机器学习八股
- 项目概述
- 获取数据
- 发现并可视化数据,发现规律
- 为机器学习算法准备数据
- 选择模型,进行训练
- 微调模型
- 给出解决方案
- 部署、监控、维护系统
1 项目概述
利用
加州普查数据,建立一个加州房价模型
这个数据包含每个街区组的人口、收入中位数、房价中位数等指标
模型要利用这个数据进行学习,然后根据其它指标,预测任何街区的的房价中位数
1.1 划分问题
监督学习
回归任务
批量学习
1.2 选择性能指标
均方根误差
平方绝对误差
1.3 核实检验
确信他们需要的就是
实际的价格,而不是分类
2 获取数据
2.1 创建工作空间
virtualenv
2.2 下载数据
获取数据自动化的
fetch_housing_data函数
tarfile
os.path
os.path.makedirs
import os
import tarfile
import urllib
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_PATH = os.path.join("datasets", "housing") # 把目录和文件名合成一个路径
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path): # 判断路径是否为目录
os.makedirs(housing_path) # 递归创建目录
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path) # 将URL检索到磁盘上的临时位置
housing_tgz = tarfile.open(tgz_path) # 打开
housing_tgz.extractall(path=housing_path) # 解压
housing_tgz.close() # 关闭
fetch_housing_data()
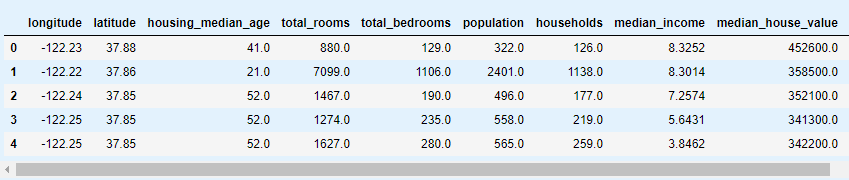
加载数据的
load_housing_data函数
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path) # 加载数据
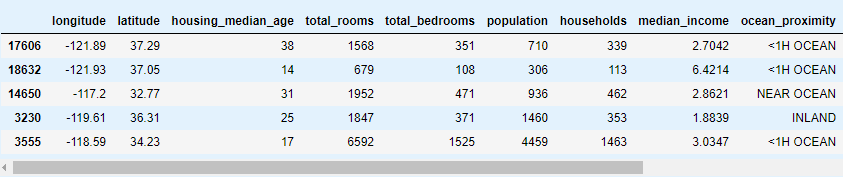
housing = load_housing_data()
housing.head()
2.3 快速查看数据结构
总行数、属性类型和非空值的个数
housing.info()

总房间数只有20433个非空值 -> 缺失值处理

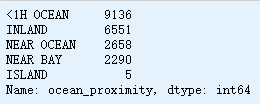
查看
距离大海距离列类别
housing['ocean_proximity'].value_counts()
展示
数据属性概括
housing.describe()

画出每个数值属性的
直方图
housing.hist(bins=50, figsize=(20, 16))

- 收入中位数不是美元(预处理过)
- 房屋年龄中位数和
房屋价值中位数(目标属性)都被设了上限 - 属性值度量不统一(特征缩放)
2.4 创建测试集
设置随机生成树种子
import numpy as np
np.random.seed(42)
切割数据集(仅供说明)
backup = housing.copy() # 副本
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
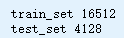
train_set, test_set = split_train_test(housing, 0.2)
print('train_set', len(train_set))
print('test_set', len(test_set))
hashlib.md5 # md5算法
hash.digeset() # 返回update()到目前为止传递给该方法的数据的摘要。
这是一个字节对象,其大小digest_size可能包含从0到255的整个范围内的字节
使用每个实例的ID来判 定这个实例是否应该放入测试集(假设每个实例都有唯一并且不变的ID)。
计算出每个实例ID的哈希值,只保留其最后一个字节,如果该值小于等于 51(约为 256 的 20%),就将其放入测试集。
这样可以保证在多次运行中,测试集保持不变,即使更新了数据集。
新的测试集会包含新实例中的20%,但不会有之前位于训练集的实例。
housing = backup
housing

import hashlib
def test_set_check(identifier, test_ratio, hash=hashlib.md5): # md5算法
return hash(np.int64(identifier)).digest()[-1] < 256 * test_ratio
def split_train_test_by_id(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio)) # 应用函数
return data.loc[~in_test_set], data.loc[in_test_set] # 布尔索引
行索引作为ID
housing_with_id = housing.reset_index() # 设置索引
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
test_set[['index']]
维度+经度结合生成一个ID
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
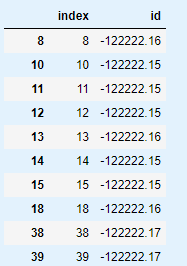
test_set[['index', 'id']]
切割数据集
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
test_set.head()

收入中位数是预测房价的重要属性
housing["median_income"].hist()

创建收入类别属性 #1
对收入中位数数据进行处理(数据离散化)
pd.cut # 将Bin值转换为离散区间
housing["income_cat"] = pd.cut(housing["median_income"],
bins=[0., 1.5, 3.0, 4.5, 6., np.inf],
labels=[1, 2, 3, 4, 5])
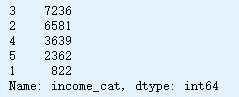
housing["income_cat"].value_counts()
housing["income_cat"].hist()

收入类别属性 #2
np.ceil
pd.DataFrame.where
backup2 = housing["income_cat"].copy
housing["income_cat"] = np.ceil(housing['median_income'] / 1.5) # 收入类别属性
housing["income_cat"].where(housing['income_cat'] < 5, 5.0, inplace=True)
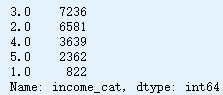
housing["income_cat"].value_counts()
housing["income_cat"].hist()

分层采样
sklearn.model_selection.StratifiedShuffleSplit
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
检查结果是否符合预期
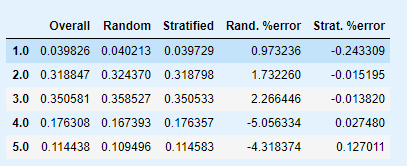
查看数据集中收入分类比例
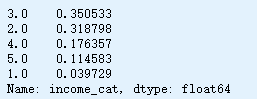
strat_test_set["income_cat"].value_counts() / len(strat_test_set)
housing["income_cat"].value_counts() / len(housing)
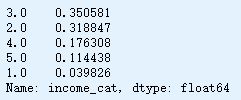
分层采样和纯随机采样的样本偏差比较
def income_cat_proportions(data):
return data["income_cat"].value_counts() / len(data)
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
compare_props = pd.DataFrame({
"Overall": income_cat_proportions(housing),
"Random": income_cat_proportions(test_set),
"Stratified": income_cat_proportions(strat_test_set)
}).sort_index()
compare_props["Rand. %error"] = 100 * compare_props["Random"] / compare_props["Overall"] - 100
compare_props["Strat. %error"] = 100 * compare_props["Stratified"] / compare_props["Overall"] - 100
compare_props
删除
income_cat属性,使数据回到初始状态
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)
3 数据探索和可视化、发现规律
3.1 地理数据可视化
创建副本,以免损伤训练集
housing = strat_train_set.copy()
数据地理位置信息散点图
housing.plot(kind="scatter", x="longitude", y="latitude")

显示高密度区域的散点图
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)

加州房价
import matplotlib.pyplot as plt
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population", figsize=(10,7), # s: 每个圈的半径表示街区的人口
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True, # c: 颜色代表价格 cmp: jet颜色图
sharex=False)
plt.legend()

下载
California地图图片
images_path = os.path.join("images", "end_to_end_project")
os.makedirs(images_path, exist_ok=True)
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
filename = "california.png"
print("Downloading", filename)
url = DOWNLOAD_ROOT + "images/end_to_end_project/" + filename
urllib.request.urlretrieve(url, os.path.join(images_path, filename))
查看图片
import matplotlib.image as mpimg
california_img=mpimg.imread(os.path.join(images_path, filename))
plt.imshow(california_img, extent=[-124.55, -113.80, 32.45, 42.05], alpha=0.5,
cmap=plt.get_cmap("jet"))
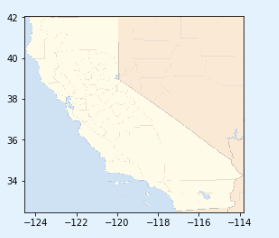
california_img=mpimg.imread(os.path.join(images_path, filename))
ax = housing.plot(kind="scatter", x="longitude", y="latitude", figsize=(10,7),
s=housing['population']/100, label="Population",
c="median_house_value", cmap=plt.get_cmap("jet"),
colorbar=False, alpha=0.4,
)
plt.imshow(california_img, extent=[-124.55, -113.80, 32.45, 42.05], alpha=0.5,
cmap=plt.get_cmap("jet"))
plt.ylabel("Latitude", fontsize=14)
plt.xlabel("Longitude", fontsize=14)
prices = housing["median_house_value"]
tick_values = np.linspace(prices.min(), prices.max(), 11)
cbar = plt.colorbar()
cbar.ax.set_yticklabels(["$%dk"%(round(v/1000)) for v in tick_values], fontsize=14)
cbar.set_label('Median House Value', fontsize=16)
plt.legend(fontsize=16)
plt.show()

靠海距离&人口密度与房价密切相关
3.2 查找关联
计算每对属性间的标准相关系数(皮尔逊相关系数)
pd.DataFrame.corr
corr_matrix = housing.corr()
查看每个和房价的关联度
corr_matrix["median_house_value"].sort_values(ascending=False)

检测属性间的标准相关系数(可视化)
pandas.plotting.scatter_matrix
from pandas.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))

收入中位数vs房价中位数
housing.plot(kind="scatter", x="median_income", y="median_house_value",
alpha=0.1)
plt.axis([0, 16, 0, 550000])

3.3 属性组合试验
创建新属性
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)

bedrooms_per_roomvs房价中位数
housing.plot(kind="scatter", x="bedrooms_per_room", y="median_house_value",
alpha=0.2)
plt.axis([0, 5, 0, 520000])
plt.show()

卧室数/总房间数的比例越低,房价越高
4 为机器学习算法准备数据
4.1 数据清洗
housing = strat_train_set.drop("median_house_value", axis=1) # 删除标签
housing_labels = strat_train_set["median_house_value"].copy()
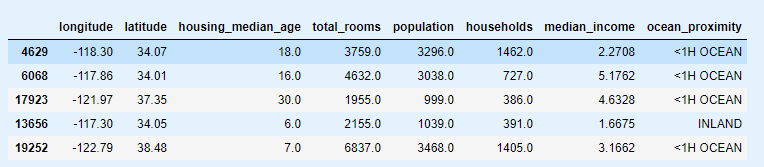
处理特征缺失
total_bedrooms属性
sample_incomplete_rows = housing[housing.isnull().any(axis=1)].head()
sample_incomplete_rows

a. 去掉对应街区
sample_incomplete_rows.dropna(subset=["total_bedrooms"])

b. 去掉整个属性
sample_incomplete_rows.drop("total_bedrooms", axis=1)
c. 进行赋值(0 平均值 中位数等)
median = housing["total_bedrooms"].median()
sample_incomplete_rows["total_bedrooms"].fillna(median, inplace=True)
sample_incomplete_rows

from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
删除文本属性,因为中值只能根据数值属性计算
housing_num = housing.drop("ocean_proximity", axis=1)
imputer拟合到训练数据
imputer.fit(housing_num)
imputer.statistics_ # 每个属性的中位值

检查是否与手动计算每个属性的中值相同
housing_num.median().values

转换训练集
X = imputer.transform(housing_num)
housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index=housing.index)
housing_tr.loc[sample_incomplete_rows.index.values] # 查看效果
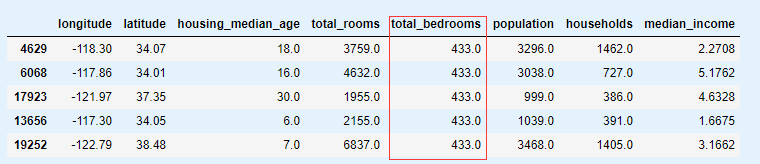
imputer.strategy

housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index=housing_num.index)
housing_tr.head()
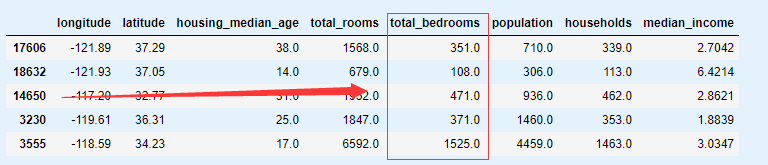
4.2 处理文本和类别属性
预处理分类输入特性,
海洋接近度
housing_cat = housing[["ocean_proximity"]]
housing_cat.head(10)
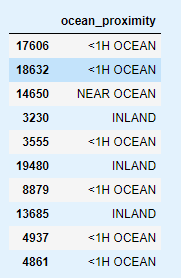
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
housing_cat_encoded[:10]

ordinal_encoder.categories_

from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
housing_cat_1hot

默认情况下,OneHotEncoder类返回稀疏数组,但如果需要,我们可以通过调用toarray()方法将其转换为密集数组
或者,可以在创建OneHotEncoder时设置
sparse=False
cat_encoder = OneHotEncoder(sparse=False)
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
housing_cat_1hot
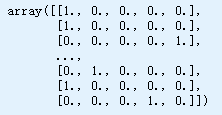
cat_encoder.categories_

4.3 自定义转换器
创建一个自定义转换器来添加额外的属性
from sklearn.base import BaseEstimator, TransformerMixin
# column index
rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True): # no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X):
rooms_per_household = X[:, rooms_ix] / X[:, households_ix]
population_per_household = X[:, population_ix] / X[:, households_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)
housing_extra_attribs = pd.DataFrame(
housing_extra_attribs,
columns=list(housing.columns)+["rooms_per_household", "population_per_household"],
index=housing.index)
housing_extra_attribs.head()
4.4 特征缩放
4.5 转换流水线
构建一个管道来预处理数值属性
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
housing_num_tr

from sklearn.compose import ColumnTransformer
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", OneHotEncoder(), cat_attribs),
])
housing_prepared = full_pipeline.fit_transform(housing)
print(housing_prepared.shape)
housing_prepared

将所有这些组件连接到一个大管道中,该管道将预处理数值和分类有限元分析
from sklearn.base import BaseEstimator, TransformerMixin
# Create a class to select numerical or categorical columns
class OldDataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names].values
作为参考,以下是基于DataFrameSelector转换器(仅选择Pandas DataFrame列的子集)和FeatureUnion的旧解决方案
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
old_num_pipeline = Pipeline([
('selector', OldDataFrameSelector(num_attribs)),
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
old_cat_pipeline = Pipeline([
('selector', OldDataFrameSelector(cat_attribs)),
('cat_encoder', OneHotEncoder(sparse=False)),
])
from sklearn.pipeline import FeatureUnion
old_full_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", old_num_pipeline),
("cat_pipeline", old_cat_pipeline),
])
old_housing_prepared = old_full_pipeline.fit_transform(housing)
old_housing_prepared

结果与
ColumnTransformer相同
np.allclose #两个数组在一个公差内按元素相等
np.allclose(housing_prepared, old_housing_prepared)
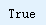
5 选择并训练模型
5.1 在训练集上训练和评估
在几个训练实例上尝试完整的预处理管道
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
some_data = housing.iloc[:5] # 数据
some_labels = housing_labels.iloc[:5] # 标签
some_data_prepared = full_pipeline.transform(some_data) # 管道处理数据
print("Predictions:", list(lin_reg.predict(some_data_prepared)))
print("Labels:", list(some_labels))
print('error:', list((lin_reg.predict(some_data_prepared)) - (some_labels)))

计算回归模型
RMSE
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
lin_rmse

计算回归模型
MAE
from sklearn.metrics import mean_absolute_error
lin_mae = mean_absolute_error(housing_labels, housing_predictions)
lin_mae

housing_labels.hist()

median_housing_values位于 120000 到 265000 美元之间,因此预测误差 68628 美元
欠拟合
- 选择一个更强大的模型,带有更多参数(决策树)
- 用更好的特征训练学习算法(特征工程)
- 减小对模型的限制(减小正则化超参数)
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(random_state=42)
tree_reg.fit(housing_prepared, housing_labels)
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
tree_rmse
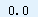
误差 = 0.0
过拟合
- 简化模型
- 通过选择一个参数更少的模型(使用线性模型,
高阶多项式模型) - 减少训练数据的属性数
- 限制一下模型(正则化)
- 通过选择一个参数更少的模型(使用线性模型,
- 收集更多的训练数据
- 减小训练数据的噪声(修改数据错误和去除异常值)
5.2 使用交叉验证做更加的评估
决策树模型
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)
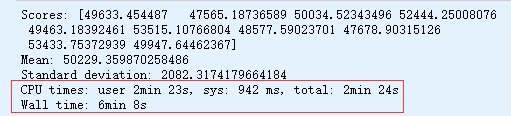
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
display_scores(tree_rmse_scores)

线性回归模型
lin_scores = cross_val_score(lin_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
lin_rmse_scores = np.sqrt(-lin_scores)
display_scores(lin_rmse_scores)

vs = pd.DataFrame({'Model': pd.Series(['tree_rmse_scores', 'lin_rmse_scores']),
'Mean': pd.Series([tree_rmse_scores.mean(), lin_rmse_scores.mean()]),
'Standard deviation': pd.Series([tree_rmse_scores.std(), lin_rmse_scores.std()])})
vs

import seaborn as sns
sns.barplot(vs.Model, vs.Mean)

sns.barplot(vs.Model, vs['Standard deviation'])

随机森林
%%time
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor(n_estimators=100, random_state=42)
forest_reg.fit(housing_prepared, housing_labels)
housing_predictions = forest_reg.predict(housing_prepared)
forest_mse = mean_squared_error(housing_labels, housing_predictions)
forest_rmse = np.sqrt(forest_mse)

forest_rmse

%%time
forest_scores = cross_val_score(forest_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
forest_rmse_scores = np.sqrt(-forest_scores)
display_scores(forest_rmse_scores)
支持向量回归
from sklearn.svm import SVR
svm_reg = SVR(kernel="linear")
svm_reg.fit(housing_prepared, housing_labels)
housing_predictions = svm_reg.predict(housing_prepared)
svm_mse = mean_squared_error(housing_labels, housing_predictions)
svm_rmse = np.sqrt(svm_mse)
svm_rmse

6 微调模型
6.1 网格搜索
from sklearn.model_selection import GridSearchCV
param_grid = [
# 尝试12(3×4)个超参数组合
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
# 然后尝试6个(2×3)组合,bootstrap设置为False
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor(random_state=42)
# 训练5次,总共(12+6)*5=90轮
grid_search = GridSearchCV(forest_reg, param_grid, cv=5, # 拆分策略 (int -> 分层折叠数)
scoring='neg_mean_squared_error', # 评分参数
return_train_score=True) #
grid_search.fit(housing_prepared, housing_labels)

获得参数的最佳组合
grid_search.best_params_

grid_search.best_estimator_

查看网格搜索期间测试的每个超参数组合的得分
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)

最佳方案:'max_features': 6, 'n_estimators': 30
RMSE: 50811
结果
pd.DataFrame(grid_search.cv_results_)

6.2 随机搜索
网格搜索:尝试所有可能的组合
随机搜索:选择每个超参数的一个随机值的特定数量的随机组合
* 探索范围大于网格搜索
* 通过设定搜索次数,控制超参数搜索的计算量
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {
'n_estimators': randint(low=1, high=200),
'max_features': randint(low=1, high=8),
}
forest_reg = RandomForestRegressor(random_state=42)
rnd_search = RandomizedSearchCV(forest_reg, param_distributions=param_distribs,
n_iter=10, cv=5, scoring='neg_mean_squared_error', random_state=42)
rnd_search.fit(housing_prepared, housing_labels)

6.3 集成方法
6.4 分析最佳模型和它们的误差
cvres = rnd_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)

feature_importances = grid_search.best_estimator_.feature_importances_
feature_importances

将重要性分数和属性名放到一起
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
cat_encoder = full_pipeline.named_transformers_["cat"]
cat_one_hot_attribs = list(cat_encoder.categories_[0])
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse=True)

丢弃不重要的特征(貌似只留ocean_proximity的ISLAND就OK了)
清洗异常值
增加更多的特征
6.5 用测试集评估系统
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
final_rmse

计算测试RMSE的95%置信区间
stats.t.interval # 中位数周围面积相等的置信区间
stats.sem # 计算平均值的标准误差(或测量)输入数组中的值
from scipy import stats
confidence = 0.95
squared_errors = (final_predictions - y_test) ** 2
np.sqrt(stats.t.interval(confidence, len(squared_errors) - 1,
loc=squared_errors.mean(),
scale=stats.sem(squared_errors)))

手动计算间隔
stats.t.ppf # 给定RV的q处的百分点函数(与“cdf”相反)
m = len(squared_errors)
mean = squared_errors.mean()
tscore = stats.t.ppf((1 + confidence) / 2, df=m - 1)
tmargin = tscore * squared_errors.std(ddof=1) / np.sqrt(m)
np.sqrt(mean - tmargin), np.sqrt(mean + tmargin)

使用z分数而不是t分数
stats.norm.ppf # 返回分位点函数
zscore = stats.norm.ppf((1 + confidence) / 2)
zmargin = zscore * squared_errors.std(ddof=1) / np.sqrt(m)
np.sqrt(mean - zmargin), np.sqrt(mean + zmargin)

7 启动、监控、维护系统
- 接入输入数据源,并编写测试
- 监控
- 评估系统
8 实践!
额外材料
准备和预测的完整管道
full_pipeline_with_predictor = Pipeline([
("preparation", full_pipeline),
("linear", LinearRegression())
])
full_pipeline_with_predictor.fit(housing, housing_labels)
full_pipeline_with_predictor.predict(some_data)

使用joblib的模型持久性
my_model = full_pipeline_with_predictor
!pip install joblib
import joblib
joblib.dump(my_model, "my_model.pkl") # DIFF
#...
my_model_loaded = joblib.load("my_model.pkl") # DIFF
随机搜索的SciPy分布示例
from scipy.stats import geom, expon
geom_distrib=geom(0.5).rvs(10000, random_state=42)
expon_distrib=expon(scale=1).rvs(10000, random_state=42)
plt.hist(geom_distrib, bins=50)
plt.show()
plt.hist(expon_distrib, bins=50)
plt.show()

