首先来resnets_utils.py,里面有手势数字的数据集载入函数和随机产生mini-batch的函数,代码如下:
import os
import numpy as np
import tensorflow as tf
import h5py
import math
def load_dataset():
train_dataset = h5py.File('datasets/train_signs.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
# print(train_set_x_orig.shape)
# print(train_set_y_orig.shape)
test_dataset = h5py.File('datasets/test_signs.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
# print(test_set_x_orig.shape)
# print(test_set_y_orig.shape)
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
#load_dataset()
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
"""
Creates a list of random minibatches from (X, Y)
Arguments:
X -- input data, of shape (input size, number of examples) (m, Hi, Wi, Ci)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples) (m, n_y)
mini_batch_size - size of the mini-batches, integer
seed -- this is only for the purpose of grading, so that you're "random minibatches are the same as ours.
Returns:
mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
"""
m = X.shape[0] # number of training examples
mini_batches = []
np.random.seed(seed)
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation,:,:,:]
shuffled_Y = Y[permutation,:]
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = math.floor(m/mini_batch_size) # number of mini batches of size mini_batch_size in your partitionning
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[k * mini_batch_size : k * mini_batch_size + mini_batch_size,:,:,:]
mini_batch_Y = shuffled_Y[k * mini_batch_size : k * mini_batch_size + mini_batch_size,:]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
mini_batch_X = shuffled_X[num_complete_minibatches * mini_batch_size : m,:,:,:]
mini_batch_Y = shuffled_Y[num_complete_minibatches * mini_batch_size : m,:]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
def convert_to_one_hot(Y, C):
Y = np.eye(C)[Y.reshape(-1)].T
return Y
def forward_propagation_for_predict(X, parameters):
"""
Implements the forward propagation for the model: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX
Arguments:
X -- input dataset placeholder, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3"
the shapes are given in initialize_parameters
Returns:
Z3 -- the output of the last LINEAR unit
"""
# Retrieve the parameters from the dictionary "parameters"
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
W3 = parameters['W3']
b3 = parameters['b3']
# Numpy Equivalents:
Z1 = tf.add(tf.matmul(W1, X), b1) # Z1 = np.dot(W1, X) + b1
A1 = tf.nn.relu(Z1) # A1 = relu(Z1)
Z2 = tf.add(tf.matmul(W2, A1), b2) # Z2 = np.dot(W2, a1) + b2
A2 = tf.nn.relu(Z2) # A2 = relu(Z2)
Z3 = tf.add(tf.matmul(W3, A2), b3) # Z3 = np.dot(W3,Z2) + b3
return Z3
def predict(X, parameters):
W1 = tf.convert_to_tensor(parameters["W1"])
b1 = tf.convert_to_tensor(parameters["b1"])
W2 = tf.convert_to_tensor(parameters["W2"])
b2 = tf.convert_to_tensor(parameters["b2"])
W3 = tf.convert_to_tensor(parameters["W3"])
b3 = tf.convert_to_tensor(parameters["b3"])
params = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
x = tf.placeholder("float", [12288, 1])
z3 = forward_propagation_for_predict(x, params)
p = tf.argmax(z3)
sess = tf.Session()
prediction = sess.run(p, feed_dict = {x: X})
return prediction测试数据集,代码如下:
import resnets_utils
import cv2
train_x, train_y, test_x, test_y, classes=resnets_utils.load_dataset()
print('训练样本={}'.format(train_x.shape))
print('训练样本标签={}'.format(train_y.shape))
print('测试样本={}'.format(test_x.shape))
print('测试样本标签={}'.format(test_y.shape))
print('第五个样本={}'.format(train_y[0,5]))
cv2.imshow('1.jpg',train_x[5,:,:,:]/255)
cv2.waitKey()打印结果:可看出训练样本有1080个,size为(64,64,3),测试样本有120个,手势四是用4代替。

先测试第一个残差学习单元,模型如下:

代码如下:
from keras.layers import Dense,Flatten,Input,Activation,ZeroPadding2D,AveragePooling2D,BatchNormalization,Conv2D,Add,MaxPooling2D
from keras.models import Model
import matplotlib.pyplot as plt
from keras.preprocessing import image
from keras.applications.imagenet_utils import preprocess_input
import resnets_utils
import keras.backend as K
import numpy as np
from keras.initializers import glorot_uniform
import tensorflow as tf
def identity_block(X,f,filters,stage,block):
conv_name_base='res'+str(stage)+block+'_branch'
bn_name_base='bn'+str(stage)+block+'_branch'
F1,F2,F3=filters
X_shortcut=X
print('输入尺寸={}'.format(X.shape))
#first conv
X=Conv2D(filters=F1,kernel_size=(1,1),strides=(1,1),padding='valid',name=conv_name_base+'2a',
kernel_initializer=glorot_uniform(seed=0))(X)
print('输出尺寸={}'.format(X.shape))
X=BatchNormalization(axis=3,name=bn_name_base+'2a')(X)
X=Activation('relu')(X)
#second conv
X = Conv2D(filters=F2, kernel_size=(f, f), strides=(1, 1), padding='same', name=conv_name_base + '2b',
kernel_initializer=glorot_uniform(seed=0))(X)
print('输出尺寸={}'.format(X.shape))
X = BatchNormalization(axis=3, name=bn_name_base + '2b')(X)
X = Activation('relu')(X)
#third conv
X = Conv2D(filters=F3, kernel_size=(1, 1), strides=(1, 1), padding='valid', name=conv_name_base + '2c',
kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2c')(X)
print('输出尺寸={}'.format(X.shape))
#ResNet
X=Add()([X,X_shortcut])
X = Activation('relu')(X)
print('最终输出尺寸={}'.format(X.shape))
return X
def test_identity_block():
with tf.Session() as sess:
np.random.seed(1)
A_prev=tf.placeholder('float',[3,4,4,6])
X=np.random.randn(3,4,4,6)
A=identity_block(A_prev,f=2,filters=[2,4,6],stage=1,block='a')
init=tf.global_variables_initializer()
sess.run(init)
out=sess.run([A],feed_dict={A_prev:X,K.learning_phase():0})
if __name__=='__main__':
test_identity_block()打印结果:由此可见经过三层卷积,该残差单元的输出size和维度不变,因为原始输入未进行卷积,故只能这样才能进行特征融合。
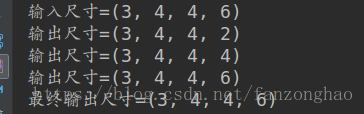
下面是输出维度会发生变化的,对原始输入X做了卷积变换再融合输出得到最终的输出,模型如下

代码如下:
from keras.layers import Dense,Flatten,Input,Activation,ZeroPadding2D,AveragePooling2D,BatchNormalization,Conv2D,Add,MaxPooling2D
from keras.models import Model
import matplotlib.pyplot as plt
from keras.preprocessing import image
from keras.applications.imagenet_utils import preprocess_input
import resnets_utils
import keras.backend as K
import numpy as np
from keras.initializers import glorot_uniform
import tensorflow as tf
def convolutional_block(X,f,filters,stage,block,s=2):
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
F1, F2, F3 = filters
X_shortcut = X
print('输入尺寸={}'.format(X.shape))
# first conv
X = Conv2D(filters=F1, kernel_size=(1, 1), strides=(s, s), padding='valid', name=conv_name_base + '2a',
kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2a')(X)
X = Activation('relu')(X)
print('输出尺寸={}'.format(X.shape))
# second conv
X = Conv2D(filters=F2, kernel_size=(f, f), strides=(1, 1), padding='same', name=conv_name_base + '2b',
kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2b')(X)
X = Activation('relu')(X)
print('输出尺寸={}'.format(X.shape))
#third conv
X = Conv2D(filters=8, kernel_size=(1, 1), strides=(1, 1), padding='valid', name=conv_name_base + '2c',
kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2c')(X)
X = Activation('relu')(X)
print('输出尺寸={}'.format(X.shape))
#ResNet
X_shortcut=Conv2D(filters=8, kernel_size=(1, 1), strides=(s, s), padding='valid', name=conv_name_base + '1',
kernel_initializer=glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis=3, name=bn_name_base + '1')(X_shortcut)
print('原始输入X经过变化的输出尺寸={}'.format(X.shape))
X = Add()([X, X_shortcut])
X = Activation('relu')(X)
print('最终输出尺寸={}'.format(X.shape))
return X
def test_convolutional_block():
#tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
A_prev=tf.placeholder('float',[3,4,4,6])
X=np.random.randn(3,4,4,6)
A=convolutional_block(A_prev,f=2,filters=[2,4,6],stage=1,block='a',s=2)
init = tf.global_variables_initializer()
sess.run(init)
out=sess.run(A,feed_dict={A_prev:X})
if __name__=='__main__':
#test_identity_block()
test_convolutional_block()打印结果:可看出原始输入改变size为(3,2,2,8)最终融合的输出也是(3,2,2,8),故此种残差单元能够解决输出尺寸和维度的问题。
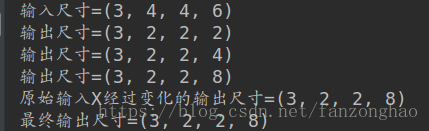
总体模型:其中BLOCK2值得是输出尺度和维度会变化的,BLOCK1指的是不会变化的。

下面用开始调用数据集:其中convolutional_block表示输出尺寸和维度会变化,identity_block表示输出与输入一样,模型如下,
代码如下:
from keras.layers import Dense,Flatten,Input,Activation,ZeroPadding2D,AveragePooling2D,BatchNormalization,Conv2D,Add,MaxPooling2D
from keras.models import Model
import matplotlib.pyplot as plt
from keras.preprocessing import image
from keras.applications.imagenet_utils import preprocess_input
import resnets_utils
import keras.backend as K
import numpy as np
from keras.initializers import glorot_uniform
import tensorflow as tf
import time
"""
获取数据 并将标签转换成one-hot
"""
def convert_data():
train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes=resnets_utils.load_dataset()
train_x=train_set_x_orig/255
test_x = test_set_x_orig / 255
train_y=resnets_utils.convert_to_one_hot(train_set_y_orig,6).T
test_y = resnets_utils.convert_to_one_hot(test_set_y_orig, 6).T
#print(train_y.shape)
return train_x,train_y,test_x,test_y
"""
三层卷积的 残差单元 输出尺寸和维度不会变化
"""
def identity_block(X,f,filters,stage,block):
conv_name_base='res'+str(stage)+block+'_branch'
bn_name_base='bn'+str(stage)+block+'_branch'
F1,F2,F3=filters
X_shortcut=X
# print('输入尺寸={}'.format(X.shape))
#first conv
X=Conv2D(filters=F1,kernel_size=(1,1),strides=(1,1),padding='valid',name=conv_name_base+'2a',
kernel_initializer=glorot_uniform(seed=0))(X)
# print('输出尺寸={}'.format(X.shape))
X=BatchNormalization(axis=3,name=bn_name_base+'2a')(X)
X=Activation('relu')(X)
#second conv
X = Conv2D(filters=F2, kernel_size=(f, f), strides=(1, 1), padding='same', name=conv_name_base + '2b',
kernel_initializer=glorot_uniform(seed=0))(X)
# print('输出尺寸={}'.format(X.shape))
X = BatchNormalization(axis=3, name=bn_name_base + '2b')(X)
X = Activation('relu')(X)
#third conv
X = Conv2D(filters=F3, kernel_size=(1, 1), strides=(1, 1), padding='valid', name=conv_name_base + '2c',
kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2c')(X)
# print('输出尺寸={}'.format(X.shape))
#ResNet
X=Add()([X,X_shortcut])
X = Activation('relu')(X)
# print('最终输出尺寸={}'.format(X.shape))
return X
"""
三层卷积的 残差单元 输出尺寸和维度会变化
"""
def convolutional_block(X,f,filters,stage,block,s=2):
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
F1, F2, F3 = filters
X_shortcut = X
# print('输入尺寸={}'.format(X.shape))
# first conv
X = Conv2D(filters=F1, kernel_size=(1, 1), strides=(s, s), padding='valid', name=conv_name_base + '2a',
kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2a')(X)
X = Activation('relu')(X)
# print('输出尺寸={}'.format(X.shape))
# second conv
X = Conv2D(filters=F2, kernel_size=(f, f), strides=(1, 1), padding='same', name=conv_name_base + '2b',
kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2b')(X)
X = Activation('relu')(X)
# print('输出尺寸={}'.format(X.shape))
#third conv
X = Conv2D(filters=F3, kernel_size=(1, 1), strides=(1, 1), padding='valid', name=conv_name_base + '2c',
kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base + '2c')(X)
X = Activation('relu')(X)
# print('输出尺寸={}'.format(X.shape))
#ResNet
X_shortcut=Conv2D(filters=F3, kernel_size=(1, 1), strides=(s, s), padding='valid', name=conv_name_base + '1',
kernel_initializer=glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis=3, name=bn_name_base + '1')(X_shortcut)
# print('原始输入X经过变化的输出尺寸={}'.format(X.shape))
X = Add()([X, X_shortcut])
X = Activation('relu')(X)
# print('最终输出尺寸={}'.format(X.shape))
return X
"""
50层残差网络
"""
def ResNet50(input_shape=(64,64,3),classes=6):
X_input=Input(input_shape)
print('输入尺寸={}'.format(X_input.shape))
X=ZeroPadding2D((3,3))(X_input)
print('补完零尺寸={}'.format(X.shape))
#Stage 1
X=Conv2D(filters=64,kernel_size=(7,7),strides=(2,2),name='conv1',
kernel_initializer=glorot_uniform(seed=0))(X)
print('第一次卷积尺寸={}'.format(X.shape))
X=BatchNormalization(axis=3,name='bn_conv1')(X)
X=Activation('relu')(X)
X=MaxPooling2D(pool_size=(3,3),strides=(2,2))(X)
print('第一次池化尺寸={}'.format(X.shape))
#Stage 2
X=convolutional_block(X,f=3,filters=[64,64,256],stage=2,block='a',s=1)
print('第一次convolutional_block尺寸={}'.format(X.shape))
X = identity_block(X, f=3, filters=[64, 64, 256], stage=2, block='b')
X = identity_block(X, f=3, filters=[64, 64, 256], stage=2, block='c')
print('两次identity_block尺寸={}'.format(X.shape))
#Stage 3
X = convolutional_block(X, f=3, filters=[128, 128, 512], stage=3, block='a', s=2)
print('第二次convolutional_block尺寸={}'.format(X.shape))
X = identity_block(X, f=3, filters=[128, 128, 512], stage=3, block='b')
X = identity_block(X, f=3, filters=[128, 128, 512], stage=3, block='c')
X = identity_block(X, f=3, filters=[128, 128, 512], stage=3, block='d')
print('三次identity_block尺寸={}'.format(X.shape))
#Stage 4
X = convolutional_block(X, f=3, filters=[256, 256, 1024], stage=4, block='a', s=2)
print('第三次convolutional_block尺寸={}'.format(X.shape))
X = identity_block(X, f=3, filters=[256, 256, 1024], stage=4, block='b')
X = identity_block(X, f=3, filters=[256, 256, 1024], stage=4, block='c')
X = identity_block(X, f=3, filters=[256, 256, 1024], stage=4, block='d')
X = identity_block(X, f=3, filters=[256, 256, 1024], stage=4, block='e')
X = identity_block(X, f=3, filters=[256, 256, 1024], stage=4, block='f')
print('五次identity_block尺寸={}'.format(X.shape))
#Stage 5
X = convolutional_block(X, f=3, filters=[512, 512, 2048], stage=5, block='a', s=2)
print('第四次convolutional_block尺寸={}'.format(X.shape))
X = identity_block(X, f=3, filters=[512, 512, 2048], stage=5, block='b')
X = identity_block(X, f=3, filters=[512, 512, 2048], stage=5, block='c')
print('两次identity_block尺寸={}'.format(X.shape))
#Pool
X=AveragePooling2D(pool_size=(2,2))(X)
print('最后一次平均池化尺寸={}'.format(X.shape))
#OutPut Flatten+FULLYCONNECTED
X=Flatten()(X)
X=Dense(units=classes,activation='softmax',name='fc'+str(classes),kernel_initializer=glorot_uniform(seed=0))(X)
#create model
model=Model(inputs=X_input,outputs=X,name='ResNet50')
return model
def test_identity_block():
with tf.Session() as sess:
np.random.seed(1)
A_prev=tf.placeholder('float',[3,4,4,6])
X=np.random.randn(3,4,4,6)
A=identity_block(A_prev,f=2,filters=[2,4,6],stage=1,block='a')
init=tf.global_variables_initializer()
sess.run(init)
out=sess.run([A],feed_dict={A_prev:X,K.learning_phase():0})
# print('out=',out[0][1][1][0])
def test_convolutional_block():
#tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
A_prev=tf.placeholder('float',[3,4,4,6])
X=np.random.randn(3,4,4,6)
A=convolutional_block(A_prev,f=2,filters=[2,4,6],stage=1,block='a',s=2)
init = tf.global_variables_initializer()
sess.run(init)
out=sess.run(A,feed_dict={A_prev:X})
print('out=',out[0][0][0])
def test_ResNet50():
#定义好模型结构
Resnet50_model=ResNet50(input_shape=(64,64,3),classes=6)
#选定训练参数
Resnet50_model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
#获取训练集和测试集
train_x, train_y, test_x, test_y=convert_data()
#训练集上训练
start_time=time.time()
print('============开始训练===============')
Resnet50_model.fit(x=train_x,y=train_y,batch_size=32,epochs=2)
end_time=time.time()
print('train_time={}'.format(end_time-start_time))
#测试集上测试
preds=Resnet50_model.evaluate(x=test_x,y=test_y,batch_size=32,)
print('loss={}'.format(preds[0]))
print('Test Accuracy={}'.format(preds[1]))
if __name__=='__main__':
#test_identity_block()
#test_convolutional_block()
#convert_data()
test_ResNet50()
打印结果:

其中问号代表的是样本数,可看出最终卷积输出是1×1×2048

训练样本为1080个,第一个Epoch每个样本时间为175ms,所以共189s.第一次epoch训练精度为0.27。

第二个Epoch每个样本时间为165ms,所以共178s.训练两次epoch时间为376S,不等于两次epoch时间之和,应该是有别的开支。第二次epoch训练精度为0.40提高了。
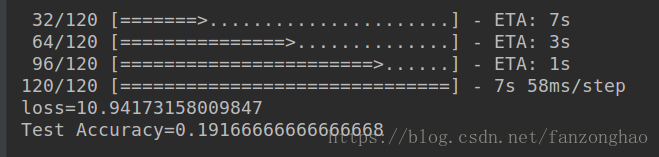
经过两次epoch的模型来测试120个样本,测试精度为0.19,恩很低,所以还要多训练嘛。