爬取网络数据
1.1首先读取网站`
https://www.kugou.com/yy/rank/home/1-6666.html?from=rank`
1.2定义用beautifulsoup选取HTML代码的文字部分:
def explain_HTML(mylist, html):
soup = BeautifulSoup(html,'html.parser')
songs = soup.select('div.pc_temp_songlist > ul > li > a')
ranks = soup.select('span.pc_temp_num')
times = soup.select('span.pc_temp_time')
for rank,song,time in zip(ranks,songs,times):
data = [
rank.get_text().strip(),
song.get_text().split("-")[1],
song.get_text().split("-")[0],
time.get_text().strip()
]
mylist.append(data)
12345678910111213
##为了使得打印展示的结果更加美观,应当调整打印的数据格式:
def print_HTML(mylist):
for i in range(500):
x = mylist[i]
with open("D:\Anew\kugou.txt",'a',encoding = 'UTF-8') as f:
f.write("{0:<10}\t{1:{4}<25}\t{2:{4}<20}\t{3:<10}\n".format(x[0],x[1],x[2],x[3],chr(12288)))
12345
为防止爬虫速度访问快而导致的爬取失败设立time.sleep(1)函数来进行预防上述风险。
1.4爬取结果展示如下:

1.5代码展示
import requests
from bs4 import BeautifulSoup
import time
def get_HTML(url):
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36",
"referer": "https://www.kugou.com/yy/rank/home/1-6666.html?from=rank"
}
try:
r = requests.get(url,headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def explain_HTML(mylist, html):
soup = BeautifulSoup(html,'html.parser')
songs = soup.select('div.pc_temp_songlist > ul > li > a')
ranks = soup.select('span.pc_temp_num')
times = soup.select('span.pc_temp_time')
for rank,song,time in zip(ranks,songs,times):
data = [
rank.get_text().strip(),
song.get_text().split("-")[1],
song.get_text().split("-")[0],
time.get_text().strip()
]
mylist.append(data)
def print_HTML(mylist):
for i in range(500):
x = mylist[i]
with open("D:\Anew\kugou.json",'a',encoding = 'UTF-8') as f:
f.write("{0:<10}\t{1:{4}<25}\t{2:{4}<20}\t{3:<10}\n".format(x[0],x[1],x[2],x[3],chr(12288)))
if __name__ == '__main__':
url_0 = 'http://www.kugou.com/yy/rank/home/'
url_1 = '-8888.html'
mylist = []
with open("D:\Anew\kugou.json",'a',encoding = "UTF-8") as f:
f.write("{0:<10}\t{1:{4}<25}\t{2:{4}<20}\t{3:<10}\n".format("排名","歌曲","歌手","时间",chr(12288)))
for j in range(1,24):
url = url_0 + str(j) + url_1
html = get_HTML(url)
explain_HTML(mylist, html)
print_HTML(mylist)
time.sleep(1)
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051
1.6以json转码前文档应该为

在在线解析json工具展示应该为:

通过代码运行检验代码展示如下:
with open("D://Anew//Kugou.json", 'r', encoding="utf-8") as rdf:
json_data=json.load(rdf)
print('数据展示:', json_data)
123

编程生成CSV文件并转换成JSon格式
将信息以数组的形式进行编码录入
import csv
test = [["姓名", "性别","籍贯","系别"],
["张迪", "男","重庆","计算机系"],
["兰博", "男","江苏","通信工程系"],
["黄飞", "男","四川","物联网系"],
["邓玉春", "女","陕西","计算机系"],
["周丽", "女","天津","艺术系"],
["李云", "女","上海","外语系"]
]
with open('信息录入.csv', 'w',encoding="utf8") as file:
csvwriter = csv.writer(file, lineterminator='\n')
csvwriter.writerows(test)
123456789101112
2.2 csv进行代码转换为json格式
import csv,json
csvfile = open('D:\\Anew\\test.csv','r')
jsonfile = open('D:\\Anew\\test.json','w')
fieldnames = ('姓名','性别','籍贯','系别')
reader = csv.DictReader (csvfile,fieldnames)
for row in reader:
json.dump(row,jsonfile)
jsonfile.write('\n')
12345678910
由于json文件自带加密效果,因此需要在网上找到json的格式化校验工具。本次使用的是BEJSON工具,校验展示图如下:
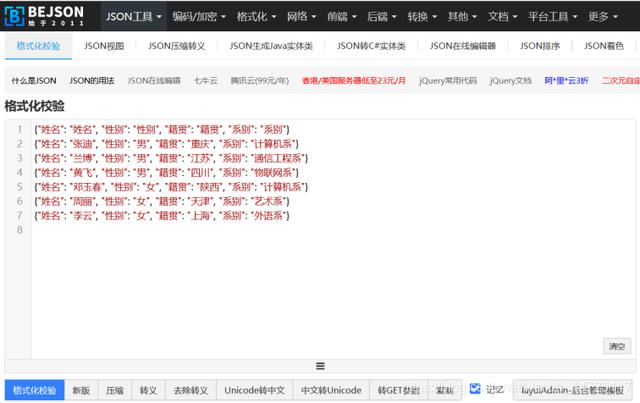
2.3查询文件中女生信息
import json
with open('D:\\Anew\\名单.json','r') as f:
for line in f.readlines():
line=json.loads(line)
if(line['性别']=='女'):
print(line)
123456

XML格式文件与JSon的转换
3.1(1)读取以下XML格式的文件,内容如下:
<?xml version=”1.0” encoding=”gb2312”> <图书> <书名>红楼梦
完整项目代码获取点这