题目: Automatically Learning Semantic Features for Defect Prediction
作者: Song Wang, Taiyue Liu, Lin Tan
单位: Electrical and Computer Engineering, University of Waterloo, Canada
出版: ICSE, 2016
解决的问题
现有的机器学习与缺陷预测结合的方法大多无法抓住程序的语义信息,因而无法构建精确的预测模型。本文提出用深度学习的方法来自动学习代码的语义表达,建立起缺陷预测和程序语义之间的桥梁。
贡献点
- 提出了利用深度学习来学习程序语义特征的方法
- 利用从深度学习得到的语义特征来提高工程内缺陷预测和跨工程缺陷预测的精度
- 我们在10个开源Java工程上的实验结果显示我们的方法对工程内和跨工程的缺陷预测性能都有所提升(分别提升了14.2%和8.9%的F1值)
方案
我们的方法整体过程如图所示:
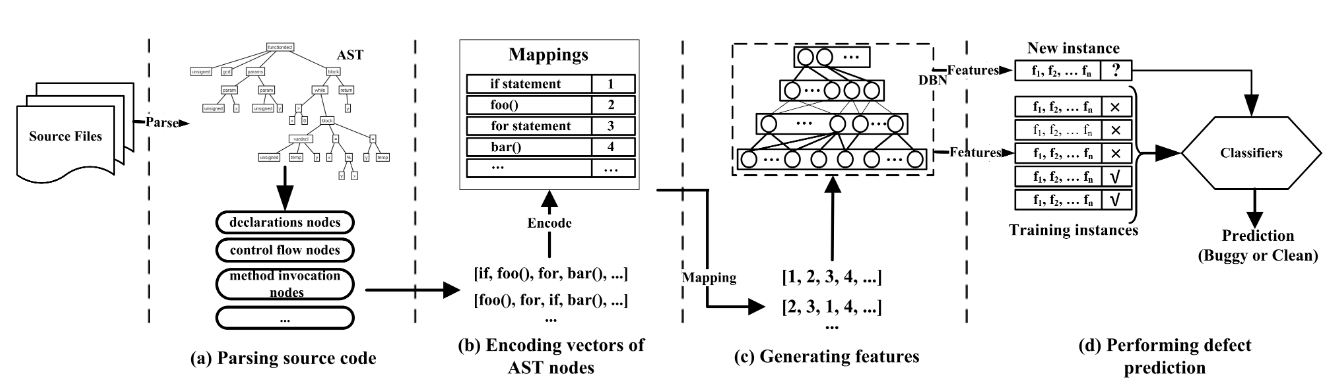
- 从源码的抽象语法树中抽取出方法调用和条件分支结点,按照其在源码中出现的顺序排成语句序列
- 将每个语句映射为一个序号,即将语句序列映射为一个整数向量
- 将此整数向量输入深度置信网络(DBN),输出向量作为分类模型的特征向量
- 利用DBN输出的特征向量构建分类模型
原理
深度信念网络(Deep Belief Network, DBN)
- DBN由多层受限玻尔兹曼机(RBM)组成
- 作为非监督学习模型相当于自动编码机,主要作用是在保留原有样本分布的条件下降维
- 作为监督学习模型相当于分类器,能够通过RBM对样本分布的拟合和BP算法来提高学习的准确性
- 在我们的方法中是作为非监督学习模型
方法
解析源码
我们利用Java AST来从源码中抽取语法信息。以下三种AST结点被我们抽取出来:
- 方法调用结点和类创建结点
- 声明结点,包括方法声明,type声明,enum声明
- 控制流结点,例如wile语句,catch从句,if语句,throw语句等
我们从每个文件中抽取出以上结点组成一个结点序列。
处理噪声
- 使用Closest List Noise Identification(CLNI)方法来除去噪声。 对于每一个样本,利用编辑距离得到距它最近的k个邻居,逐一检查这k个邻居的标签。如果其中几个邻居有与其他相反的标签,则认为它们是噪声。
- 对token序列,我们利用字符串相似度算法替代了编辑距离。
- 利用CLNI的默认参数进行实验。
- 对传统特征也利用CLNI进行过滤,并没讲采用了哪种距离。
此外,我们过滤掉出现次数少于3次的结点语句,因为它们可能是为特定文件设计的,难以推广到其他文件。
结点的映射
我们将所有样本中的所有语句编号,用语句的编号代替该语句,完成从语句序列到整数向量的映射。
每个文件生成的整数向量长度可能不同,而DBN需要等长的输入向量,因为我们取最长向量的长度作为所有向量的长度,对于较短的向量,我们在该向量末尾补0,直到与最长向量长度一致。
训练DBN网络
我们将所有层的结点数设为相同值
DBN要求输入向量的每一维取值范围均为[0, 1],因此我们采用了min-max标准化,才输入了DBN网络。
实验评估
实验目的(Research Question)
我们设计实验来回答以下问题:
- 在工程内缺陷预测中,语义特征的表现是否比传统特征好?
- 在跨工程缺陷预测中,语义特征的表现是否比传统特征好?
- 我们的方法在生成基于DBN的特征时消耗的时间和空间是多少?
实验机器配置
2.5GHz i5-3210M, 4GB RAM
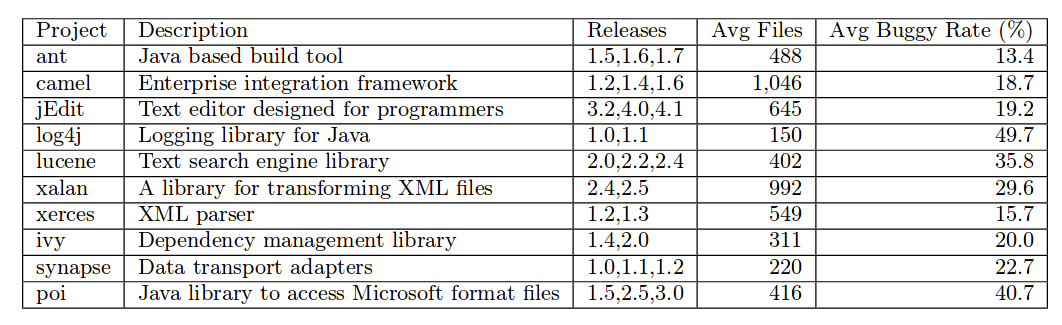
数据集
从PROMISE数据集中选出了10个开源Java程序作为数据集,程序信息如图所示:

两条基准(baseline)
为验证我们方法的有效性,我们另外选定了两组特征,用它们构建同样的DBN+分类器模型,比较三种方法的实验结果。两组特征如下:
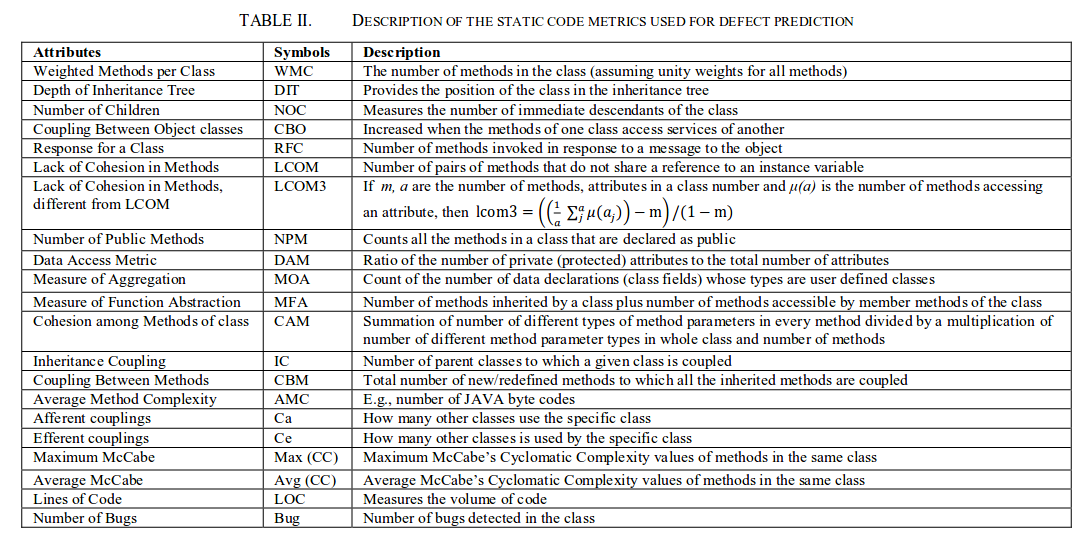
- promise数据集中包含的软件度量特征,被很多传统方法采用。
- 每个文件中前述结点的出现频度(不考虑结点顺序)组成的序列
DBN参数设定
通过试验,确定了DBN层数为10层,每层结点数为100个,迭代次数为200次
类不平衡的解决
利用SMOTE算法对训练数据进行处理
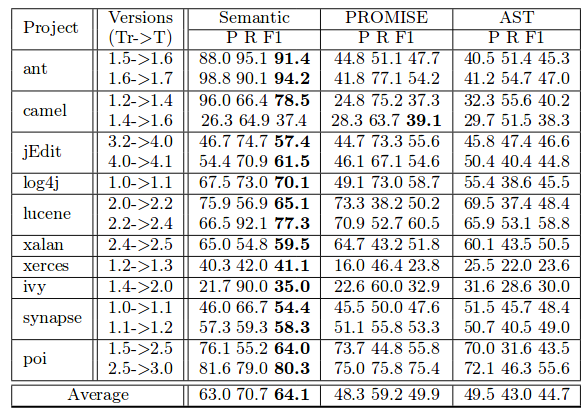
项目内缺陷预测
我们用一个项目较旧版本的代码作为训练集来训练DBN模型和分类模型,将较新版本代码作为测试集输入已训练好的DBN模型和分类模型,得到分类结果。分类模型采用ADTree,朴素贝叶斯,逻辑回归模型。
利用DBN+ADTree得到的分类效果如下图所示:
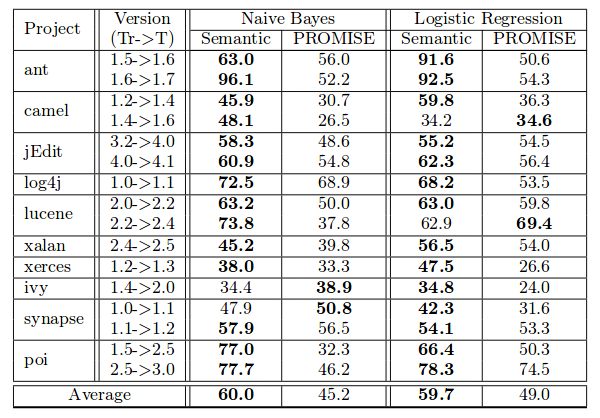
朴素贝叶斯模型和逻辑回归模型效果的对比:
跨工程缺陷预测
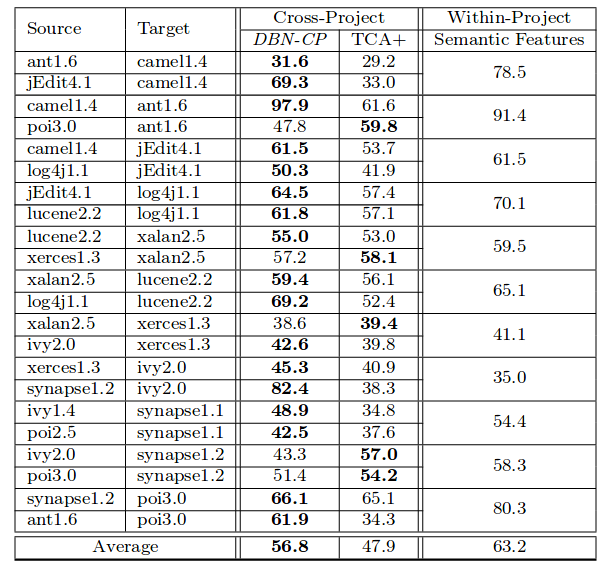
用下图中Source中的程序作为训练集,Target中的程序作为测试集,将我们的方法与TCA+(J.Nam et al. Transfer defect learning)方法进行对比:
时间开销
生成基于DBN的特征所用时间和空间如图所示:
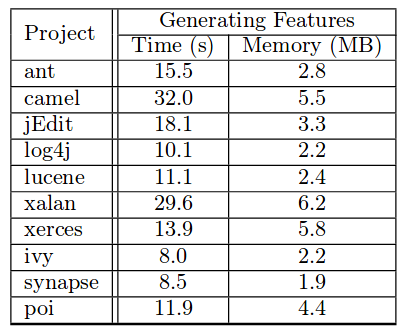
其中时间是将降噪后向量通过DBN得到特征向量所用的时间,不包括解析源码,抽取AST结点和映射等过程。
局限
作者没写,只写了未来工作,可能在C程序上展开,也可能将本文方法应用于其他层级的缺陷预测,例如函数级别,软件模块级别等。