翻译局部敏感哈希(LSH)算法的简介文章(Locality-Sensitive Hashing for Finding Nearest Neighbors),按段落整合,每段后面的名字对应原文章的段落标题
P1: NULL(开头无名段落)
网络使得我们在指尖即可访问大量精彩丰富的数据,我们可以轻松获取大量的图片,视频,歌曲。但是即便计算速度飞速提升,也无法满足遍历所有数据的要求(O(N)复杂度也无法实现,数据量量太大,算力不足)
本文对名为局部敏感哈希(locality-sensitive hashing, LSH)的技术进行简介,通过该算法可以在大数据库中迅速检索出相似的数据项。该算法属于随机算法的一种,随机算法不会提供一个完全准确的答案,而是提供一个高可信的答案或者是一个与准确答案相近的一个结果。通过增加算力,这个可信度可以提高到任何目标阈值
P2: RELEVANCE & PREREQUISITES(背景介绍和知识前提)
有非常多的问题都和寻找相似数据项有关。通常以在数据映射空间中寻找某一项的最近邻来解决这些问题。问题说起来简单,但是如果在数据量大,数据项复杂(简单理解为数据维度高),时间复杂度也是会随着数量的增加和数据的复杂而线性增加。对于高维大批量数据,LSH是一个能够根据查询数据项获取库中相似数据项的有效算法。通过检索,LSH以小概率返回错误结果的代价降低计算复杂度。
阅读本文需要具备简单集合推理和些许概率的知识,如果了解高维数据空间的相关基本概念自然更好。
P4: PROBLEM STATEMENT(问题陈述)
给定一个数据点,我们希望能够在数据库中找到那个和查询输入最近的数据点。对于任意查询数据点,我们都希望可以以1- δ的高概率返回最近邻数据点。
从概念角度,这个问题可以通过计算与查询数据点的距离遍历所有的数据点的方式解决。然而,数据库可能包含百万条数据,每条数据都是是一个高维向量,因此,如何找到一个不依赖线形搜索的的方法十分重要。目前为止,不依赖线形搜索的方法包括树(tree)算法和哈希(hashes)算法。
P5: TREE(树算法)
通过对数据构造树,输入查询数据点时,我们可以从根部开始查询,如果查询数据点是否在当前节点的左子树还是右子树,来递归查询检索最近邻。树构造得均匀平衡,可在O(logN)时间内解决问题,N为数据项条数。一维空间,这种搜索便是二分搜索。多维空间,这种树算法思想得实现便是k-d tree算法(该算法相关论文翻译后续文章讲解)。多维空间中k-d tree算法会在搜索空间维度高于某阈值得情况下性能下降,几乎以测试所有数据点,O(N)复杂度告终。
P6: HASHES(哈希算法)
通过构造哈希表(哈希表是一种数据结构,能够让我们在键值对中快速映射),给定一个查询点(看作标识),根据该标识ID生成一个对应得均匀分布的伪随机值,该随机值即为数据库中的索引。如果键的空间十分大但是表中索引少即映射空间小,则会出现碰撞,俩键对应同一值,如果碰撞,有相关解决方案即允许多个键对应一个哈希的情况。
一个好的哈希表可以在O(N)存储要求下实现O(1)时间的查找。当然,一个好的哈希算法可以将相近的数据项映射到不同的数据桶中(伪随机数是均匀分布的,所以一点变化也会截然不同)。这使得哈希算法可以查询到精确的唯一结果,所以,为了找到相近结果,我们使用局部敏感哈希(LSH)算法。
P7: SOLUTION 解决方法
LSH算法基于一种简单的思想,如果两个数据点距离很近,那么经过映射后,这两个点依然很近。
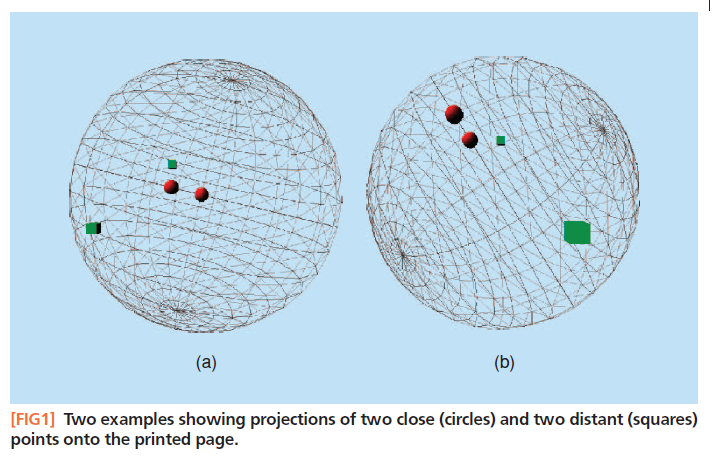
看图一这个例子,在球面上的两个点紧邻,当球面被映射到二位空间中时,无论怎样旋转球面,球面上原本紧邻的两点映射后还是紧邻的两个点。但是对于球面上相聚很远的点,可能在某些角度的映射后在二维平面中相聚很近,也有可能依然保持很远的距离。我们将描述不同类型的映射操作子以将高维球面映射到平面的例子做比喻。
为了继续扩展这个基本思想,我们以一个将高维数据点映射到低维子平面随机映射作为开始。首先,我们注意到那些和我们查询数据点邻近的数据点。然后,我们从多个不同的视角进行映射并记录映射后相邻的点集。我们存储一个数据点列表,列表中的点在多个映射中与已知点邻近。