有在意,因为不会影响使用。
HashMap的长度是2的幂次?
为什么通过(n - 1) & hash来决定桶的位置?
简单来说,是为了更有效的减少碰撞的几率,从而能够有效提高效率。如果想要详细了解,可以去看一下hashmap的hash源码。
HashMap为什么线程不安全
线程安全问题必然是在多线程的情况下发生,如果有2个线程threadA,threadB,
threadA要插入一个kv到hashmap中,在做put的操作时, 时间片刚好结束,threadB开始执行,要把一个kv插到hashmap中,并成功插入。如果2个线程使用的桶是一样的,这个时候threadA就会把threadB的记录覆盖掉。