首先先看到top500的页面,如下图所示
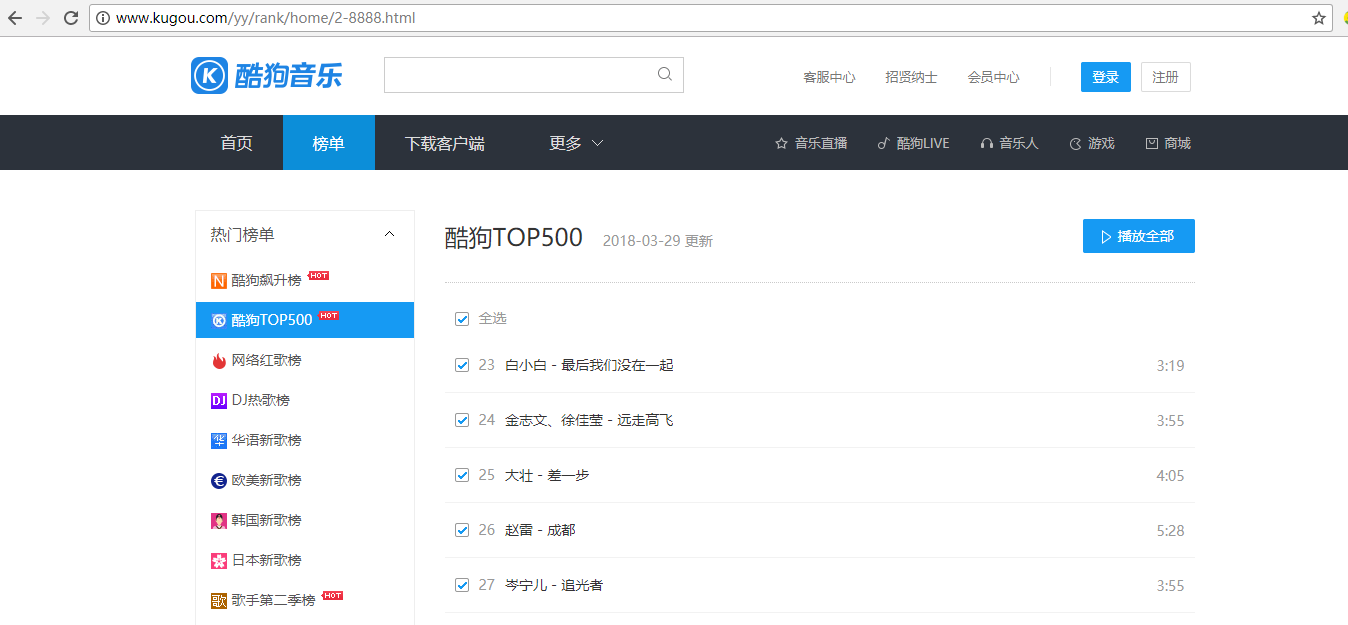
网页版的酷狗没有翻页的操作,所以不能看到后面页数的链接,根据第一页的链接,http://www.kugou.com/yy/rank/home/1-8888.html 我们尝试把链接里面的数字1改为2,果然跳转到第二页去了,这样就好办了,每页显示22条歌曲,所以经过计算,需要23条url链接,后面自己手动创建url
具体的操作和解释都下面代码中
# -*- encoding:utf8 -*-
import requests
from bs4 import BeautifulSoup
import itertools
import time
# 请求头,用来伪装为浏览器
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
# 定义获取信息的函数
def get_info(url):
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,"lxml")
# 排名
ranks = soup.select("span.pc_temp_num")
# 标题
titles = soup.select("div.pc_temp_songlist > ul > li > a")
# 时间
times = soup.select("span.pc_temp_tips_r > span")
# itertools.izip()函数可以平行的迭代多个数组,python2.7里面用izip(),3.6版本的则用zip()更好
for rank,title,time in itertools.izip(ranks,titles,times):
data = {
"rank":rank.text.strip(),
# 字符串的分片
"singer":title.text.split("-")[0],
"song":title.text.split("-")[1],
"time":time.text.strip(),
"href":title.get("href")
}
print data
# 程序的入口
if __name__ == "__main__":
# 创建多页的url
urls = ["http://www.kugou.com/yy/rank/home/{}-8888.html".format(number) for number in range(1,24)]
for i in urls:
get_info(i)
# 休眠2秒
time.sleep(2)
# 下面的代码可以更好的理解["http://www.kugou.com/yy/rank/home/{}-8888.html".format(number) for number in range(1,24)]
# for i in range(1,23):
# urls = ["http://www.kugou.com/yy/rank/home/{}-8888.html".format(i)]
# print urls